
右から左に書く言語を支える技術

みなさん、こんにちは。以前絵文字についてnoteを書いたところ、思いのほか多くの方に読んでいただいたので、二匹目のどじょうを狙って書いてみることにしました。今回のトピックは右から左に書く言語、いわゆるRTL(Right-to-Left)の環境のお話をしようと思います。なお、私はRTLの言語を一個も読み書きできません。アラビア語もペルシャ語もヘブライ語もわかりません。過去にエジプトに旅行に行ったことがあるのですが、スマホがまだなかった当時、地球の歩き方を片手に旅行しましたが、バスやバス停で何が書いてあるかわからず、バスに乗ることすらできませんでした。今も当時と大して変わらないので、いまだにバスには乗れないかもしれません。そんな筆者が書いた文章なので、この記事を読んだところでアラビア語が読めるようになったりはしません。ではこの文章を読むと何が理解できるのか?それはRTL言語の仕組みを理解でき、RTL言語を正しくアプリケーションで表示するための基礎知識が得られる、くらいかとおもいます。ですので、「アラビア語を読めるようになろう!」というよりは、「アラビア語を表示するためにソフトウェアがやっていることを理解しよう!」というゴールのもと読んでいただけるとうれしいです。絵文字のように「今目の前で使われている技術!」みたいな即効性のある文章ではありませんが、現代のOSの内側を知るという知的好奇心を満たしたり、もしくはこれからアプリケーションをRTLサポートするというときの導入になれればと思っています。
また、今回は前回の絵文字にもまして超ボリューミーな記事となっています。3万字超えてます。ですので適当につまみ食いしていただけるだけでも嬉しいです。BiDiアルゴリズムに興味がなくても「BiDiヤバイ話」だけでも読んでいただけたら「BiDiヤベぇ」ってなっていただけると思います。
序文の最後にDisclaimerですが、これから書く記事は、Androidのオープンソースプロジェクトである、AOSPの実装およびソースコードをもとに書いています。OSによって挙動が違うことがあるかもしれませんので、この記事ではAndroidのことを説明していると思って読んでください。また、このブログはAndroid 14の挙動に即して書いています。様々な理由で挙動は今後変わる可能性もありますので、あくまでも現時点での挙動や実装だと思って読んでいただけたらと思います。そしてお約束ですが、この記事は私の所属する組織とは何ら関係がなく、ここでの意見は私個人のものであり、所属するいかなるものを代表するものではありません。私的な見解以外の部分はすべて公式の公開情報をもとに書いています。
では始めていきましょう。
RTL言語とUI
まずは、みなさんにRTL言語がどんなものなのかを理解してもらうべく、RTLの方々の使うUIについて説明していきます。まず「右から左に書く言語」と言いましたが、これは「書く」に限ったものではありません。思考の流れとでも言いますか、RTL言語の人々は、ものごとは右から左に流れていると考えます。例えば、我々日本人が画面をデザインするとき、優先度の高いものや使用頻度の高いものを左に配置しますよね。例えば、某SNSアプリは左側に重要なアイコンを配置していますし、OSのアプリ一覧は左から右にソートされています。


このように、我々LTR言語圏の人たちが無意識のうちに「左から右に」と順序や流れを考えています。これと同じことがRTL言語圏の人たちにも起こっているのですが、その流れる方向が逆になっていると思ってください。ですので、RTL言語の方々向けの画面を設計すると、某SNSのアイコンは重要なものを右に、アプリ一覧は右から左にソートします。ちょうと鏡写しのようなUIになります。


私は言語学者や心理学者ではないので、本当に彼らがそのような思考をしているのかはわかりません。ですが少なくとも私が今までUIを設計する時の経験から見ると、RTL言語圏の方々はそのような思考をしているように見えます。
ただし、すべてを反転すれば良いというわけではなく、ものによってはLTR言語圏と同じUIを使っているものもあります。代表的なものでいうと、音楽等の再生ボタンです。通常は時間の経過などを描写するアイコン等は、RTLでは反転させる必要があります。しかし音楽等の再生ボタンはRTL環境でも右向きの矢印です。これはカセット時代の磁気テープの巻き取りの方向からきているので、RTLでも左から右なんだそうです。

結局のところ、非ネイティブには判断がつかなかったり、例外があったりするので、迷ったら調べるか、ネイティブな人に確認するのは必須ですね。
さて今まで見てきたのはUIでした。ここからはそのUI上で表示される文章を見ていきましょう。このようなRTL言語圏の人たちの文章は、右から左に書きます。本当に右から左に書くだけだったら、RTLのUI設計と同じ程度の複雑さだったかもしれません。ですが実際はRTLの文章をサポートするのはUI設計より遥かに難しい問題を含んでいます。その最たるものが、「異なる方向の文章が混ざっていても良い」という点です。我々が日本語の文章を書くときに、英語の単語を引用して直接書いたりします。歌の歌詞だと一部が英語になっているのは珍しくないですよね。それと同じことがアラビア語などにも起こり得ます。日本語に英語が入る場合は、文章の方向が同じなので自然に混ぜられますし、混ぜても読めてしまいます。しかし例えば、アラビア語の文章の中に日本語が入っている場合、アラビア語は右から左に、日本語は左から右に読む必要があります。このような文章はBiDi Text (Bi-Directionality Text 双方向テキスト)または単にBiDiと呼ばれています。ちょっと考えただけでも超複雑な気がしませんか?でも安心(?)してください、Unicodeはこれを解決する方法を標準化しています。次の章ではこの内容を詳しく見ていきます。ちなみに、「RTL言語だけの文章、例えばアラビア語だけの文章だったらBiDiいらないんじゃね?」って思ったそこのあなた。残念ながらほとんどのRTL言語ではBiDiのサポートが必要になります。なぜならRTL言語だけの文章でも、数字はLTRで書くことがほとんどなので、RTL言語のサポートとは実質BiDiのサポートにほかなりません。
余談ですが、このRTL言語を話す人々は世界にどれくらいいると思いますか? Wikipediaによると人口が多い言語、上位27言語のうちRTL言語は、エジプトアラビア語、ウルドゥ語、パンジャブ語、ペルシャ語で、その合計は約2.7億人です。このWikipediaではエジプトのアラビア語と細かく分類されてますが、地域を限定しないならアラビア語だけで3億人以上のネイティブスピーカーがいます。いずれにしても日本語なんかダブルスコアで負ける程度にはRTLは世界中で使われています。ですので、現代のOSにおいてBiDiのサポートは必須になっています。
BiDiの概要
UnicodeがBiDiを正しく表示するために策定したものはBiDiアルゴリズムと呼
ばれ、UAX#9にそのすべてが載っています。
この文章を読めばBiDiアルゴリズムを実装できるのですが、いきなりこの文章を最初から読むのはハードルが高いでしょうし、BiDiアルゴリズムを自力で実装しようとする人はあまりいないでしょう。なによりそのまま読んでても退屈だと思います。ですので、この記事ではあくまで簡単な理解ができることを目的として、BiDiの概要、簡単なBiDiアルゴリズムの説明、そして最後にBiDi環境で起こる厄介な問題たち(BiDiヤバイ話)について見ていくことにします。
ではBiDiを見ていく前に、RTLについて説明します。以下のLTR言語とRTL言語の例を見てみましょう。


一つ目の例は英語(LTR)の文章です。見慣れた左から右に文章が進んでいますね。二つ目の例はヘブライ語(RTL)の文章です。文章が右端で揃っており、文章は右から左に進んでいます。ここで「右から左に書く」とは、単に文章を「右揃え」しているわけではありません。詳しく見ていきましょう。通常、我々LTR言語圏の人が文章を書くときは、「左から書きはじめて左端を揃える」ように文章を書きます。この「左から書き始める」をもっと掘り下げていくと、一文字目が最も左にあり、二文字目はその右隣に配置され、テキストは右方向に伸びていきます。他方でRTL言語は「右から書き始める」言語です。一文字目が最も右にあり、二文字目はその左隣に配置され、テキストは左方向に伸びていきます。

ですので、もしRTL言語の文章を「左から書きはじめて、右端に揃える」としてしまうと、まったく読めない文章が表示されてしまいます。どのように壊れるのかを見るのに、逆に日本語を「右から書き始めて、左端に揃える」をしてみましょう。例えば「本日は晴天なり」という文章を右から書き始めて左揃えにすると、以下のように「りな天晴は日本」と表示されてしまいます。これと同じことがRTLな文を左から書くと起こってしまいます。ですのでRTLな文を書くときは必ず、右端に最初の文字を書いて順に左へ文章を伸ばしていかなくてはなりません。

ところで、言語によって右揃えか左揃えかを切り替えないといけないのは不便ですので、Androidでは左揃えや右揃えというオプションの代わりに、「開始位置揃え」と「終端位置揃え」のオプションがあります。これらはUIの方向によって左揃えか右揃えかを切り替えます。例えば、開始位置揃えはLTRの環境では左揃え、RTL環境では右揃えとなります。

さて、RTLの書き方が分かったところで、本題のBiDiへと入っていきます。BiDiとは前章で軽く説明をしましたが、Bi-Directionality テキスト(双方向テキスト)のことです。すなわちLTR(左から右)とRTL(右から左)が入り混じった文章のことを言います。アラビア語の中で日本語を引用している文章はBiDiですし、逆に日本語の中でアラビア語を引用している文章もBiDiとなります。また先程も書きましたが、数字は多くのRTL言語でもLTRで書くので、RTL言語をサポートすることはすなわちBiDiをサポートすることになります。ではBiDiの例を見てみましょう。


一個目の例はLTR(英語)の文章の中にRTL(ヘブライ語)が挿入されている例を示しており、二個目の例はRTL(ヘブライ語)の文章の中にLTR(英語)が挿入されている例を示しています。これらの例を見てみるとわかるように、LTRとRTLが入り乱れた文章でも、各言語はその方向で、つまりヘブライ語はRTLで、英語はLTRで描画されています。具体的には、ヘブライ語の中でも「English」は「hsilgnE」とは書かれません。BiDiアルゴリズムとは、このように与えられた文字列を、LTRとRTLの場所を把握して、それぞれを正しい順番と正しい方向に並び替えるためのアルゴリズムです。
BiDiアルゴリズムの解説そのまえに
BiDiアルゴリズムの目的は、様々な言語が入り乱れた文章において、文字をただしい順番と方向に並び替えるためのアルゴリズムです。ここからはUnicodeが実際にそのような文章を期待通りに表示できるように、どのようなルールで文字を描画しているのかを見ていきます。
では早速BiDiアルゴリズムの解説に入りたい・・・のですが、その前にいくつか説明しておかなければいけないことがあります。この章ではBiDiアルゴリズムの中身を理解するために、あるいはライブラリなどを通してBiDiアルゴリズムを使用するのに必要な知識を4つほど解説します。
文字には方向がある
まず最初に、文字には方向があります。Unicodeはすべての文字に方向の属性を割り振っています。アルファベットは左、アラビア文字は右のような感じです。ですが、これは単純な左右といった方向ではなく、4カテゴリ23個もの方向(BiDi Character Type)を割り振っています。全部解説しても仕方ないので代表的なものを見ていきます。

Strongカテゴリには大きくStrong LTRとStrong RTLがあります。これらはStrong(強い)とついているだけあって、文字単体で方向が決まり、よほどのことがない限りこの文字の方向が変わることはありません。英語のアルファベットや日本語の文字はStrong LTRで、アラビア語やヘブライ語の文字はStrong RTLです。
説明の都合で先にNeutralを説明します。Neutralは「その文字自体は方向を持っておらず、周りの文字を見て自分の方向を決める」という風見鶏のような文字です。空白文字や絵文字なんかがわかりやすいですね。LTRの文字列中に空白があればLTR文字として扱い、RTLの文字列中に空白があれば、その空白はRTLとして扱っています。空白が他のNeutralとは別のタイプが割り当てられていますが、厳密なアルゴリズムの手順では異なる手続きになっているからです。この記事内では大体同じ挙動をすると思っていただいて大丈夫です。
Weakはほぼ数字です。数字は「大体はLTRとして動作する」と思っていただいて大丈夫です。Strong LTRとの大きな違いは、数字で挟んでもNeutralなカテゴリのものはLTRにならず、Neutralのままになるということです。数字は多くのRTL言語でもLTRで書くことが多いため、実質的にRTLサポートがBiDiサポートとなっている原因です。ちなみにですが、すべての数字がWeakカテゴリにあるわけではなく、タイ語やヒンディ語などの数字はStrong LTRであり、ンコ(N’Ko)語やアドラム語の数字はStrong RTLです。むしろ逆にアラビア数字とインド数字だけがWeakで、ほかはLTRか、超まれにRTLだと思っていただいて大丈夫です。
最後にExplicit Formattingカテゴリですが、これはBiDi用の制御文字のカテゴリです。各々の動作はもう少しアルゴリズムの詳細を話さないと説明できないのでここでは、「なんかLTRとRTLを制御する文字がある」程度の認識で大丈夫です。
パラグラフにも方向がある
次に、BiDiアルゴリズムには基本となる方向の概念が必要になります。ざっくり言うと「この文章が書かれた環境はどっち向きなの?」という方向です。「Base Direction (基本方向)」とか「Paragraph Direction(パラグラフの方向)」とか「Context Direction(コンテキストの方向)」とか色々呼ばれています。この記事では呼び方はパラグラフ方向で統一します。これはBiDiアルゴリズムの外から与えられる情報で、Unicodeのスペックでは標準的な方法は書いてあるものの「とはいえ、なんか適当な方法で決めてね」って丸投げしています。なので、何らかの形で決めてあげる必要があるのです。これを決定するときに最もわかりやすいシグナルとなるのが、「ユーザーの言語設定」でしょう。ユーザーが日本語を設定していたら、パラグラフの方向はLTR。もしユーザーがアラビア語を設定していたらパラグラフの方向はRTLでよさそうです。ですが、状況によってはユーザーの言語設定を無視して独自に設定する必要があるかもしれません。例えば翻訳アプリのように複数の言語を同時に表示する場合、日本語入力欄はLTRだけれども、翻訳結果欄はRTLにしたい、みたいなこともあるでしょう。各UIライブラリにはコンポーネントのパラグラフ方向を適宜変更することができるAPIが用意されているはずです。AndroidではtextDirection=”rtl”とすると、LTRの言語設定のデバイスでもパラグラフの方向をRTLにすることができます。HTMLならば、pタグなりtextareaタグなりに、dir=”rtl”という属性をつけることでパラグラフの方向をRTLにすることができます。
論理順と表示順
次に、今後使用していく二種類の文字の並び順を紹介します。論理順(Logical Order)と表示順(Visual Order)です。論理順とは、メモリ上に格納されている順番のことを言います。プログラム的には、String.getCharAt()で取得できる文字の順番のことです。表示順とは、それを画面上に表示させたときの順番のことを言います。
LTRのみの文章の場合は論理順と表示順は一致します。

逆にRTLのみの文章の場合、表示順は論理順の逆順になります。
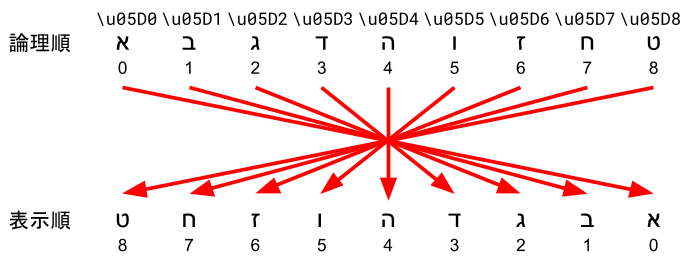
そしてBiDiテキストの場合は、より複雑なことになります。

この用語を用いると、BiDiアルゴリズムは究極的には「論理順で与えられた文字列を表示順に並び替えるアルゴリズム」と言うことができます。こう書くとすごく当たり前のアルゴリズムですね。
BiDi Runとは
もうひとつ用語の説明です。BiDiアルゴリズムはその中間生成物としてDirectionality Run(方向ラン)やBiDi Run(BiDiラン)というものを出力します。この記事ではBiDi Runで統一します。これは論理順のテキストを解析した結果、どこの領域がLTRでどこの領域がRTLなのかを表すためのものです。
もともとRunとはテキストの分野でよく使う用語なのですが、同じ属性を持つ部分文字列のことを言います。例えば、同じスタイル(色や文字サイズなど)の部分文字列をStyle Runと呼んだり、同じフォントで描画する部分文字列のことをFont Runと呼んだり、同じ文字種の部分文字列をScript Runと呼んだりします。ここでは同じ方向を向いている部分文字列のことをBiDi Runと呼んでいます。
BiDi Runは文字列の範囲(Range)とその範囲のレベルのペアで成り立っています。レベルを説明するにはBiDiアルゴリズムの中身を説明しないといけないので、ここでは「単純な左右よりももうちょっと詳しい情報」と思っていてください。もしBiDi RunがLTRなのかRTLなのかを判定したければ、そのレベルの値が偶数か奇数かを見れば良いです。例えば以下のBiDiの例でのBiDi Runは以下のようになります。

今のところは、なぜRun[0]のLevelが0なのかとか、Run[1]のLevelが1なのかとかは置いておいてください。BiDiアルゴリズムが計算した結果、0や1になったと思ってください。
BiDi Runは以下のような特性を持ちます。
・BiDi Runは網羅的です。つまり、すべての文字はどこかのBiDi Runに属します。
・レベルの値が偶数のRunはLTRであり、レベルの値が奇数のRunはRTLです。
・レベルの取りうる値は0から126までです。
さて、これでBiDiアルゴリズムを取り扱う準備が整いました。それでは次章でその中身を解説していきます。
簡易版BiDiアルゴリズムの解説
さて、前章でBiDiアルゴリズムを理解する上で基本となる事項を見てきました。前章の内容だけでBiDiアルゴリズムをライブラリなどで使うときに困ることはないでしょう。ですが、さらなる理解を深めてもらうために、これからBiDiアルゴリズムがなにをやっているのかを解説していきます。BiDiアルゴリズムの内部はかなり複雑なので、BiDiアルゴリズムの中身に興味がなく、実際の使い方が知りたい方や、BiDiヤバイ話に興味がある方はこの章をスキップしていただいて大丈夫です。
それでは警告(?)もできたと思いますのでBiDiアルゴリズムの内容に入っていきましょう。前に見たようにBiDiアルゴリズムはほぼUAX#9にかかれています。ですがUAX#9はアルゴリズムを実装する人向けに書かれているので、手続き的な内容に終始しています。ですので、この記事では具体例を多めに、アルゴリズムの手順というよりは、視覚的になにが行われているかを中心に説明していきたいと思います。ですのでエッジケースなどを省略したり、間違いにならない程度に独自の説明を加えています。もしあなたが完全なアルゴリズムを知りたかったり、細かい挙動で疑問に思った場合はUAX#9を参照してください。
さて、ではこれからBiDiアルゴリズムを見ていきましょう。と言いたいのですがもう一つだけ注意事項があります。これからRTLの言語とLTRの言語が入り乱れた文で説明をしていくのですが、いかんせん私はRTL言語をこれっぽっちも書けません。よしんばAIの力を借りて書けたとして、例えばヘブライ語と日本語が入り混じった文で説明しても読むのに苦労すると思います。というか私も翻訳機を片手に読み返したくないです。なのでちょっと説明に工夫を入れたいと思います。ここでは本物のRTL言語を使うのではなく、英語を代わりに使いたいと思います。具体的には、説明の中にアルファベットで書かれたものが例として出されていたら、それは本来はRTL言語の文が入る場所ということです。例えば、論理順で「I have a りんご.」という日本語と英語混じりの文章は、本来はヘブライ語と日本語の混ざった文章だと思ってください。また、例えば「I have an apple」という文をRTL言語だと思って表示順に並べたとき「.elppa na evah I」となってしまいますが、これも意図的なもので、右からアルファベットを読んで読める英語であれば、正しく並べ替えられていると思ってください。この説明方法が良いのかは正直わかりません。でも今回はこの説明でチャレンジさせてください。今後他に良い方法が思いついたら別の解説記事を出すかもしれません。
それでは恐ろしく前置きが長くなりましたが、BiDiアルゴリズムの中身を見ていきましょう。BiDiアルゴリズムは大きく2つのステップに分かれています。今回はさらに最初のStep1を2つのサブステップに分けて説明していきます。
Step 1. 与えられた文字列からBiDi Runを計算する
Step 1-a. 与えられた文字列の文字の方向を左向きか右向きにする
Step 1-b. 与えられた文字列の埋め込み関係を分析してBiDi Runにする
Step 2. 計算されたBiDi Runを並び替えて表示順を計算する
それぞれ見ていきましょう。
Step 1-a. 各文字の方向を左向きか右向きにする
BiDiアルゴリズムの第一歩は、先程みた4カテゴリ23種もある文字の方向属性を、左向き(Lと表記)か右向き(Rと表記)かに分類するところから始まります。例えばNeutralカテゴリの文字(Nと表記)は、その周りがLTRだったら左、その周りがRTLだったら右、のような挙動をします。例えば「I have an appleと彼は言った。」のような文章は最終的には「RRRRRRRRRRRRRRRLLLLLLL」となります。

このステップでNに限らず、LとR以外のすべての文字種をLかRに変換します。UAX#9には各カテゴリの文字種がそのコンテキストでどのようにLかRに変わっていくかのリストが書いてあります。厳密にはUAX#9にかかれている手続きでは、LとRだけが残るのではなく、アラビア数字とインド数字を含めた合計4種類になるまで処理が行われます。数字がここで解決されないのは、ちょっと特殊な処理をやる必要があるので別枠扱いになっています。ただ、挙動としては最終的にはLのような挙動をするので、ざっくりとした理解をする上では数字もLになると思って大丈夫です。
Step 1-b. 与えられた文字列の埋め込み関係を分析してBiDi Runにする
文字列がLかRになったら、次はBiDiアルゴリズムの最も重要なステップである埋め込み(Embedding)の処理に移ります。BiDiアルゴリズムにおける埋め込みとは、「現在の文章の方向とは逆の方向の文章を書く」ことです。具体的には「現在の文章の方向がLTRのときにRTLを書く」、あるいは「現在の文章の方向がRTLのときにLTRの文章を書く」という意味です。ここでいう「現在の文章の方向」とは、周囲の文章の方向のことを言い、何も文章がない場合はパラグラフの方向のことを言います。例えば言語設定が日本語の端末に、ヘブライ語を書こうとするケースを考えてみます。このとき、たとえ書かれている文章がヘブライ文字だけだったとしても、その文章自体がLTRの方向に埋め込まれたRTLの文章ということになります。もちろん逆も同様です。例えば言語設定がヘブライ語の端末に日本語を書こうとするケースを考えてみます。この場合も、たとえ書かれている文章が日本語だけだったとしても、その文章自体がRTLの方向に埋め込まれたLTRの文章となります。なお、BiDiアルゴリズムは文章の方向だけを考えるので、日本語の環境の中に英語が引用されていたとしても、両方LTRなので埋め込み関係にあるとはみなされません。(ただしこの章限定で、説明の都合上、英語はRTLの代用をしているので、埋め込み扱いになります。)

文章の「埋め込み」が何となくわかったところで、さらに発展的なことを考えます。この埋め込み構造は繰り返し適用できます。例えばRTLの文章の中に、「LTRの文章の中にRTLを書いた文章」を書くことができます。「アラビア語の文章の中に、ヘブライ語を引用した日本語を書く」みたいな感じです。このように再帰的に埋め込みは発生していきます。この「どれくらい埋め込まれているのか?」という概念もBiDiアルゴリズムでは並び替えるのに必要です。BiDiアルゴリズムではこれをEmbedded Level(埋め込みレベル、または単にレベル)と言い、BiDi Runのパラメータになっています。
では例として論理順で「彼はI have a penと言った」という文章を考えます。今パラグラフの方向はLTRだとしましょう。今は説明の都合上英語はRTLであることに注意してください。このとき、「I have a pen.」というRTLの文章は「彼は〜と言った」というメインのLTRの文章に埋め込まれています。このとき「I have a pen.」は周りの文より埋め込みレベルが1高いと表現します。埋め込みレベルの数え上げは、パラグラフの向きがLTRのならば0、パラグラフの向きがRTLなら1からはじまります。ですので、パラグラフの埋め込みレベルと同じレベルにある「彼は〜と言った」という文章は埋め込みは発生せず、レベルは0。そしてそれより一つ深く埋め込まれた「I have a pen.」というRTLの文章は埋め込みレベルは1となります。

ではさらに、この「彼はI have a penと言った」という文章自体を別の文章に埋め込むことを考えてみましょう。例えば、「She said 〜」というRTLの文章に埋め込んでみましょう。「She said彼はI have a penと言った」という文章ができあがります。これも同様に埋め込みレベルを考えることができます。

今、パラグラフ方向がLTRなので、最も低いレベルは0です。ですので「She said 〜 」というRTL文章はLTRに埋め込まれたRTL文章と考えるので、「She said 〜」は一段深いレベル1となります。そしてそのレベル1の環境に埋め込まれている「彼はI have a penと言った」というLTR文章はレベル2となります。そしてそのレベル2の環境に埋め込まれている「I have a pen」というRTL文章はレベル3となります。こうしてみてみると気づくことがあると思います。偶数レベルはLTR、奇数レベルはRTLになっていますね。これは埋め込みレベルというハイレベルな情報から、「ここの文章はRTL?LTR?」という情報を取るときに便利です。単に偶数奇数判定をすればよいだけです。
念の為、もう一段階埋め込んでおきましょうか。例えば「太郎は〜と思った」という文に埋め込んでみましょう。「太郎はShe said彼はI have a penと言ったと思った。」となります。もはや何を言っているのか意味不明ですが、この文章の埋め込みの関係と各レベルはこのようになります。
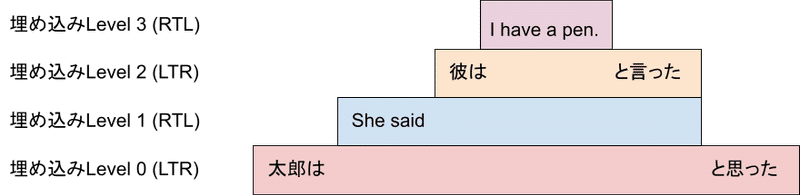
さて、埋め込みレベルの概念についてはなんとなく理解できたかと思います。ところで、今自然とこのような構造を我々は作ってきましたが、このような文章の埋め込み関係をプログラムで作れるのでしょうか?AIとかなら話は別でしょうが、BiDiアルゴリズムは文脈を理解しません。基本的に今使える情報は「パラグラフの方向」と「この文字はLかRです」という文字の種別の情報だけです。具体的に見ていきましょう。先程みた「太郎はShe said彼はI have a pen.と言ったと思った」という文章の各文字の方向は以下のようになります。
文章:太郎はShe said彼はI have a pen.と言ったと思った。
文字の方向:LLLRRRRRRRRLLRRRRRRRRRRRRRLLLLLLLLL
さて、この文字種別の情報から埋め込み構造を解決できるでしょうか?ここで例えば別の例「太郎はpenとappleを持っている。」という文を考えてみましょう。
文章:太郎はpenとappleを持っている。
文字の方向:LLLRRRLRRRRRLLLLLL
方向だけの情報だと論理順でL→R→L→R→Lと遷移する構造は似ていますが、これの文脈上の埋め込み構造は「太郎は〜と〜を持っている」という文に「pen」と「apple」が埋め込まれている構造です。

先程のLevelが3まで存在するような複雑な文章とはまったく異なる構造になっているのがわかりますね。我々は文章のハイレベルな意味を理解しているので、埋め込み構造を構築できますが、原始的な文字の方向の情報からだけではこのような埋め込み構造を構築することはできません。ですので何らかの情報を付加して埋め込み構造をBiDiアルゴリズムに教えてあげる必要があります。なお、仮にAIなどを駆使して埋め込み構造を解析できたとしてもBiDiアルゴリズムような低いレイヤーでは行うべきではないでしょう。もしAIなどでハイレベルな埋め込み情報を取得できたなら、後述する方法で埋め込み関係を指定してあげるのが良いでしょう。
では、具体的にBiDiアルゴリズムが、どのようにして埋め込みを処理しているのかを見ていきます。まずはなんの情報もないケースから考えていきます。UAX#9のアルゴリズムを文章の構造に落とすと、以下のような処理をしていることになります。
文章を読んでいって、現在の文章の方向と逆の文章に出くわしたら埋め込みが発生したとする。その後、もとの方向に戻ってきたら埋め込みが終了したとする。
これの挙動をまずは「太郎はpenとappleを持っている」という簡単な例をパラグラフ方向はLTRという条件で見ていきます。この例では、まずはパラグラフの方向と同じ「太郎は」という文が来ます。これは同じ方向なので埋め込みは発生しません。次に「pen」という文ですが、これはRTLであり、方向が変わったので埋め込みが発生しています。その次は「と」が来ます。ここで元の方向に復帰しましたので、この文の直前で埋め込みが終了しました。そしてさらに見ていくと「apple」というRTLの文が登場します。これは方向が変わっているので埋め込み。そして最後は「を持っている」という元の方向の文に出くわすので、この直前で埋め込みは終了です。

この方法だと再帰的な埋め込み構造ができないのがわかるかと思います。なぜなら例えばLTRからRTLに変わって埋め込みが発生した場合、次に方向が変わるのは必ずRTLからLTRだからで、それは埋め込みが終了することを意味するからです。この再帰的埋め込み構造を作らないアルゴリズムですが、実際はほとんどの場合うまく動作します。なぜなら埋め込みの入れ子になる文章を書くことは稀だからです。ですがそんな文章がまったくないというわけではないので、次はそんな文章が渡されたとき、このアルゴリズムがうまく埋め込みを処理してくれないことの例を見てみましょう。「彼女はHe has りんご in handだと言った」という文章でこのアルゴリズムの挙動を見ていきましょう。意味を理解できる我々は「He has りんごin hand」という文章が「彼女は〜だと言った」という文に埋め込まれていることを理解できます。ですが全くの情報がない状態ではBiDiアルゴリズムは以下のような挙動をしてしまいます。

先に見たように、文の方向が変わるタイミングで埋め込みの発生と終了を処理しているので、「He had」と「in hand」の2つの文が「彼女は〜りんご〜と言った」という文に埋め込まれていると解釈してしまいました。実際に期待される動作は以下のようになります。

「He had」と「りんご」の間の方向の遷移は埋め込みの終了ではなく、新たなRTL文中のLTR文の埋め込みの発生と解釈してもらいたいのです。ですので何らかの追加情報を渡して、再帰的な埋め込みの構造をBiDiアルゴリズムに教えてあげる必要があります。
BiDiアルゴリズムに埋め込み関係を指示するには、BiDiの制御文字を使って行います。BiDiの制御文字たちはいくつか種類があるのですが、ここでは最も使う機会の多いであろう「LRE」と「RLE」そして「PDF」を説明します。LREとはLeft-to-Right Embedding(LTRの埋め込み)の略であり、RLEは逆にRight-to-Left Embedding(RTLの埋め込み)の略でPDFはPop Directional Formatting(方向書式の削除)の略です。意味としてはLREはPDFと一緒に使って「これからPDF文字が現れるまでがLTRの埋め込みです」という意味で、RLEは「これからPDF文字が現れるまでがRTLの埋め込みです」という意味になります。具体的なLRE、RLE、PDFのコードポイントはU+303A, U+303B, U+303Cですが、例の中では<LRE>, <RLE>, <PDF,>と表記します。実際にやっていきましょう。例として「彼女はHe has りんご in handだと言った。」という文章を考えます。なにもしないと以下のような入れ子構造になります。


これは先に見たように、BiDiアルゴリズムが「He had りんご in hand」という文が「彼女は〜と言った」という文章の埋め込みだとは思わずに、「He had」と「in hand」という文が「彼女は〜リンゴ〜と言った」という文に埋め込まれていると解釈したからです。ですので、「He had りんご in hand」という文章をRLEとPDFで囲ってあげます。そうすると、BiDiアルゴリズムは囲われた「He had りんご in hand」という文章がRTLの埋め込み文章だと解釈して埋め込みレベルを計算します。具体的には、「He had」から「りんご」への方向の遷移は、RTLから元のLTRへの復帰ではなく、埋め込まれているRTLの文章の中でLTRの埋め込みが発生しているとされます。


もう一つだけ例を見ておきましょう。今度は「太郎はpenとappleを持っている」という文章をパラグラフ方向がRTLであるような環境での埋め込み関係を見てみましょう。パラグラフの方向がRTLなので、最初のLTRの文「太郎は」はいきなり埋め込みです。そして、「pen」の直前で元のパラグラフの方向に復帰して、埋め込みが終了します。これでは「太郎は」と「と」と「を持っている」という文が、「〜pen〜apple〜」という文に埋め込まれているという扱いになってしまいます。


以前みたようなパラグラフがLTRのときと同じ埋め込み関係を、パラグラフがRTLのときにも構築するにはどうすればよいでしょうか?答えは全文をまるごと<LRE>...<PDF>で囲って埋め込んでしまうことです。


このように、LRE、RLE、PDFをつかってBiDiアルゴリズムに正しい埋め込み関係を教えることができました。
他のBiDi制御文字もあるのですが、それはまた別の機会に説明したいと思います。興味がある方はUAX#9を参照してください。
さて無事に埋め込みレベルの解決ができました。後はレベルの値が変わる場所がBiDi Runの切れ目なので、BiDi Runを埋め込み関係から簡単に構築できます。

Step 2. 埋め込まれた文章を並び替える。
お疲れ様でした。無事にBiDi Runが計算できました。後は機械的にあるステップを繰り返していけば目的の表示順を得ることができます。ですがそのステップに行く前に、埋め込みの正しい表示順について考えてみたいと思います。あるBiDiの文章が与えられて、その表示が正しいのか正しくないのかを判断するにはどうしたらいいでしょうか?一義的にはLTRの言語とRTLの言語の両方を理解できるネイティブが読んだときに読める文章が正しいとなるのでしょう。ただし、それだとネイティブではない我々では正しさを理解できません。ですので、ここではRTL文を理解できない我々でも理解できる「埋め込まれた文章の表示順の正しさ」について考えてみましょう。私はこの正しさを「埋め込み文の表示順の一貫性」と理解しています。「埋め込み文の表示順の一貫性」とは、埋め込もうとしている文が、埋め込む前の期待される表示順のまま、埋め込んだ文全体の一部として表示しているものであるとします。例えば、「彼はpenと言った」という文章を「She believe」という英語に埋め込むことを考えましょう。「彼はpenと言った」という文章のパラグラフがLTRでの表示順は「彼はnepと言った」という形になります(なぜこうなるのかは後々見ていきます)。ここでの一貫性とは、この文章がたとえ「She believe」というRTLの文に埋め込まれたとしても、たとえパラグラフがRTLの環境に埋め込まれたとしても、この「彼はnepと言った」という順番が保持されていることを言います。

具体的にどのように並び替えられるのかについてはこれから見ていきますが、「彼はnepと言った」という文章がパラグラフがRTLの環境で「She believe」というRTLの文に埋め込まれた場合、表示順が「彼はnepと言った」ではなく「と言ったnep彼は」になりました。これを「埋め込みが一貫していない」ので、正しくない並び順だとします。そしてこれは往々にして正しくない埋め込み構造を作ってしまったことに原因があります。これからBiDiアルゴリズムがどのように埋め込みレベルから表示順に変換していくかを見ていきますが、埋め込み関係が間違っているために、意図しない、正しくない表示順を出力してしまうことがあります。そんなときは文章の書き手である人間が、制御文字等を使って修正しないといけません。このとき正しい表示順なのか正しくない表示順なのかに迷ったら、この「埋め込み後も表示順が壊れない」という原則に立ち返って考えてみてみてください。
では具体的な表示順への変換方法を見ていきます。表示順を取得するためには以下のステップを繰り返します。
並べ替えStep 1. 最も高いレベルのBiDi Runを反転させてひとつ下のレベルの文章として合流させる
並べ替えStep 2. 反転Step 1を最大レベルが0になるまで繰り返す
まずはシンプルな例として「太郎はpenとappleを持っている。」という文章を見てみます。

ここで最も高いレベルは1なので、その埋め込まれた文章を反転させてひとつ下のレベルの文章に合流させます

この処理の後、最大レベルが0の文章だけが残りますので、これが期待されているBiDiの表示順となります。

ここでは英語をRTL言語だと見立てて説明をしているので、変に見えるかもしれませんが、これが期待される表示順です。この文章の方向と読む順番は以下のようになります。

もう少し複雑な例を見ていきましょう。「彼女はHe had リンゴ in hand と言った」という文章を例に反転の様子を見てみましょう。

この埋め込み関係を作るには「He had リンゴ in hand」を<RLE>...<PDF>で囲う必要があるのですが、ここでは省略しています。この例の場合最もレベルの高い埋め込み部分は「リンゴ」ですので、これを反転させてひとつ下のレベルの文章に合流させます。

次に高いレベルの文章はLevel1ですので同じように、反転させてひとつ下のレベルの文章に合流させます。

そして最終的にすべてを埋め込まれたLevel 0のものが残ります。それが期待されるBiDiテキストの表示順です。

この文章の方向と読む順番は以下のとおりです。

ほんまかいな?って思いますよね。でもこれが正しい順番です。なぜなら、埋め込まれた文章「He had リンゴ in hand」のRTL環境下での表示順は「dnah ni リンゴ dah eH」ですが、まさにこの文がこの順序で埋め込まれているからです。ですので一貫性があり、これが正しい順序で埋め込まれているのです。
ではここからは正しくない埋め込みをしてしまった場合、どのような表示順が出力されるのかを見ていきます。まずは「彼女はHe had リンゴ in handと言った」という文章を<RTL>...<PDF>で囲わなかったがために、以下のような埋め込み関係であるとしてしまった場合どうなるかを見てみましょう。

これは先に見たのと同じようにまずはLevel1を処理します。

そしてLevel0だけが残るので、期待される表示順と読む順番は以下のようになります。

先程の結果とはだいぶ違う順番で出力されました。これは入れ子関係が正しく解消されなかった結果「He had リンゴ in hand」という文章が期待される表示順「dnah ni リンゴ dah eH」で埋め込まれていません。ですので正しくない表示順です。再帰的な埋め込み構造になる場合は、LREやRLEで埋め込み関係を明示的に指定してあげる必要があるのですね。もっと盛大に壊れる例をもう一つ見ていきましょう。Step 1-bのときに見た「太郎はpenとappleを持っている。」という文を<LRE>...<PDF>で囲わなかった場合、パラグラフ方向がRTLのときの表示順を見てみましょう。この<LRE>...<PDF>が無いときの埋め込み関係は以下のようでした。

では、これに並び替えのアルゴリズムを適用してみましょう。

注意すべき点としては、反転ステップは、たとえパラグラフの方向がRTLで最低のレベルが1だったとしても、レベル0まで行われます。そうすることで偶数レベルのRunは偶数回反転されて論理順と同じ順序になり、奇数レベルのRunは奇数回反転されて論理順とは逆の順序になります。

さて、結果が得られました。この文章の読む順番は、以下のようになります。

これだと日本語だけしかわからなくても違和感を持ってもらえるかと思います。日本語の文章としての構造である「太郎は〜と〜を持っている」がこの並び順では全く見えてきません。なのでこの並び順では日本語として理解することが困難です。
BiDi アルゴリズムまとめ
これで表示順を得ることができました。ここまでで概ねBiDiアルゴリズムが何をやっているのかを説明できたとは思います。ですが長々と説明してきたので、ここでBiDiアルゴリズムの概要をまとめてみようと思います。BiDiアルゴリズムとは、まずLTRとRTLの埋め込み関係を、埋め込みレベルという形で計算し、次にそれをもとに表示順に並び替えるアルゴリズムでした。この埋め込みレベルを計算するとき、埋め込みが入れ子構造になっていた場合は、制御文字で明示的な埋め込みをBiDiアルゴリズムに教えてあげる必要がありました。さもないと最終的な表示順は期待した並び順で埋め込まれず正しくない順番で埋め込まれてしまうでしょう。
BiDiアルゴリズムは他にも説明していない制御文字や、カッコの対応付けなどの細かいルールがあります。ですがそれらは埋め込みレベルを操作しているに過ぎないので、大きな流れを理解する上では今回の内容で十分かなと思います。もっと細かく、厳密なルールを知りたい方はUAX#9を参照してください。
BiDiを実際に使ってみよう
この章ではBiDiアルゴリズムを実際に使ってみましょう。BiDiのプログラムは基本的には書くことはないと思います。なぜならOSが提供している標準のリッチテキストコンポーネントはBiDiを処理してくれるはずだからです。ですので、この章で解説しているプログラムは主にデバッグ用だったり、何をしているかを理解する用途だと思ってください。BiDiのプログラムなんて書かないよという方はこの章をスキップされても大丈夫です。言語はKotlin JVMで、使用するクラスはjava.text.Bidiです。では見ていきましょう。
BiDiアルゴリズムは以下の2つのステップで計算を行っています。
Step 1. 与えられた文字列からBiDi Runを計算する
Step 2. 計算されたBiDi Runを並び替えて表示順を計算する
ライブラリもこのStepに沿って使います。このStep 1の計算はBidiクラスのインスタンスを生成したタイミングで計算が行われます。そしてその後Bidi.reorderVisually関数を呼び出すことでStep 2の並び替えを行うという流れになります。
以下にシンプルなBiDiテキストのBidi Runと表示順を表示するプログラムの例を示します。
import java.text.Bidi
fun main() {
val str = "abc\u05D0\u05D1\u05D2def" // (1)
// Step 1. 与えられた文字列のBiDi Runを計算する。
val bidi = Bidi(str, Bidi.DIRECTION_LEFT_TO_RIGHT) // (2)
// Bidi.reorderVisuallyはarrayを並べ替えるので、Bidi Runのarrayを作っている。
val runs = Array(bidi.runCount) { i ->
Pair(
bidi.getRunStart(i) until bidi.getRunLimit(i),
bidi.getRunLevel(i)
)
}
println("論理順: ${runs.joinToString()}")
// 今回はBidi Runごとに並び替えるので、各Runのレベルを保存したarrayを準備。
val levels = ByteArray(bidi.runCount) { i ->
bidi.getRunLevel(i).toByte()
}
// Step 2. 計算されたBiDi Runを表示順に並べ替える。
Bidi.reorderVisually(levels, 0, runs, 0, runs.size) // (3)
println("表示順: ${runs.joinToString()}")
}これを実行すると、以下のような結果が得られます。
$ kotlinc Main.kt && kotlin MainKt
論理順: (0..2, 0), (3..5, 1), (6..8, 0)
表示順: (0..2, 0), (3..5, 1), (6..8, 0)順に見ていきましょう。まず(1)の部分は入力文字列です。\u05D0, \u05D1, \u05D2はヘブライ語のアルファベットです。つまりこの入力は「LTR3文字、次にRTL3文字、そしてLTR3文字」の文字列です。なんの文字であるかは今は重要ではないので、今後は「LLLRRRLLL」のように表記します。
次に(2)の部分です。これがBiDiアルゴリズムのStep 1を計算する部分です。第一引数は計算対象の文字列でいいとして、問題は第二引数です。これはパラグラフの方向を与えます。この例ではパラグラフはLTR、つまり日本語のようなLTR言語の環境であるとBiDiアルゴリズムに伝えています。ここに渡せるのは以下の4つの値です。
DIRECTION_LEFT_TO_RIGHT:パラグラフの方向はLTRであるとBiDiアルゴリズムに伝えます。言語設定が日本語や英語などのときに使用します。
DIRECTION_RIGHT_TO_LEFT:パラグラフの方向はRTLであるとBiDiアルゴリズムに伝えます。言語設定がアラビア語やヘブライ語のときに使用します。
DIRECTION_DEFAULT_LEFT_TO_RIGHT:パラグラフの方向はテキストの内容で決まります。論理順で最初に現れた文字がLTRならLTR、最初に現れた文字がRTLならRTLになります。もしNeutralな文字しかない、もしくは空文字のときはLTRとして処理します。パラグラフの方向を文字列の内容で決めたいときに使います。
DIRECTION_DEFAULT_RIGHT_TO_LEFT:パラグラフの方向はテキストの内容で決まります。論理順で最初に現れた文字がLTRならLTR、最初に現れた文字がRTLならRTLになります。もしNeutralな文字しかない、もしくは空文字のときはRTLとして処理します。パラグラフの方向を文字列の内容で決めたいときに使います。
次に(3)の部分がBidiアルゴリズムのStep 2の部分、表示順への並び替えになります。Bidi.reorderVisuallyはstatic methodになっており、レベルと対応するオブジェクトのarrayを渡してあげれば並び替えてくれます。第一引数と第二引数がレベル値のarrayとその開始インデックス、第三引数と第四引数が並び替えるオブジェクトのarrayと開始インデックス。第五引数が並び替える対象の数になります。
ここで、出力結果を見てみましょう。
論理順の結果は、最初の3文字(Kotlinのrangeはinclusive-inclusiveに注意)はLevel 0 (LTR)、次の3文字がLevel 1(RTL)、そして次の3文字がLevel 0(LTR)であるとわかります。そしてそれを表示順に並べかえたものがその下に表示されています。全く同じ順で並んでいるので、この場合は左から順に3文字をLTR方向に、次の3文字はRTL方向に、最後の3文字はLTR方向に書けば良いことがわかります。この出力結果だと面白みにかけるので、もうちょっと複雑な入力にしてみましょう。ソースコードの文字列入力部分を以下のように変えてみます。パラグラフ方向はLTRのままです。
val str = "あ\u202B\u05D0い\u05D1\u202Cう"このときの出力結果はこのようになります。
$ kotlinc Main.kt && kotlin MainKt
論理順: (0..0, 0), (1..2, 1), (3..3, 2), (4..4, 1), (5..6, 0)
表示順: (0..0, 0), (4..4, 1), (3..3, 2), (1..2, 1), (5..6, 0)この例で渡している文字列は「LRLRL」の入力なのですが、真ん中の「RLR」の部分をRLE(\u202B)とPDF(\u202C)という文字で囲っています。これはBiDiアルゴリズムの中で説明した、明示的な埋め込みを表す制御文字です。もしアルゴリズムの解説の章を飛ばした方は、「BiDiの方向を変える文字が挿入された」と考えていただいて大丈夫です。この表示順の出力は「左からまず0文字目をLTRで、次に4文字目をRTLで、そして3文字目をLTRでで、そして1文字目と2文字目(制御文字)をRTLで、最後に5文字目(制御文字)と6文字目をLTRで表示。」という意味になります。
おつかれさまでした。TextViewのような文字描画コンポーネントを作る場合はここからCanvasなりで左から順番に部分文字列を描画していくことになります。ですが、BiDiの仕組みを理解したりデバッグしたりするだけであればこのプログラムで十分かと思います。次の章以降でBiDiの非自明な動きを見ていきますが、そのような入力でBiDiアルゴリズムがどのような動きをしているか、ぜひこのプログラムを改造して試してみてください。
BiDiヤバイとなる話
さてここからは、LTRだけの世界に閉じこもっていては体験できない、BiDiに起因する面白い現象や解くのが困難な問題を紹介していきたいと思います。BiDiの文章はLTRの世界に生きてきた我々には、にわかには信じがたい、直感に反する挙動をすることがあります。この章はそんな挙動の紹介をしていきたいと思います。
ヤバイ話その1 カッコが混乱する
BiDiというよりRTLの話ですが、カッコ(括弧)の取り扱いがちょ〜っとばかし大変なことになっています。まず、我々LTRの人たちは、文章の中の括弧は先に開き括弧「(」を書いて、適切なときに閉じ括弧「)」で括弧内に文章を書きます。

これはRTLの場合、ちょっとややこしいことになります。以下の例を見てみましょう。

この2番めの文字と6番目の文字はどちらが開き括弧でどちらが閉じ括弧でしょうか?正解はこんな感じです。

なぜなら、開括弧は「今から括弧で囲われた文字を開始します」という意味なので、論理順で閉じ括弧よりも先に来るべきだからです。しかし、RTLの環境では括弧の開く向きが違います。LTRでは右に開きますが、RTLでは左に開きます。そう、括弧はおなじコードポイントなのに、「LTRでは右に開き、RTLでは左に開く」ように描画しなくてはならないのです。これはテキストのレイアウト計算のレイヤーで処理が行われており、この辺に興味のある方は、OpenTypeのMirroring Pairs List (OMPL)を参照してみてください。
ちなみに、この仕様のためにLTRで計算したテキストレイアウトをRTLで再利用することが不可能になっています。例えば「文字の幅の計算だったら、LTRもRTL結果は同じだよね」と思っているとこの仕様でアウトになります。なぜならLTRと思って計算したテキストレイアウトは、RTLと思って計算したテキストレイアウトとグリフ単位で異なる可能性があるからです。文字の幅計算APIが文章の方向を要求しているのはこれが理由です。
なお、カッコの問題はこれだけでは終わりません。カッコが表示する方向で文字の形状が変わることは、まぁ理解していただけたかと思います。これでカッコが反対を向いてしまうことはなくなりそうです。ですが、もし開きカッコはLTRのRunにあるけど、閉じカッコがRTLのRunにあったらどうするの?と思いませんか?

このようなカッコのペアが異なるレベルのBiDi Runにある場合、どうすればよいのでしょうか?BiDiアルゴリズムはこのような場合も対応していて、ざっくり言うと「カッコのペアを見つけてきて、カッコの中の文章の方向に合わせて、カッコのペアを同じ方向に揃える」という処理をします。細かい仕様はUAX#9に譲るとして、この場合4番目のカッコはLTRになり、以下のようなBiDi Runと表示順になります。

ヤバイ話その2 数字が混乱する
数字、ここでいうアラビア数字やインド数字はRTLの文章の中でもLTRのように動作すると説明してきました。ここで注意すべきなのは「数字だけ」なことです。プラスマイナスの符号などはNeutralな挙動をすることもあります。例えば、LTRで「-50%」と表示していますが、同じ文字列をRTLの環境に持っていくと「50%-」のように表示されてしまいます。

ただ、これが本当にネイティブな方々に期待される挙動なのかはよくわかりません。ちょっとググっただけでも、質問掲示板にも「マイナスが右にあるのを修正したいんだけど?」や「数字はLTRで書くからマイナスは左に書いてるよ」っていう意見が出てて、正直期待されている挙動なのかわかりません。「-1-2」みたいな数式をRTLの環境にもっていくと「1-2-」みたいになってしまうのですが、こんなものをみてRTL言語圏の人たちは瞬時に理解できるのかと首を傾げたくなってしまいます。

少なくともUnicode的にはこのような表示順が期待されているみたいですので、とりあえずこれで表示していれば「Unicodeがこう言ってるもん!ぼくわるくないもん!」と言い訳はできそうです(?)
ちなみにUnicodeはサポートしていませんが、アラビア語の数学記号なんてものもあるみたいです。シグマがひっくり返っていたり、無限大への極限が右から左に矢印が出ていたり、なかなかおもしろい図になっています。
私はこの辺全く詳しくないので、下手なことを書く前にそっと閉じて退散することにします。
ヤバイ話その3 電話番号が書けない
さて、数字絡みでもう一つ直感と反する挙動を見ていってみましょう。みなさん、電話番号書けますよね?数字を3桁か4桁づつで区切って表示するあれです。あれをRTL環境(パラグラフの方向がRTL)で表示するのは、実は簡単ではありません。実際に電話番号を入力できるページを作ってみたので、試しに入力してみてください。
どうでしたでしょうか?LTR環境で「(123) 456-7890」と表示されていても、RTL環境で「456-7890 (123)」となってしまいませんでしたか?順番が入れ替わってしまっていては電話番号として使い物になりません。

なぜこれが起こるのかを見ていきましょう。数字はLTRとして扱いますが、Strong L属性ではないため、間にある空白文字の方向を変えません。結果として空白文字が最後まで解決されず、結果パラグラフの方向と同じにされてしまいました。結果として「(123) 456-7890」はLTR環境では「LLLLLLLLLLLLL」ですが、RTL環境では「LLLLRLLLLLLLL」となってしまい、「(123)」と「456-7890」の2つの埋め込みだと解釈されてしまったのです。似たような現象は他の文脈でも起き得るのですが、電話番号の厄介なところは、文字列中に数字以外の情報がないので、コンテキストによる補完がうまくいかないのに、文字の順番がクリティカルであること。加えてRTL言語でもLTR言語でも同じフォーマットであり、そこそこ使用頻度が高いことです。
これの回避方法はいくつかあります。もしBiDiアルゴリズムの解説を読んでいただいた方でしたら解決策が思い浮かぶかもしれません。ぜひ、以下のような表示ができるように挑戦してみてください。

ヤバイ話その4 キーボード操作がわからなくなる
みなさんはバックスペースやデリートキーで文字を消すとき、「バックスペースは一個前の文字が消える」「デリートキーでは一個後の文字が消える」と思っていると思います。正しいです。全く正しいのですが、RTLの環境だと、(少なくとも私の)脳は混乱します。なぜなら、RTL環境では「バックスペースキー」で消すのは一文字前、つまり右の文字が消えます。デリートキーは逆にカーソルの左の文字が消えます。


では矢印キーはどうでしょう?これは実装によって挙動が変わります。AndroidやFireFoxではキーボードの左右キーを押すと表示順で左右に移動します。つまり、右を押すと文字列がLTRだろうとRTLだろうと、パラグラフがLTRだろうとRTLだろうと、見た目上右に進みます。


この実装では、バックスペースは直前に書いた文字を修正するためのキーなので、意味的、論理的に一文字前の文字を消すのが良い。デリートキーはその逆で意味的、論理的に一文字後の文字を消す。左右キーは画面上の左右移動をするキーだから、表示順で左右に移動させている。このようなポリシーが透けて見えますね。この実装の左右キーは非常に直感的に動作するので、BiDiテキストの場合もすっと理解できるかと思います。
一方で左右キーのChrome上での挙動は、パラグラフと同じ方向のキーが押されるとカーソル位置が論理順で1減ります。逆にパラグラフと逆方向のキーが押されるとカーソル位置が論理順で1増えます。例えば、LTRのパラグラフで右キーを押すとカーソル位置が論理順1増えます。つまりLTRのパラグラフで右キーを押すと、文字列がLTRだったなら右に1移動し、文字列がRTLだったなら左に1移動します。かなり複雑で、特にBiDiテキストだと、左右キーで目的の場所にカーソルを移動させるだけでも大変です。ただ複雑な挙動をしますが、LTRパラグラフでLTR文字列を書いている、もしくはRTLパラグラフでRTL文字列を書いている分にはAndroidやFireFoxと同じ挙動をするので、あまり現実的には問題になっていないのかもしれませんね。
実際に試してみてください。
ヤバイ話その5 ヒットテストが複雑に
テキストの文脈でヒットテストとは、テキストが表示されている画面上の座標が与えられたときに、それは文字列中の何文字目であるかを判定する処理です。

この例では、赤いバツじるしの座標にある文字は何でしょう?という問題ですね。
ここでは簡単のために、一行の文字列が表示されているときに、X座標が与えられた場合、そこにある文字は何文字目ですか?という問題を考えます。まずは全ての文字がLTRの例で考えます。

等幅フォントでもない限り各文字の幅は計算してみないとわからないので、基本的には左から順番に文字幅を足していって、指定された座標を超えたらそこが答えとなる番号です。
すべての文字がRTLだとしても、逆方向から(8文字目から)足し上げていけば計算できます。

さて、BiDiを見てみましょう。

もう見るからにヤバイですよね。ですが実はそこまで複雑にはなっていません。基本的なステップとしては、BiDiアルゴリズムでVisual Runに並び替えた後、左から足し上げていくだけです。各文字の幅が分かってさえいればそこまで難しい問題ではありませんね。
ヤバイ話その6 文字の挿入位置が複数ある
ヒットテストはまぁそこまで複雑にはなっていませんでした。しかし場所を特定してカーソルを表示しようと思った時、カーソル位置の計算はかなり複雑になっています。指定の位置にカーソルを表示する際、通常はインデックスで指定します。「4番目にカーソルを配置する。」のような感じです。以下の例はLTR文字列のときの「4番目にカーソルを配置」した例です。

「4番目の文字の左」にカーソルが配置されています。これは皆さん自然なことだと思いますよね。なぜなら、カーソルとは文字が挿入される目標の地点を示しているからです。4番目のカーソルとは、「新たな4番目として文字を挿入したときに、その文字が現れるであろう場所」に表示されているカーソルのことです。

では次にRTL文字列のケースを見てみましょう。以下の例のうち「4番目のカーソル」はLTRのように4番目の文字の左に置くべきでしょうか?それとも4番目の文字の右に置くべきでしょうか?
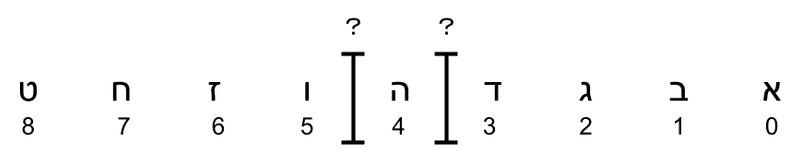
ここで先程のルールを見直してみましょう。新たな4番目として文字を挿入したときどこに入るでしょうか?

となり、期待される「4番目のカーソル」は「3番めの文字の左、4番目の文字の右」となります。

簡単にまとめると、「n番目のカーソル」はLTRの場合は「n番目の文字の左」に表示して、RTLの場合は「n番目の文字の右」に表示すればいいことがわかります。ちょっと複雑ですが、まだなんとかなると思います。
ではBiDiの場合を見てみましょう。BiDiの場合でもBiDi Runの内側だとLTRやRTLと同じ挙動をするのですが、もしカーソル位置が文字方向が変わるような場所に配置されると、ちょっと奇妙な動作を行います。例えば以下のようなBiDiの文字列を考えてみましょう。

ではここで3番目の位置にカーソルを配置することを考えてみましょう。LTRやRTLの例と同じように、文字を論理順で新たに3番目の文字として挿入したときの位置で考えてみます。

これを見る感じだと、「2番めの文字の右」もしくは「5番目の文字の左」にカーソルを表示すれば良さそうです。ですがちょっとまってください。もしここでRTLの文字を挿入すると全く違う場所に文字が挿入されます。

もしRTLの文字が論理順で新たな3番目として挿入されたなら「3番目の文字の右」もしくは「6番目の文字の左」に入るのでそこにカーソルを置くのが良さそうです。つまりカーソルとして表示されうる場所は2箇所あることになります。

では、結局どちらをカーソルとして表示すればよいのでしょうか?実は紆余曲折ありました。Androidだと過去には両方表示していたこともありました。ですが、今は一個だけ表示されています。現在では「パラグラフの方向と同じ方向の文字が挿入された時に挿入される位置」に表示することになりました。つまり、この例の場合だと、パラグラフの方向はLTRなので、LTRの文字が挿入されるであろう位置に表示されるはずです。

Androidではこの位置を取得するためのAPIとしてLayout#getPrimaryHorizontalとLayout#getSecondaryHorizontalを用意しています。Primaryとはパラグラフの方向と同じ方向の文字を挿入した場合の位置、Secondaryとはパラグラフの方向と逆の方向の文字を挿入した場合の位置のことです。

ヤバイ話その7 文字選択が飛び地になる
普段皆さんがコピペするときに、文字選択をすると思います。その際、選択範囲は通常だと四角形でハイライトされます。選択範囲は論理順で指定されます。例えば「1文字目から5文字目まで選択」を選択といったとき、これは論理順での文字範囲を言います。LTRの文字列では表示順と同じなので自明な四角形になりますね。

RTLの場合、表示順が論理順の逆になるので、直感的な位置はずれますが、まだ理解しやすい四角形になります。

ではBiDiの場合はどうでしょう?BiDiテキストの場合、論理順と表示順は昇順にも降順にも並んでいません。ですので、論理順で隣り合っている文字を選択したとしても、表示順で隣り合っている保証はなく、一般には飛び飛びの場所になってしまいます。ですので、単一の四角形ではなく複数の四角形で表現されます。

実際に試してみてください。Webの文字選択はinclusive-exclusiveですので、1〜5文字目の選択をする場合は1〜6文字と入力してください。
ヤバイ話その8 改行が複雑
テキストを表示する際、与えられたテキストが長すぎた場合自動的に折り返して表示する機能があります。Automatic Line Breaking(自動改行)とかWord Wrapping(ワードラップ)などと呼ばれています。ここでは単に改行と呼びます。LTRの文やRTLの文がどのように改行されるのかを見てみましょう。まずは「あいうえおかきくけ」というすべてLTRの文の例です。

文字の下の数字は論理順でのインデックスを表しています。青い領域が表示可能領域で、この例では「かきくけ」が表示できていないので、改行して表示します。

RTLの場合も見ておきましょう。ヘブライ語の文字9文字を同じように改行しようとしています。

実際の描画で見ているので、並びはすでに表示順に並び替えられています。ここでは4番目の文字まで書けそうなので、4文字目の後ろで改行しましょう。

RTLの場合、全部逆になっているのでちょっと混乱しますが、まぁ直感的な結果が得られますね。さて、問題です。以下に表示してあるBiDiの文章は、どこで折り返すのが正しいでしょうか?

正解はこの入力に対して改行を実行すると、以下のようになります。

4番目の文字と5番目の文字まで入りそうなので、その2文字を1行目に残しそうなものですが、実際は3番目と4番目の文字だけ1行目に残して改行をします。なぜなら、改行、というよりは部分文字列の取得は論理順で行われるからです。ちなみに、これはまだ埋め込みが浅いのでなんとなくわかりますが、これが深い埋め込み、例えば「RTLの文の中にLTRがある」文をLTRに埋め込んで・・・みたいな文を改行するときも、論理順で行うのですが、LTRだけで生きている人間には本当に直感的ではないので困ってしまいます。
また一点注意です。長い1行のBiDiのテキストを論理順で改行して部分文字列をつくり、複数行に分けました。しかし、その後各行についてBiDiアルゴリズムを再適用してはいけません。必ず改行前のレベル値を使って表示順に並べ替えてください。さもないと、埋め込み関係がずれてしまい、誤った順番で出力されることがあります。例えば以下の例を考えてみましょう。
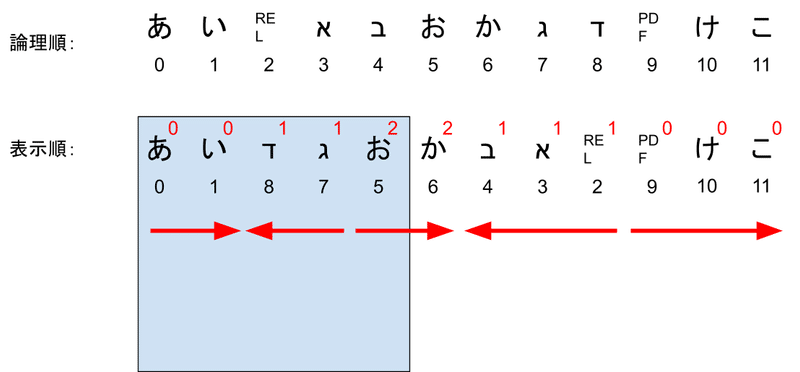
表示順の文字の右上の添字はその文字の埋め込みレベルを表しています。これを論理順で改行すると以下のようになります。

ここで注目していただきたいのが、2行目の文字のレベルです。もし2行目である4文字目から7文字目までの部分文字列にBiDiアルゴリズムを適用すると、レベルは「1001」となり、以下のような表示になります。
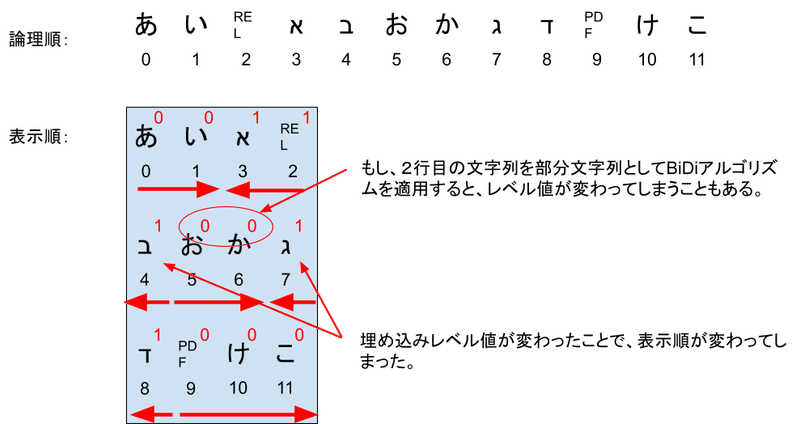
このようになってしまうのを避けるために、改行などで部分文字列を表示する場合はかならず、改行する前の文字列のレベルを使って行ってください。JavaのBidiクラスを使っている場合は、Bidi.createLineBidi関数を呼ぶことで改行後の列に対してBiDiアルゴリズムの結果を得ることができます。
ヤバイ話その9 拡張子の偽装ができてしまう
最後に有名な話なのですが、BiDiの制御文字を使うことによって拡張子を偽装することができます。Windowsではファイルの最後のピリオド以降の文字列で、紐付けられたアプリケーションを起動して開く仕様になっています。ですので、実行ファイル形式の「.exe」という拡張子は開くのに注意が必要です。逆に「.txt」という拡張子はテキストファイルなので、気軽に開く人が多いでしょう。それを利用して、拡張子が一見「.txt」に見えるのだが、実行してみたら実は「.exe」でした!という拡張子を偽装できる脆弱性がありました。この「.txt」に偽装するのにBiDiアルゴリズムが使われました。具体的にはRLOという制御文字を使って、アルファベットを無理やりRTL文字列にしていたのです。例えば、「exe.怪しくないよ.txt」という見た目が「.txt」で終わるファイルが実は「.exe」でした、というファイルを作ってみます。まずは「txt.よいなくし怪.exe」という文字列を用意します。この文字列はBiDiアルゴリズムの過程ですべて文字方向は「L」になるので、全体はLTRで描画されます。

ここで、この文字列の先頭にRLO(\u202E)をつけます。このRLOはRight-to-Left Overrideの略で、後ろに続く文字列の文字方向を強制的にStrong Rに変更します。つまり、この場合はすべての文字がStrong R、ヘブライ語のような扱いになるので、全体がRTLになります。したがって文字を右から左に書くので、以下のようになります。

実際にはRLOは幅ゼロの見えない文字なので、「txt.よいなくし怪.exe」が見た目上「exe.怪しくないよ.txt」と見えるというわけです。同様の手法はURLのドメインを偽装することにも使えたりしますので、現在このRLOはUnicode的には非推奨となっています。もしあなたのアプリがセキュリティ的にセンシティブで、ドメインや拡張子の偽装が不安な場合は、RLOを前処理で全部消してしまうか、無害な文字に置き換えてしまうのが良いかもしれません。
おわりに
お疲れ様でした。こんな長い文章にお付き合いいただきありがとうございます。私がこんなに長い文章を書いたのは大学生のころ以来かもしれません。今回はBiDiアルゴリズムの概要を掴んでもらうために、私なりに解説をアレンジしてみたのですが、いかがだったでしょうか。わかりにくかったり、かえって混乱させてしまったら申し訳ありません。BiDiのカオスな世界を少しでも垣間見せることができたら幸いです。
前回は絵文字について書きましたが、今回のBiDiは絵文字とはまた違った複雑さではなかったでしょうか。私の中で絵文字は、構造的な難しさはそこまでではなく、むしろインターオペラビリティや最新版リリースから使用可能になるまでのタイムスパンの短さのほうが難しい問題でした。それとは違ってBiDiは純粋に問題自体が難しいと思います。埋め込み関係をもとに並び替えるという操作は、単に文字を定義して字形を決めるだけでは解決不能な問題です。BiDi自体はもはやモダンなOSでは標準装備となって久しい技術ではありますが、たまにはそんな縁の下の力持ち的な機能について知ってみるのも面白いのではないかと思いました。みなさんの知的好奇心が少しでも刺激されたのでしたら幸いです。
それにしても神様、バベルの塔を作ってしまったがための業が深すぎやしませんかね。
この記事が気に入ったらサポートをしてみませんか?