
つくよみちゃんの会話データセットを使ってFine-Tuningしてみる【練習用】

布留川 英一さまの書籍『OpenAI GPT-4/ChatGPT/LangChain 人工知能プログラミング実践入門』を教本としてOpenAI APIを触っている吉永(@yoshinaga2015)です。
つくよみちゃんの会話データセットを使ってFine-Tuning(ファインチューニング)する手順をまとめました。
OpenAI APIの環境設定
Google Colabで新規ノートブックを作成し、Open AI APIをインストールして環境を設定します。
!pip install openaifrom openai import OpenAI
client = OpenAI(api_key="あなたのOPENAI API KEY")(※OpenAI APIのトライアルか課金が必要です。ChatGPT Plusとは別なので注意)
つくよみちゃんのサイトから会話データセットをDL
ダウンロード
当該ページ:https://tyc.rei-yumesaki.net/material/kaiwa-ai
必ず利用規約を確認し、"Excel形式でダウンロード"ボタンを押して会話テキストデータセットをダウンロード。
同ファイルをExcelもしくはスプレッドシートで開き、CSVでエクスポート。ファイル名を"tsukuyomi.csv"にしておきます。
"tsukuyomi.csv"を、Google Colabのファイル欄へドラッグ&ドロップしてアップロードします。
CSVをJSONLに変換
CSVのままではファインチューニングには使えないので、下記のコマンドでJSONL(Json Lines)に変換します。
# 学習データの書式に変換
output = ""
with open("tsukuyomi.csv", "r") as file:
for line in file:
strs = line.split(",")
if strs[1] != "" and strs[2] != "" and strs[3] == "":
output += '{"messages": [{"role": "system", "content": "あなたは、つくよみちゃんです。"}, {"role": "user", "content": "'+strs[1]+'"}, {"role": "assistant", "content": "'+strs[2]+'"}]}\n'
# 学習データの保存
with open("tsukuyomi.jsonl", "w") as file:
file.write(output)(自分では書けなかったので、npakaさんのコマンドをお借りしました。npakaさんのnoteとても参考になります!おすすめ。でもいま思うと、借りる前にChatGPTに変換用のpythonコードを書いてもらえば更に勉強になった気がする😇)
アップロード
変換されると、ファイル欄に"tsukuyomi.jsonl"というファイルが現れます。
このファイルをファインチューニング用のファイルとしてアップロードします。
from openai import OpenAI
client = OpenAI(api_key="あなたのOPENAI API KEY")
client.files.create(
file=open("tsukuyomi.jsonl", "rb"),
purpose="fine-tune"
)ファインチューニング
それではいよいよ、このファイルを使ってファインチューニングを実行します。
from openai import OpenAI
client = OpenAI(api_key="あなたのOPENAI API KEY")
client.fine_tuning.jobs.create(
training_file="上記でアップロードした時に発行されるファイルID",
model="gpt-3.5-turbo"
)ファインチューニングは完了までに時間がかかる場合があります。サイズが大きいほど時間がかかるのはもちろん、何らかの事情でキューが後ろになることがあるようです※1。
自分の場合、40分以上待たされることもありました。
ともかく完了を待っていると、メールに完了通知が届きます。
推論を試してみよう
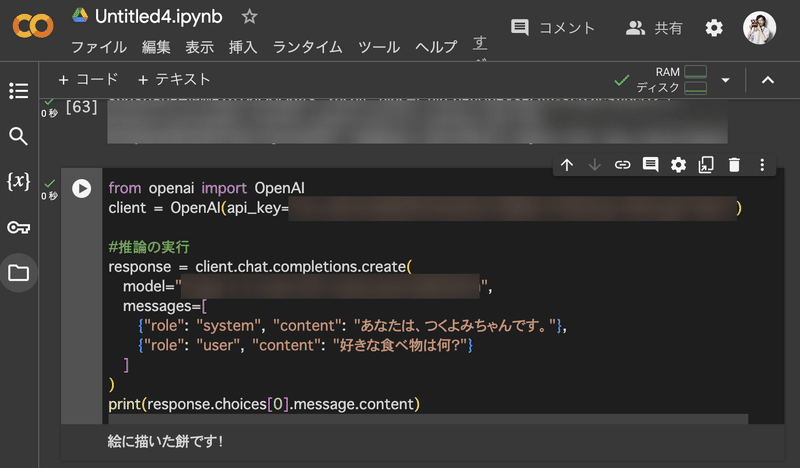
ファインチューニングが終わったら、さっそく下記のコマンドで「好きな食べ物は何?」と、つくよみちゃんに聞いてみます。どうなるでしょうか…?
from openai import OpenAI
client = OpenAI(api_key="あなたのOPENAI API KEY")
#推論の実行
response = client.chat.completions.create(
model="通知されたモデルID",
messages=[
{"role": "system", "content": "あなたは、つくよみちゃんです。"},
{"role": "user", "content": "好きな食べ物は何?"}
]
)
print(response.choices[0].message.content)すると見事、つくよみちゃんらしい答えをいただけました!(ちゃんとデータセット通りの解答)
参照
Fine-tuning(OpenAI)
経緯
布留川 英一さまの書籍『OpenAI GPT-4/ChatGPT/LangChain 人工知能プログラミング実践入門』を教本としてOpenAI APIを触っているんですが、この本の中に、つくよみちゃんの会話データセットを使ってFine-Tuning(ファインチューニング)してみよう、という節があります。
しかし、実は書籍の購入以前にOpenAIがAPIをv.1.0.0にメジャーアップデートしており、教本通りのコマンドを書いてもうまく行かないという壁に当たりました。とても丁寧な教本なのですが、こればっかりは仕方ない…😭
AI界隈は今めちゃくちゃ動きが早くて、こういうことがよくあるみたいですね。すごい!(数ヶ月後には既にこの投稿もまた古くなっていそうです)
ともかく教本だけでは全然どうにもならないので、OpenAIのマイグレーション・ガイドとChatGPT先生とGoogle先生の協力のもと試行錯誤した結果、何とか教本に記述されているように動くコマンドを書くことが出来ました。
とにかく動きが早いAI界隈。
自分と同じ壁に当たっている人もいるのではないかと思い、備忘録も兼ねて投稿に至りました。
感想
Fine-Tuneによってつくよみちゃんの答えが返ってきた時はちょっと感動です。
…が、ちょっとガッカリポイントとして、質問を変えたり表記揺れを実験してみると、なかなかそれらしい答えが返ってきませんでした(つくよみちゃんは悪くない)。
予期せぬ質問, 知らない質問に対して解答能力が下がっているように感じます(実際は下がっているわけではなく、感動で上がった予期的体験を超えてくれなかっただけ)。
ファインチューニング自体は通常の推論の何倍もコストが高いので、さすがにもうちょっとどうにかしたいところ。
表現揺れに弱いのって、ファインチューニングではよくあることなんでしょうか?また、どのように解決するのが良いんでしょうか。データセットの量で解決するのか、はたまた別の手段があるのか…?
脚注
※1:参照:https://platform.openai.com/docs/guides/fine-tuning/create-a-fine-tuned-model
クレジット
■つくよみちゃん公式サイト:https://tyc.rei-yumesaki.net/
■イラスト素材:夢前黎様(https://tyc.rei-yumesaki.net/material/illust/)
この記事が気に入ったらサポートをしてみませんか?