
あまりにもやっかいなOpenType Features

さて、まぁ、前回、実はこの本の話をしようと思っていて、パンクチュエーションなネタを引っ張ってきてはいたんだけど、また、いつものごとく書いてるうちにそのことをすっかり失念していて……まぁ、今更感想文書いても仕方が無いので、今回はまず先に、そのときご披露しそびれていたその本の紹介だけをしておくのだけれど、こういうヤツ。
ネット上にはもうだいぶ感想文が出そろってきてしまっているので、今更ここで追加することは何も無いんだけど、ただ、まぁ、著者も訳者も立派な先生だからといって……セミコロンの真面目な解説を期待するようなら、そういう本では無いということだけは注意しておく。セミコロンについての情報を得るつもりで買ってしまうとページをめくる度にイライラさせられ、星で低評価を付けた上、レビューで悪態をつかないと気分が収まらないということに……いや、まぁそれはいいとして、まぁ、そういう感じになるだろうということもあるので、そういう意味でいうならばここでやっているコトも似たようなモノだから、OpenType Featuresについて知識を得たいので読んで見ようなどということを考えると、5〜6行に1回はイライラさせられて、𝕏で悪態をつかないと気分が収まらなく……まぁ、そこはもういいとして、ともかく、まともな知識を得ようと思ったら、いつも言うけど、ちゃんとしたことは、ちゃんとしたところで……お願いしますよホント。
ということで、今回は前回の続き。前回のおさらいを簡単に言うと、フォントのコロンの位置をメニューで正しい位置に変更するという感じにOpentypeのFeatureを機能させようとして……まぁ、端的に言えばその実装に失敗しているので、今回はそれとは別の方法で機能させようとするというおはなし。まぁ、といってもやり方自体の問題というよりはOpentypeFeatureの一部のGPOS制御がインド言語のオプション表示をオンにしてからでないとイラレの日本語版ではまったく機能しないのと、そのオプションをオンにすると今度は日本語のほうで問題が起こるという排他制御になってしまっているという困った関係にあって、さらには一旦インドでオンにして作業してからオフにして東アジアに移動すると、とたんにGPOSが機能するようになるとか、そういうなんだかよくわからない挙動をするなどという、これはもうどちらかというとillustratorというアプリケーションの側の問題なので、俺はちっとも悪くないと開き直ることも可能なのだけれど、そんなことを言い張っても機能しないことにはまったくお話にならないので、今回は怪しい挙動のGPOSを避けてGSUB……つまりグリフの置換のメソッドで前回同等の仕組みを取り付けようというおはなしを、なるべくOpenType Featuresの解説多めで行おうというおはなし。といってもInDesignもようやくHarfBuzz text shaping engineっていうOpenType レイアウトエンジンに対応したので、その手の問題からはなんとか……まぁ実はそのせいかどうかはわからないけど、バージョンアップしたら他で問題が出ちゃってるんだけど……まぁ、いいや、ともかく、イラレでもいずれはそうなれば終わっちゃう話だからあれなんだけど、ともかく現時点でのイラレで仮に東アジアの言語オプションのほうが選択されていても、これでちゃんと機能するプログラムをフォントに内挿することが可能になる……はずだよね……多分。

今回サンプルに用意したのはこのフォント。分類するとジオメトリックサンセリフのバウハウススタイルということになるのだけれど、デザインは70年代のサイケデリックな雰囲気にだいぶ引っ張られてしまっている……まぁ、細かい話はどうでも良いということでフォント名は以下のようになっている。

ファイルネームをこうしているので、だいたいは何をイメージして作ったのかはわかるとは思うのだけれども、まぁこんな感じ。中見だし程度のタイトルや、大文字だけの長めのリードでの使用を想定していたためサイドベアリングは若干緩め。初めは大文字だけしか作る予定が無かったのだけど、それだといろいろ不便なこともあったので、後から小文字も追加している……ので、まぁ少しばかり大文字と小文字の関係がアレなトコロもあるにはあるけど、ここも……今回はそのあたりはどうでも良いので、この自作のフォントを再利用してOpentypeFeatureで、いろいろしてみようという感じのお話。
さて、Opentypeフォントのプログラムといっても、逐次実行のシリアル処理で、まぁ出来ることもホントにプリミティブなことしかしていないので、多少でも何かの言語を囓っていればロジックはたいして難しくは無いし、今ではフォント作成ソフトも自動化が進んでいるから、まったくプログラムが書けない素人でもAIに頼る必要すらないくらいにどうにでもなるというようなことにはなってはいるのだけれど、それでもプログラムのロジックがわかっているのといないのとでは、それなりに可能な範囲が変わってくるので、フォントを弄ったり作ったりするというのであれば、わからないよりは多少はわかっていたほうがいいということもある……まぁ、なんでもそうだけど。
で、そのロジックなんだけれども、基本的には覚えることは二つだけで、「グリフAの出力をグリフBに置き換える」と「グリフAの出力されるポジションを変更する」と、たったこれだけの内容で、前者をGSUB Feature、後者をGPOS Featureというふうに分類する。今となっては何を省略したのかよくわからなくなっているGSUBとGPOSの意味だけれども、普通はGSUBはグリフ置換のglyph substitution、GPOSはグリフ位置でのglyph positioningという説明がされている。機能的にも似ていて名前も同じ正規表現絡みのはなしと混同してまた別のことを言ってる人もいるけど……まぁ……そういうことは気にしなければどうと言うことも無い……ともかく基本はこれだけなんだけど、これでリガチャ、スワッシュ、スモールキャップ、縦書き、横書き、ルビ対応、字幅半角、連綿体、多言語、等幅送りにプロポーショナルだのカーニングだのまぁ言い始めるとキリが無いけど、こういう機能をフォントファイルに盛り込むことが可能になっている。え? size? ………………まぁ、ともかく、話を続けると、そういう感じにいろいろと機能を盛り込むことはできるけど……注意しておくと、これ必ずしも、別に、全部のせにする必要があるとか言ってるわけではないからね。
それで、この機能は、リクエストに応じて実行する動作を定義するという形に機能を構成するというようなことになっているわけで、CSSのフォントプロパティ絡みではお馴染みの4文字の識別タグからそのリクエストに対応する部分がきちんと反応して答えを返すように、フォントファイルにフィーチャーとして記述されるというふうな構成になっている。フィーチャーのしている例を説明すると、以下のような仕組みになる。

この図は、デフォルトの数字をオールドスタイルという別のスタイルの数字グリフに置換する場合のフィーチャーの仕組みの概念図。オールドスタイル数字というのは、別に古くて野暮ったい数字というワケではなくて、現在でも必要に応じて使用される……というか、もともと数字の形は小文字に揃えてこういうオールドスタイルな感じだったので、古いスタイルという後ろ向きな語感を嫌う人はText figures……つまりテキスト数字という言い換えもする。で、数字が現在のモダンな字形になったのはビクトリアンレボリューション以降のトレンドで、広告や新聞などで大文字だけでタイトリングする場合、ノンライニングでは数字が小さく見えて格好が悪いので数字の大文字つまりタイトル用数字ことライニング数字が作られることになったというわけ……まぁ、そのうち数字に大文字と小文字があるのが面倒になったのか、活字のパンチカットも1種類にすれば作業が省けて、楽になるじゃん、ということだったのか、数学の教科書のように数字と記号だけで文章を作る場合きちんとレンジングしているほうが都合が良いと言うことだったのかどうなのかというそういう諸々のことはともかく……まぁ色々なんやかんやあった揚げ句の三八で現代のような一つの書体に1種類の数字という常識に到達したというわけなんだけど、そういう理屈だから今でも本文中の数字は、まともでオーソドックスな組み版にしたいならオールドスタイルが推奨ということになってはいる。ただ、活版印刷の時代と違って現代では字形増やすのにそれほどコストもかからないので、デジタルになってまたそこら辺の感覚も復活してきたという感じ? まぁ、トレンド的な雰囲気まではわからないけど、そういう感じなので……実はイラレのメニューのこの項目の翻訳は、狭い業界人にしかわからないようなライニングだのオールドスタイルだのという言い方よりは思い切って初めから大文字小文字とか本文用数字、タイトル用数字とか整列もしくは非整列とかそういうことにしておいたほうが良かったのではないかと俺なんかは思ったりもしたんだけど、現代ではこの言い方で定着してしまっているせいで、何か別の意味があるような錯覚が新たな何かを生み出しつつあるということにも……。
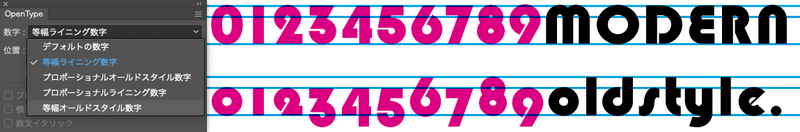
まぁ、そういう戯れ言はともかく、で、そういったことで、デフォルトの数字をオールドスタイル数字という小文字の数字に変更して表示してくださいというリクエストに対して、onumというフィーチャーのタグに数字を置換するためのプログラムを走らせていますという概念図の囲みの中に記載したリクエストに対応する機能のプログラムは……この図ではFeatureの名前がonumとなっているけど、実際こういうことをしようとする場合、ここでの機能のフィーチャーの名前はこの名前に決定している。Opentype Featureでは、どのケースなら何をすべきというコマンド……というか識別タグが決まっているから、ここの名前は厳密な規則があり勝手に変更できない……のだが、ただ、内部的には名前は引き金のラベル程度の意味しか持たないので、実を言うとやりたいことが決まっていて、引き金をどこに設置すれば都合が良いのかがちゃんとわかっているのならば、ぶっちゃけいえば Feature Name と中身のプログラムの対応関係はホントのところはどうでもいい……というと語弊もあるるけど、基本的にはまぁその程度の緩い関係なので等幅ライニング数字への変換が欧文合字の枠の中にプログラムされていても文法上のエラー的なことでもなければ出力時には問題にならない。まぁ、ユーザー的には困るので普通はそういうことはしないけど、それより大事なのはブレース括弧の中のプログラムで、構文の正しさはもちろんだけど、ここでどういうトリックを仕込むと都合と具合がいいのかということのほうが、本当のところはキモになる。
で、上の例だけど、単純に1023のモダンスタイル字形を1023のオールドスタイル字形に換字するだけなので、でっかく1023ってなっているところの括弧の中のプログラムは、具体的には1023に対応するそれぞれのフォントソースのグリフネームをスペースをあけて並べて

とすれば良いだけなんだが、勿論これがダメなのは小学生にも理解出来る。
プログラム言語を少し囓った程度の脳味噌でもわかると思うけど、このプログラムの命令ではテキストが1023と並んだケース以外では換字がまったく利かないからだ。かといって、可能な文字の組み合わせを0から999999…まで、全てを全部並べて記述したら猿がシェイクスピアを打ち出すようなおかしな事にはなるので、普通は1文字を1文字で置換してマッチしたら次の文字に進み次にマッチした1文字を別の1文字で置換して次に……という感じに機能は働くようにはなっている。なので、この場合10進数の数字の10種類を1文字づつ丁寧に書きだし列挙して

と10行ほどのプログラムにすればOK。まぁ、それで、これでもいいのだけれど、もう少しクレバーに見えるようにデータの要素を配列として並べ直して……まぁ、この場合の要素はクラスとして定義されるオブジェクトと……っていう、まぁそういう話はいいとして、ちゃんと格好良くしようとすれば、以下のようになる。

上と下の配列の順番と個数がちゃんと合っている必要はあるけど、IUTをジグソーパズルで説明する程度のわかりやすさで書き直せばやってることは

という意味で、これで、まぁ対応するグリフの間での置換が行われる。クラス定義の@以下の名前は好きな名前で構わない。これで、クラス配列中のどれかの文字が出てきたら、それを別のクラスの同じ位置のグリフと入れ替えて出力するというたった1行で書けるコマンドの出来上がり。アプリケーションの側からオールドスタイルを選択するとこのフィーチャーが呼び出され自動的に普通の数字がオールドスタイルの数字で出力されるという……そういうフォントの完成だ。
まぁやってることは単純で簡単……なんだけど、実を言うと数字に関わるグリフは他にもあるかも知れないので、そのあたりへの目配せを怠るとプログラムとしてはいまいちなことにもなる……具体的に言うとサンプルのフォントでは、デフォルトの数字とオールドスタイル数字以外にも等幅数字、上付き数字、下付数字、分子、分母……とまぁ、自分でも呆れるくらいの多彩多様な数字のグリフの異体字……つまり別パターンのグリフを抱え込んでおり、こうなると変換のケースによっては全てのパターンを列記する必要もあるんだけど、これをまたいちいち一対一で対応させられるように配列の中身をでっかくしていったり、ケースに応じてそういうでっかい配列をいくつも用意してやったりなどとすると……これはこれで、ちょっと原始的でアホな対応に見えるので……クレバーに見せたいならそうは見えないような工夫も当然必要にはなってくる。
配列の中身はどうすると都合が良いのかとか、機能の発動の順番に応じてとか、Aの機能がONになっている場合とOFFの場合では対応関係がどう変わってくるのかとか……まぁ、こんな置換とポジショニングの変更だけしか行わないような単純なプログラムでも、パーツパーツで全体が相互に絡み合ってくれば、そういうときのフローチャートをどう設計すればいいのか問題は当然あって、どのケースにもキチンと対応してエラーが発生しないようにするとかそういうことをいろいろ考えたりすると、プログラムはどんどん複雑怪奇になっていったりもするのだけれど……でも、まぁ、今回はポジショニングのこともエラーチェックのことも一旦は忘れて、置換による変換操作で色々出来ることを試して見ようという感じ……って、大丈夫かな、また、話が諄くなってきているけど……。
ただ、まぁ、前にもいったけどOpentypeのプログラムはモダンな最近のフォントエディターを使えば、ほぼ自動的に物事は進むようになっていて、Glyphs3の場合はグリフを作成したらフォント情報を表示してフィーチャーのタグからフィーチャーを自動で生成すれば……まぁ、だいたいほとんどはそれでお終い。FontLab8でも最近はGlyphs並みに自動生成の機能が充実しているので、FeaturesパネルからAdd Auto Featuresすればお終いになるので、クリエイターのほうで何かするということもこれまたほとんどないのだけれど、それでもまだまだちょっと変わったことを考えると多少は工夫が必要にもなる。また、余計な事だけど、お互い方言の違いみたいなことがあって自動生成されるプログラムにも若干の壁が存在する。

これのわかりやすい例は、フィーチャーのfracで、Glyphsではslashというキーボードの左下の記号を同じような形の別の文字のfractionに変換したら、全ての数字を分子のサイズと位置にある分子の数字字形に変更しfractionに続く数字を、分母の字形の数字に変更したら分母に続く分子を分母に置換するというアルゴリズムが使用されている。まぁ、当然上でオールドスタイルの字形を作ったように分子と分母の数字の字形は予め作っておく必要はあるのだけれどやり方は単純明快。仮に普通の数字のクラスを@frac_figs、分子を@frac_numr、分母を@frac_dnomとすれば、以上の連除の手順は以下のオープンタイプのフィーチャーのプログラムに書き下すことができる。

実際にはGlyphsで自動で書き出すともうちょっとゴチャゴチャしたフィーチャーにはなるんだけど、それをちゃんと整理すれば内容はだいたいこんな感じ。ただ、単純すぎて問題もあるのでFontLabではopentypecookbookのアイデアをベースに、以下のようなアルゴリズムを採用している。

多少整理したけどそれでもごちゃごちゃしていてなんだかわからないだろうから解説すると、Glyphsと同様まずslashをfractionに変換したいのだけれど、関係の無いところで数字が勝手に小っちゃくならないように、slashとslashで数字を挟んでいる場合、若しくはslash二つが並んだ場合を例外とするという処置を行ってから、slashの前に数字が来る場合にslashをfractionに置換する……というのがルックアップのFRACのところ。ignoreを使ったコンテキストでの置換を行う場合、全ての可能性を列挙する必要があるので……まぁ、ignoreは後で解説するのでここではいちいち説明はしないけれどこんな感じになっている。次に、お待ちかねの普通の数字から分子の数字への置換だが、前段で既にもう数字の後の斜めの棒はfractionに変わっているので、fractionの前には普通の数字が来ているということになっているハズ……なので、fractionの前に普通の数字が来たらその数字を分子に変更する。という命令が次のルックアップのUP1。前方一致と違って後方一致で前方を置換する場合、一度の一致から一遍に前方をバタバタと置換していくということができないので何桁もの数字が並ぶと、当然この1回では片付かないから次のループに入る。で、次にもし分子の数字が2桁以上になるのならルックアップのUP1の結果から、ここで普通の数字、分子の数字、fractionの並びが発生しているはずなのでそれを見付けて先頭の普通の数字を分子に変えたら、その結果からもう一度次のループで、数字が3桁以上なら普通の数字、分子、分子そしてfractionという並びが見つかるはずなので、その普通の数字と分子と分子とfractionの並びを見付けてやっぱり先頭の普通の数字を分子の数字に変更し、分子分子分子fractionを作成する。もし分子が4桁以上になるのなら、その次の検索ループで普通の数字分子分子分子fractionの並びが必ず見つかるはずなので、その普通の数字分子分子分子fractionを検索し、先頭の普通の数字を分子に変更して分子分子分子分子fractionを作成する。さらに5桁以上なら次に普通の数字分子分子分子分子fractionの並びが見つかるはずなのでそれがあるかどうかを検索して置換、更に6桁以上の可能性があるのなら、もう一度検索置換……ってまぁこんな作業を10回ぐらい続けているのがlookupのUP1からUP10で、それだけ回って気が済んだなら後はfractionに続く普通の数字をGlyphsと同様分母の数字に置換するというルックアップのDOWN……ってな感じのアルゴリズムを採用している。まぁ、このアルゴリズムを採用した場合分子の桁数は、普通の数字、分子、分子、分子……分子、fractionの並びから……っていうくだりのところの繰り返しの回数を超えるとそれ以上の作業はキャンセルされてしまうので、分子の桁数を10桁以上に増やそうと思ったらその分のlookupが大量に必要となる……のと、最初ルックアップのFRACのところのslashと数字とslashの例外処理のパターンも当然その大量のlookupの数の分だけは必要となるので、説明聞くだけでもなんだかよくわからなくなってくるようなこのあたりの再帰的な力業というものがどうにもノットエレガントなんだけど、結果は単純なGlyphsの分数処理よりはクレバーな仕上がりにはなる。
あと、わかるとは思うけどFontLabで自動で書き出すとlookupネームは実際にはfrac_bar、frac_numr、frac_dnomってなことになるんだけど、まぁここの名前は、実は何でもいい。何でもよくないのは、アルゴリズムの出所でFontLabの場合ではこのfracのフィーチャーを自動生成すると、コメント記号の#に続けてArbitrary fractions (based on opentypecookbook.com)が自動的に入力される。コメントなのでexportすると消えちゃうし、外してしまっても問題無く動作はするけど、短いとは言えプログラムはプログラムなので自分で動作原理がよく理解出来ないようなものをぶら下げる場合、出所がわからないものを利用してドヤ顔していると、いずれアカウント削除して逃亡という……いや、まぁ皆までは言わないけど……最近ではAIなんかにプログラムを書かせたりすることもあるとは思うけど、その場合でもAIトレースならAIトレースっていうことがわかるようにはなっていないと、それなりには問題はあるかもしれない。今回もところどころAIに相談してみちゃいるんだが、まぁ、こっちの伝え方が悪いのか、やりたいことがイレギュラーすぎてAIが理解してくれない所為なのか、サッパリ要領を得ない。こういうプログラムを作るというものも、ある種生成AIといえば生成AIではあるので、俺がどこぞの水の女神様並みに幸運値が低いからガチャで毎回ハズレを引き当て続けているんじゃないかというような気にもなってはいるんだけど……まぁ、単純に、あまりにもおかしな質問をしすぎたせいでAIが馬鹿になってしまっているだけなのかも知れないけど……まぁ、そんなこともともかく、そういうことなので、もちろんGlyphsでも手作業するなら同じ方法を使えば問題無くこのopentypecookbook.com謹製のfracのフィーチャーは動くのだけど、プログラムを手作業する場合フィーチャーを自動で生成というところのチェックをはずしておかないと後で悲しいことにはなるので……って、まぁ、そこもともかく、こういうことなのでフィーチャーの機能タグは何をする機能かということが決まってはいても、それを実現する方法はフォントの方に一任されているので、機能的な部分のどこを優先して、どの部分をどう解釈するのかはフォントに設置されているフィーチャーによって違ってくる。手品と一緒で、カードを当てるのでもコインの出し入れでも、見えている結果は同じでもどういうトリックが使われるかはいろいろなので、正解や方法が一つだけに限った話というわけでも無い。方向性が正しくても機能の不備や何かはあるだろうから、いずれはハイデルベルクを小澤で補完するような作業はどこかで必要になったりもするのかもしれないけど、ガッツリ本気を出しすぎてあまり方程式が複雑になっても処理に時間がかかって本末転倒にはなるのでこのあたりもバランス次第と言うことにはなる。まぁ、こんなのは当然当たり前でわかっていることだとは思うけど。
で、そんな具合に今回は時刻表示用のコロンを現出させるGSUBを使ったトリックの方法を考えてみる……というおはなし。

といっても、もちろんやることは単純で、上の図の下の下端がベースラインに揃っている普通のコロンを上の図の上のフォントのCaps heightのセンターに揃えたコロンの別のグリフと置換するだけなので、ここまでの説明が全く頭にはいっていなくても、どうすればいいかはわかると思うけど、まぁわからないという人がいると心配なので一応、その辺りのトリックを丁寧に説明すると以下のように、「まず、フォントエディターでUPPERCASEとLowercaseで垂直位置が問題になりそうなグリフを選択して、コピーを作成する。もとのグリフはxハイトつまり小文字のxの高さ……のセンター揃えになっているので、コピーのほうの垂直位置をキャップ高つまり大文字の高さ……のセンターに調整する。今回調整するのは下の図の13グリフ。まぁ、今回はFontLabを使用しているのでキャプチャーはこの絵面だが……やることはGlyphsであってもそれほどたいした違いは無い。


コピーしたグリフの拡張子はわかれば何でも良いけど、今回はUPPERCASE用のグリフと言うことで.caseということにした。つまりlessならless.case、colonならcolon.caseというそれぞれに異体字のグリフを追加する。グリフを作成したら、後で面倒なことにならないようにもとのグリフと追加したグリフのクラスをそれぞれでつくっておく。このとき、クラスの個数と順番はそれぞれでちゃんと揃えておくこと。これでそれらのグリフに異体字として大文字用のグリフが作成されたことになる。仮にもとのグリフのクラスを@PuncLow、コピーしたほうを@PuncUppだとすればフィーチャーはsub @PuncLow by @PuncUpp; で完了。念のため、sub 元のグリフ from [元のグリフ コピーされたグリフ] ;みたいな代替置換のペアの記述をフィーチャーのaaltにつっこんでおく必要はあるけど、まぁ、ここはfeature 何とか; でもなんとかなってしまうからって、このあたりはもう面倒なので後でまとめて解説を入れて置くからそのあたりはともかく、それで後はこのsub @PuncLow by @PuncUpp; というスクリプトを引き金にしたいフィーチャーのタグで括って完成。まぁ、そういう感じ。これだけなら簡単でしょ? ただ、今回のようにフォントのグリフネームの拡張子を.caseにしてしまっている場合、フォントエディタが自動でスクリプトを作成するモードになっていると、これらのグリフをフィーチャーのcaseのところへ勝手にリストしようとするので、このグリフの置換の引き金をcaseにしたくないというのであれば手作業でそこからはよけておく必要があるので……」と、くどくどとした解説になる……というか、これでもまだ、説明不足な気はするんだけど……まぁ、いいや、なんかそんな感じになる。
さて、これだけで済むならこれでもいいのだけれど、いくつかの条件でミッションをコントロールしようとすると、途端にいろいろ考えることがでてくるというのが厄介なところで、例えばこの機能が働いているとき、普通の文章を打っているときにはコロンの位置はそのままで、数字でコロンが挟まれた場合のみ時刻表時用にコロンの位置が移動して欲しい……みたいな条件が加わるというようなケースを考えてみると……まぁ、この辺りになってくると他のフィーチャーとの累積も考慮する必要がある。
一例を挙げれば、数字にオールドスタイルが指定されている場合には、コロンの位置を移動する必要は無いのだが、普通の数字……ライニング数字、等幅ライニング数字で時間が表示される場合はできればここはベースラインを弄ってやりたい……と、まぁ、そういうようなことを考えてしまった場合、この一行をどこに入れるかによってフォントの振る舞いが変わってくるみたいな話になってくるわけで、まず単純に考えてライニングもしくは等幅ライニング数字が指定される場合には、おそらくユーザーはそういう目的のために意図的に選んでいるのだろうと考え強制的にコロンをセンター揃えしてしまおうということで、その場合ならlnumかtnum若しくはその両方のフィーチャーにこのスクリプトを突っこんでしまう……まぁ、これならそこまで難しいはなしでは無い。
さて、問題は、そうでない場合に関してなんだけど、これに関しては完全にコンテキストに依存するので、その条件を見付けるところから考える……つまり、これらの仕組みの発動条件がアプリケーションやユーザーの打ち出すテキストなんかとどう組み合わさるのが都合がいいのかということで、コンテキスト置換のフローをどう設計し連除の手順を書き下したOpentypeFeaturesをどのフィーチャータグに突っこんだらいいのかというおはなしになる。コロンの前後若しくはどちらか片方が数字の場合にコロンの位置を変更するということを実現するだけなら、スクリプトは前方一致後方置換のsub @数字 colon' by colon.case; と後方一致前方置換のsub colon' @数字 by @colon.case;のどちらかもしくは両方があれば十分なんだけど、実用上ではそうしたくないケースとバッティングしないかとか、イレギュラーなケースはこれだけで済むのかとかということを考えたり、これをできれば勝手にやってくれる方がいいということもあったりすると、フォントを読み込んだ時点で完全にスイッチが入っている必要もあるので、そういう常時発動条件のあるフィーチャーを選んでおいて、そこに突っ込んでおくとか、まぁ、諸々と考慮する必要はある。
つまりはまぁ、スクリプト上のトリックはもとより、そうして作ったこのトリックをどこかのフィーチャーに仕込んでお客さんのために準備しておく必要はあるけれど、フィーチャーにもいろいろあるので、いきなり選べといわれても、ちょっと難しいところもあるかもしれないと、そういうはなしでもあるわけなんだけど……下手な説明を聞いて理解した気になって間違って変なところに突っ込んでおかれても、後々面倒なことになったりはするから……まぁ、そのはなしはいいとして、というようなことがあるからあまりいい加減な話ばかりしてると、本当にそこら中から怒られちゃうみたいな……いや、まぁ、もうすでに皆さんお怒りかもしれないんだけど……いずれにせよ真面目にやろうと思ったら巨大なフローチャートを仕上げてからキチンと検討していかないといけないということはある。え? 俺の話? うん、こっちはいつも通りの成り行き任せなのでまぁ、相当酷いことにはなっている。

ただ、既存のフォントエディタでは……例えばGlyphsでは、フィーチャーの横の+をポチってすれば以下のように誰が見てもわかるように説明がでるから、以下のように都合の良い物を選択してFeaturesに追加し、その中にいまのプログラムを追加すればOKで、このあたり、あまり難しいことも考えすぎる必用は無いというケースも多い。
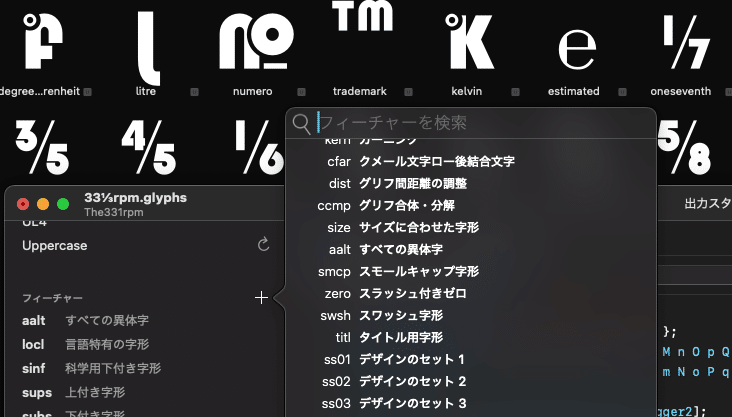
さて、そういうわけで後でも解説しておくけど、このようにフィーチャーのタグは、機能をどこどこでどのように実現するかという……まぁ、そういった決まり事はあるけど、かなりいろいろなところがユルユルなのも確かなので、そこさえ大幅に外れなければ、それこそ、そこそこに自由度は高い。どういう機能をどこで実現するのかというのは、やり方が複数あって、複数作っても構わないし、どれを選んでもたいした違いが無いみたいな……また、こんなことばっかり言っているから怒られるのだけど……また、多少実験的なことをしてみたいというのであればプライベートタグを作成するという方法もあるのだけれど、よっぽどのことが無ければss01-ss20をお薦めしておく。
それで、見ればわかると思うけど上のフィーチャーの項目のいくつかと、下の図のイラレのOpenTypeパネルの中の項目は対応しているものもあり、筺の中の白い鳩は……仮に例えばこのイラレのパネルで等幅ライニング数字を選択した場合では、フォントのFeaturesの中のtnumの中に記述されたプログラムの内容が呼び出され、そこから鳩が飛び出すというそういう仕掛けにはなっているから、真面目にいえば、あんまり無茶も出来ない。

といっても、このあたりはOpenType対応を謳っているアプリが、実はOpenTypeのFeatureの全ての項目に対応しているというワケでもないのでタイトル用の字形を作ったからFeaturesのtitlにリストしました……なんてことをしても使いたいアプリのほうにそこを判断する仕組みがないと……作業自体に意味が無いとまでは言わないけれど、残念ながら思ったようには機能しない。この辺は最近のノンデザイン系のデザインツールなんかも、OpenTypeの対応を謳っていても、いろいろなところが全滅だったりすることがあるので、どのFeatureを選べば良いのかは実際の運用を想定すると、ケースによっていろいろと変わる可能性があるので、実を言うと、そういうこともあって、Featureタグに関してはこうするとかああしろとか言うことが具体的なケースに即してではないと言いにくい面もある。とはいっても実際のトコロ、本当は、そんなんじゃ困るんだけれど……現状ではブラウザでのOpenTypeの対応が、Featureのどのタグが使えるかと言うことに対する適応が一番進んでいるように見えるけど、インデザインでHarfBuzzが効くようになってきたのでそのうちもっとましには……って、そこはいいか……ともかく、まぁそういうこともあるんだよね。

で、ダラダラと説明したけど、こういう仕組みなので、上のパネルで等幅ライニング数字を選んでも、今のはなしとは逆に、こんどはフォントほうにフィーチャーのtnumの記述がなければ当然何も起こらないし、間違って兎が入ってしまっている場合には、そいつが勝手に飛びだしてしまうということにもなる。ただ、アプリの方もしたたかで、鳩も兎も無視をして自前で必要な文字を作成してしまうプログラムを組み込んであって……みたいなことをする場合もあったりはするので、必要な作業をどうやって実現するかは、ここら辺もケースバイケースみたいなところもあるんだけれど。
ただ、そうはいっても最近のちゃんとしたOpenTypeフォントはそこらあたりはしっかりしてるから、期待通りの振る舞いをするようにはなってはいる。まぁでも、そんな感じのこともあるので、まだまだ全てのフォントに期待通りの振る舞いを要求されても、そういうふうになるように設計基準がキチンと決まっているわけではないし、品質管理におけるアレコレが自動車メーカーほどしっかりしているというわけでもない。大手食品メーカーというよりはそこら辺の安い外食店が軒を連ねているようなところもあるので、だから、たとえそうなっていないおかげで物事が上手く運ばず、上手くいかないので気分が収まらなくてイライラさせられたからといっても、𝕏で悪態をついたりするようなみっともない振る舞いをするのだけは勘弁して欲しいと思……あ〜、いや、なんでもないです。

というわけで、今回のオマケ。やっかいさを伝えようとするあまり本文はいつもの二割増しでかなりやっかいな文章になっているけど、オマケのほうもやっかいで、肝心要が終わっていないのに余計な事をやり過ぎている所為でゴチャゴチャしているので、いつも言うけど自己責任で。ぶっちゃけた話、ルールがどうこうとか、表記がどうたらとか、可能性のある使用方法に拘りすぎて、フォントにあまりにも複雑なプログラムを突っこみすぎてもかえって処理が煩雑になりすぎて、表示に時間がかかったり、思わぬところでエラーが出て処理が止まったり、揚げ句には仮に想定外のおかしな置換や移動が適用されたとしても今度はアプリの方で警告が出なかったりと、まぁ、いいことがあまりないので、こういう処理の要求が増えるようならフォントのFeature自体はなるべくニュートラルにしておいて、個別の実装はアプリでするか、includeで処理できるように、その旨フォントに記述して配布するか、include用のファイルの位置と名前を決めてユーザーが勝手に修正出来るようにその方法を一般化したほうがホントは良いような気もするんだけどね……まぁ、自分でやっておいて、今更こんなことをいうのも何なんだけど……。
The33-onethird-rpm 33⅓rpm_2.otf 465 Characters 765 Glyphs 39 Layout Features Opentype/CFF Format

OpentypeFeature構文についての解説
# コメント。まぁ説明するまでも無いとは思うけど……。
= イコール演算子。まぁこれも説明するまでも無いとは思うけど。
スペース。モノとモノとを区切るときに空白が必要になる。まぁ、説明入れるほどのことでもないけど。ただ、世界初のランダム可変フォント……で、いいんだよね……まぁ、その、多分、世界初の可変フォントFF Beowolfを作ったJust van Rossumのお兄ちゃんの設計した言語のように空白の量が違うと意味が変わってしまう……みたいなことにはならないので、こちらはそこのところに関してはそこまで厳密にする必要はない。スペースも改行も自由に組み合わせて使える。
ー ハイフン。AtoZのto。数値の前にスペース無しで置かれた場合は負の数値のマイナスの……って、まぁここも説明するほどでもないよね? もっとも、A-ZはそのままA B C D E F G H I J K L M N O P Q R S T U V W X Y Z なんだけど、zero-nineでは範囲がアルファベット順にないため有効なグリフと認められず 0 1 2 3 4 5 6 7 8 9 にはならないので 0 1 2 3 4 5 6 7 8 9 にしたい場合はハイフンを使わずに zero one two three four five six seven eight nine とフォントソースの名前で明示的に列挙するか、ハイフンをどうしても使いたいというのであれば、グリフが連番にパッケージされている必要はあるけど、そうなっていれば最初のキャラクターと最後のキャラクターのCIDの数値を拾ってきてバックスラッシュ数字 ハイフン バックスラッシュ数字ってやって結んでしまうやりかたもある。このとき数字とハイフンとバックスラッシュの間のスペースは例外的に不要になる……まぁ入れても良いけど。
; セミコロン。文章の句読点と同様にプログラム中の何かが終了するときに、そこに設置される。ただし、文章と違ってこのセミコロンに曖昧さは許容されてはない。
, コンマ。カンマとコンマはまぁ同じなんだけど、個人的にはプログラムの中のものをコンマと呼んでパンクチュエーションのカンマと区別している。たまにごちゃごちゃになることがあるけど……まぁそれはともかく、様々なリストの区切り記号としてコンマが使われるが、まぁだいたいは数値の区切りでテーブルのなんかだったり、ピクセル数がどうとかこうとかとかクリエイターが気に病んでもしょうがないトコロのアレだったりもするから、そういう意味では、多分ここでしているような話の時は、ほとんど出番はないので、まぁ大雑把には気にしなくても構わない。
' シングルクォーテーション。特定の条件でルールを発動させるための引き金。まぁ前回も荒い説明はしているけど、これを利用して文脈に依存する置換ルールを発動する。といっても先読み、後読みという正規表現的な話でAIがでてくるようなインテリジェントなものでもなんでもないんだけど……複数並んだコンテキストから変更させたい、もしくはignoreのところでも説明をいれるけどさせたくない箇所にマークして、マークした部分を置換する、もしくは置換しないというふうに働く、複数のルックアップやフィーチャーが絡み合うとこのあたりの機能の働きをどう先読みしてどうプログラムするのが都合が良いのかというところはある意味真骨頂ではあるのだけれど、ルックアップ内のシーケンスがコンテキストをどう理解するのかという部分の読みにも多少複雑な面はあって、コンテキスト置換というモノは、やっていくうちに文字通り「まるで将棋だな」というくらいワケのわからないモノに陥って「は?」となってしまうということにもなるという、その原因の一端にはなる。
" " ダブルクォーテーション。テキストなどを囲む。前にも説明したと思うけど、ss01-ss20ではフィーチャーの中にfeatureNames { name"好きな名前";}; で、好きな名前をダブルクォーテーションで囲んでおくと自由に好きなフィーチャーの名前がつけられる。まぁ、メニューをデフォルトの言語以外で表示させようとする場合、loclとかも考えないと駄目で、もうちょっと工夫とオカズも必要なんだけど、Glyphsの場合ではそのあたりは考えなくてもすむようにはなっている。
\ バックスラッシュ。この後ろに数値が続く場合、その数値が合っているのか間違っているのかは暗号表との突き合わせが必要になるので、多用するようならそれなりの装備品が必要になる。その暗号のことをCID識別番号と呼ぶ人もいる。
{ } ブレース、または中括弧。わかりやすく言うとプログラムの本体、つまりFeatureやLookupの内容を囲むために使用される。
[ ] ブラケット、または角括弧。これもざっくりとしたイメージで言うとリスト、配列、つまりクラスの内容を囲むために使用される。クラスは簡単に言えばグリフ等をフォントソースの名前でリストして並べたモノで、中身がどう並んでいようが基本的にはどうでもいいのだが、複数のクラスが相互に関係するというような場合には順番と個数はちゃんと揃える必要がある。フォント制作アプリによってはクラスの中をキチンと並べ替えてしまうというようなことをしてくれちゃってしまうことをするものもあるのだが、これをされると後で都合が悪くなったり……まぁ、その話はいいや、それで、このリストの区切り記号は他と同様に空白で区切られることになるので、間違ってもカンマなどの区切り記号は入れないように注意すること。
< > アングル、または山括弧。アンカーやレコード、その値や座標など、数値が絡むケースを囲むときに使用される。基本的に数値も空白を区切り記号に使うが、アングル内でリストが分かれる場合ではそこに区切り記号のコンマが打たれる……というようなケースになることもある。
( ) パーレン、または括弧。ファイル名を囲むために使用される。利用方法はincludeを参照。
@ アットマーク。ブラケットの先頭に@と適当な名前とイコールを付けることでクラスに名前を定義することが出来る。適当と言っても命名規則はプログラムの常識的なモノである必要はあるけど。で、クラスの割り当てはファイルのどこでおこなってもかまわないが、前置されている必要はある。クラスの中にクラスの割り当てをぶち込んで、@仮名 = [@ひらがな @カタカナ];のような定義も可能だ。まぁ、使っちゃいけない字を使っているので、命名規則的にはこれだと駄目だけど……まぁ、そこはわかるよね? あと、最後にセミコロンを付けるのだけは忘れずに。

aalt 代替グリフをセットするfeature。詳細はsubstituteのところで後述。
case 大文字用の字形を識別するfeatureのタグ。前にも言ったけどダイヤクリティカルマークでは小文字と大文字で形が変わることがあるので、そのための識別に使用されることがある。なので、これと親字の識別トリガーを一緒にしてしまうと別のところで問題が発生する可能性もある。キャピタル字形……まぁ、つまり大文字のバリアントには他にもsmcp:スモールキャップ、c2sc:キャップトゥスモールキャップ、unic:ユニケース、pcac:プチキャップtitl:タイトルケース等々があり、それらをどう反応させるべきなのかは細かい事をいいだすと結構曖昧だ。スモールキャップとプチキャップみたいに何が違うんだか意味がわからないと……まぁ、それはいいとして、そういうこともあるので、font-variant-capsのプロパティの一致規則にキチンと対応させるのは面倒なことも多い。ブラウザによってはこのあたりがフォントデータ内に存在しない場合、勝手に大文字から合成して表示するなどという仕組みになっていたりすることもあるから気にしないというのであれば気にしなくてもいいようにはなっていたりもするので……あと、これをいっちゃぁお終いだけれど、賢いブラウザでは時刻表示のコロンの位置は勝手に修正される。
feature 四文字の識別タグで区別され、一応こうしなさいというルールが決まっている。ルールから外れた場合はプライベートタグと判断され、それも一応使用することはできるのだが、よっぽどのことが無い限り使用は推奨されてはいない……というかルールに沿った名前が使用されていないというだけで後で大変困ったことにはなる。識別タグはアプリケーションの側からはその機能を発動するための引き金になっているからだ。まぁ、そのためアプリの側からは自分に必要の無い引き金を間違って引かないように、余計な識別タグに反応しないような仕組みに出来上がっているものもある。と、まぁそういうわけで、フォントには必要なfeatureだけがあればよくて、必要が無ければメモリー使用量も馬鹿にならないのでなるべく使用しない方向で……などと言われることはある。まぁ、今回は気にしちゃいないのだけれど……さて、それで、フォントに複数のfeatureが存在する場合、この並べ方にもガチガチにキマリがある……というわけでもないのだが、プログラムの内容は先頭から順番に処理されるので、どういう順番で並べるかによって結果は大きく違ってくるから、必然的に並べる順番は決まってくるというようにはなっている。識別タグの種類と内容は以下参照。
frac/afrc それぞれ、fractionおよびalternative fraction、数字を分数にして出力するときに利用されるフィーチャのタグ。本文では紹介しなかったけど、これを実現するために本文で説明したようなやり方で分母用と分子用の数字を自動的に組み合わせる方法以外にも、単純な合字置換で実現させるやりかたもあって、分数の分だけグリフを沢山作る手間をおしまなければスクリプトは簡単になるので、そういうふうにプログラムされているフォントも存在する。まぁ、このあたりのトリックも実は色々あって解説しようと思ったらいくらでもはなすことはあるのだけれど長くなるのでまたそのうち。

ignore 例外。コレに続けて処理の内容を記述すればその部分だけは全体の処理から例外として扱われる。プログラム的な言い方をすれば、コレでマークされた位置でルックアップの処理が終了する。例えば ignore sub 何ちゃら; sub 何とか; みたいなルックアップは何とか置換から置換対称が何ちゃらのケースのみ除外するというように働く。具体的には小文字を大文字に置き換える「sub @小文字 by @大文字; 」のようなスクリプトがあるとして、そこでiPHONEのiの場合だけは例外的にiPHONEという表示にしたいというような場合、「PHONEの前のiを例外として、全ての小文字を大文字に変換する」というようにプログラムの文法を整理して、ignore sub i' p h o n e; sub @小文字’ by @大文字; というようにiの後ろにシングルクォーテーションを打って、コンテキスト置換としてタイトル表示用のfeatureに記述する。こうしておけばOpenTypeに対応したアプリのほうでは「iPhone15. Forged in titanium!」というテキストににタイトルの表示のフィーチャを働かせた場合テキストがちゃんと「iPHONE15. FORGED IN TITANIUM!」と置換される。というか、まぁ、そういうフォントが作成できる。
include 外部参照。つまりフォントファイルの外に拡張子.feaでフィーチャを保存しておいて、フォントの側からこのファイルを参照して個別のカスタマイズされたケースに対応しようという作戦だ。書式はinclude(otf.fea);でotfの所は名前さえ間違っていなければどういう名前でも構わない。パスはフォントファイルの位置からの相対……え? http://? う〜ん、試してはいないのでわからないけど、それはなんとなく悪い予感しかしない……。
lnum/tnum/onum/pnum…… まぁ、数字に係るフィーチャもやたらあるので一々覚えていられないのだけど、というかあまり必要の無いフィーチャとか、俺自身がそもそも何をするものなのかすらよくわかっていないという物とかもいろいろあるので……まぁ、あとはお察し下さい。
locl 言語ごとの固有の状況を反映するためのfeatureのタグ。Opentypeの売り文句の一つに優れた言語処理というものがあって、それを実現するために、各言語ごとにカスタマイズされた固有のルールを定義することが可能になっているから、そのあたりを実現するために必要なスクリプトをここへ入れておく。この部分も説明しようとするだけでも相当にやっかいなんだけど、以前にも少し説明したような気にもなっていることだし、まぁ、ちょっと話が長くなることもあるのでまた今度。
lookup まぁ中身はほとんどfeatureと変わらないのだけれど、featureと違って名前は4文字に限定されないので常識的な命名規則……つまり、31 文字以内で、A-Z,a-z,0-9とピリオド、アンダーラインのようなプリミティブなプログラムで利用される普通の文字のみを使用して、スペースで間を開けない、数字やピリオドで始めない……みたいなことに則っていれば、文字数もネーミングも限度はあるけど好きなように付けられる。構文が前置され、定義より後ろからであれば他の箇所から呼び出して内容を再利用するというサブルーチンのような使い方もできるのだが、一つの構文の中で異なるタイプのルックアップを適用できないとか変数を組んでそこに別の値を代入するみたいなことがダメだとかルックアップを複雑に連鎖させるとテーブルのスペースというか、データー量が65535バイトを超えてしまいフォントの書き出しで失敗するとか、そうならないようにuseExtensionすると、こんどはそれをまったくサポートしていない……まぁともかく、そんな感じのこともあるので常識に則した注意は必要だ。ただ、そのあたりに気を配っておけば、ひとつのfeature内に複数のlookupを使用することに問題は無い。feature同様プログラムのハンドリングは次のlookupに進む前に前の処理を完了するという流れになるので、どういう順番で並べると都合がいいかは……まぁ、本文中でも言及してるし、後ははなしが長くなるからここもまたそのうち。
onum 本文ではオールドスタイルの数字のフィーチャはこの名前で決定する。などと書いているが、あれも実は半分は嘘だ。まぁ、毎回いい加減なことしか言ってないからと言い訳しているので今更騙される人もいないだろうけどフィーチャの数字に関わる識別タグに関しても、それだけで一本記事が書けるほど煩雑なので、まぁ、ここも、気が向いたらまたそのうち。
position 位置。ポジショニング、省略形はpos。前回やったので簡単に説明すると、大まかに8個ほどの種類はあるのだが一般的に実装もされていて説明しやすいのはシングル調整とペア調整の二つだ。それぞれGPOSルックアップTYPE1とTYPE2と呼ばれている。もっともTYPE2はほぼほぼカーニングにしか使用されないので、フォント作成の為のソフトを利用している場合はほとんど考慮する必要はない。また、TYPE1は前回の話。まぁ今回はGSUB回なうえ、ポジションの話は前回もしたので、ここの詳細もまたそのうち……しかし、あとで説明するからと言って解説を先延ばしにし、今になって何とかやっと説明し終わったと思ったら、さらに講説入れなきゃいけなくなるところが三つも四つも増えてくるという、この負のスパイラルもなんとかしなきゃとは思っちゃいるのだが……。
size OpentypeFeatureは置換と位置決めだけだ! などと大言しちゃっているけど、実をいうとそれに当てはまらない機能も存在する。その一例がこれなのだが……まぁ、名前からなんとなくはわかると思うけど、オプティカルな話にも関わるので面倒くさい……まぁ、それでも、ここも広い意味に取れば置換と言えなくもないんだけれども……。
ss01-ss20 スタイリスティックサブスチュエーションセット。別名スタイル機能ともいうあれだけれども、ここを使えばイラレのようなソフトからでもカスタマイズしたFeatureを個別に呼び出すことが可能なので、アプリが固有のFeature nemeの引き金に反応しないので、このフィーチャーは使えない……みたいなケースの場合には機能をここをバイパスすることによって利用可能にするというバックドアとしての働きも……まぁ、そんなことしても大丈夫かどうかの保証は無いけど。
substitute 置換。substitute 置 by 換; で、置を換で置き換える。対称のグリフ、もしくはクラスが前、置き換えた後のグリフ、もしくはクラスが後で、その間を by で繋ぐ。ただ、毎回substituteと書くのも面倒なので、通常はsubと省略される。置換にも8種類があるが、説明が単純に済むモノと面倒なモノの二つに分かれる。単純なほうから説明すると、単一置換:一つを一つと置き換える、複数置換:一つを複数と置き換える、代替置換:一つに複数の選択肢を与える、合字置換:複数を一つと置き換える……となりそれぞれ順にGSUBルックアップのTYPE1、TYPE2、 TYPE3、TYPE4というふうに分類する。この4つのルックアップのタイプのうちGSUBルックアップTYPE3だけはフォントに代替をセットするだけのことしかしないので、実際の置換はユーザーが手動で行うという仕組みになる。そのため、スクリプトも sub ■ by ● ;ではなくてsub ■ from [■ ●] ;とバイがフロムになり置き換える予定のグリフはクラスで指定してある必要……つまりブラケットの中に列記するか、@で始まる名前になっている必要がある。また、これが必要となるfeatureのaaltでは、同様の仕組みを特別に処理される機能ルールを使ってフィーチャー内に使用されているフィーチャー名を列記して
featureaalt { feature xxxx; feature xxxx; feature xxxx;….. } aalt;
としておけば、後は代替置換の分類も含めていろいろ宜しくやってくれるというような仕組みにはなってはいるから、よくわからなかったら忘れてしまっても構わない。自分で追加することが必要になるケースもあったり、フォントエディターがうまく代替を出力できなくて結局手作業で修正する必要が出てくる場合もあるから覚えておいても損は無いけど……まぁ、フォントのグリフの代替は結構複雑に絡み合っていたりすることがあるので、本音を言えばこれを手作業で修正するというのはできればやりたくないという作業の一つだ。まぁ、ともかくそこを除けば、置換というのはとにもかくにも基本はsub A by B;で、それだけ覚えておけばとりあえずはなんとかなる。

さて、で、あと面倒な方の残りの四つは、文脈に依存して、もうちょっと複雑な置換も出来るようにするという仕組みなんだけど、まぁ本文の方でも分数をどうするかという話の中で少ししたので、感のいい人ならわかると思うけど簡単に言えばやりたいことを何時やるかの定義をどうするかという手続きの問題。まぁ、いろいろあるんだけど、とはいっても、Opentypeでは多数対多数を一遍に置換することができないので、そういうことが必要で、そう見えるようにするためには、さらにいろいろなトリックが必要になる。まぁ、そのあたりは面倒なのでまた別の機会にでもするとして……話を戻すと、それで本文でも言ったけど……いったよね? 言ったような気もするけど、まぁもう一回言うと、Opentype対応を謳っているソフトウエアでもアプリケーションによっては特定のタイプにプログラムが対応していない可能性もあるので、このあたりは8つのタイプのどのあたりに反応するかどうかの見極めには注意がいる。これはさっきのss01-ss20で機能をバイパスさせようがなにしようが、そもそもルックアップそのものをアプリが理解していないために起きる現象なので、引き金をどこに置こうが無意味なんだけど、このあたりもちゃんと説明しようとすると本当に面倒になることと、書いた原稿量もまた大分長くなってきたので、続きは……これもまたそのうち。
この記事が気に入ったらサポートをしてみませんか?