
強化学習で遊ぶ part1 AIが育つ「強化学習」の面白さ

こんにちは!ナガメ研究所です。普段はポーカーAIの開発をしています。ポーカーを通して強化学習というものの面白さを伝えたいのですが、なかなか思うように開発が進められていません(ポーカーって難しい・・・)
そこで、もっと身近で面白そうなテーマをいろいろつまみ食いして、その発見をお伝えする強化学習で遊ぶシリーズを考えました。このシリーズでは、ナガメ研究所の博士と助手、ナガメの3人に強化学習の紹介をしてもらいます。難しい数式や計算は省き、なるべく理解しやすい用語で解説します。AIや強化学習についてご興味のある方、ぜひご覧ください!

はじめに

博士じゃ。2022年のFIFAワールドカップ、面白かったの~~。なので今日は我が研究所のスーパーAI”ナガメ”にサッカーを覚えさせて、AI選手だけのワールドカップを開こうかの。


助手です!面白そうですね!・・・でも博士、私AIもサッカーの戦法も全く知りません。サッカーをするAIなんて作れるかな・・・・。


強化学習のポイントさえ知っていれば大丈夫じゃ。さっそく解説していくぞい。

強化学習

そもそも強化学習とはなんぞや?じゃが、AIが特定の問題を解決するために必要なパラメータを探索する手法のことを指すのじゃ。


ちんぷんかんぷんです。特定の問題ってなんですか?


実は、この問題を設定することが重要なポイントの一つじゃ。今回はサッカーの対戦を想定しよう。サッカーの勝敗は、相手より多くの得点を決めることじゃ。つまり、ゴールを決めるためにどんな行動をすればよいのか?を考える必要がある。これが問題じゃ。


サッカーを、そういう問題ってことにして、考えるんですね。パラメータを探索というのは?


パラメータとは、モデル内で使われる数値のことじゃ。モデルとは、入力データに対する出力をするコンピュータだと思えばよいかの。
実際に学習する様子を見てもらったほうが早い。さっそく、サッカー場へゆくぞ。

学習環境


UnityのML-agentsのサンプルをお借りしているぞ。
強化学習を理解するには、環境、観測、行動、報酬という単語と関係を把握することが重要じゃ。上の写真は、AI”ナガメ”にサッカーをしてもらう様子じゃ。”環境”とは、壁であったり、ボールやゴールがある”世界”の事を言う。


(よく見たらナガメのお面してる・・・)



次に環境を観測するのじゃ。見える範囲の位置情報をモデルの入力とする。壁やボール、ゴールの他、味方や相手の位置も観測データとなるのじゃ。Unityでは、赤い線上にあるオブジェクトがナガメの見えている範囲じゃな。

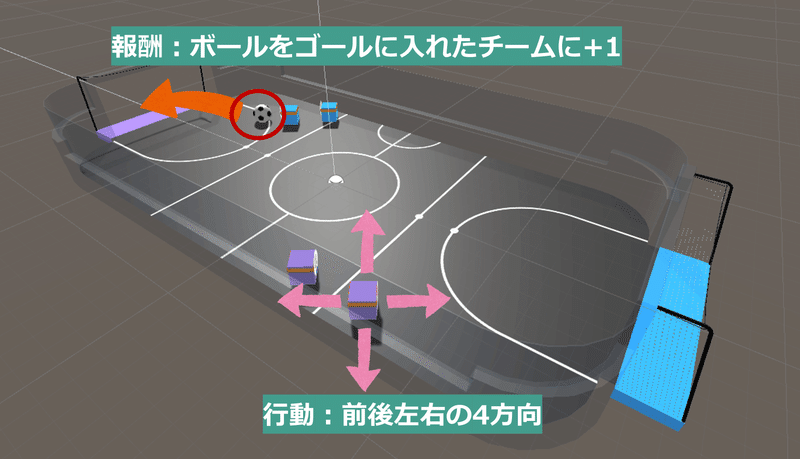

ナガメはこの環境を前後左右に行動できる。ボールをゴールに入れることでプラスの報酬を得る。逆に入れられたチームはマイナスの報酬を得るのじゃ。報酬が沢山もらえるようモデルのパラメータを調整することで、良い行動を学習するのじゃ。
これが、環境・観測・行動・報酬の流れじゃな。


これだけなんですね~。どれくらい学習すると良いんですか?


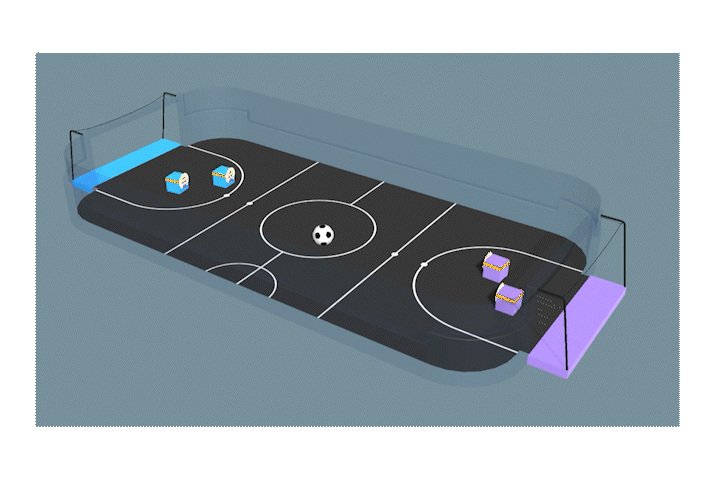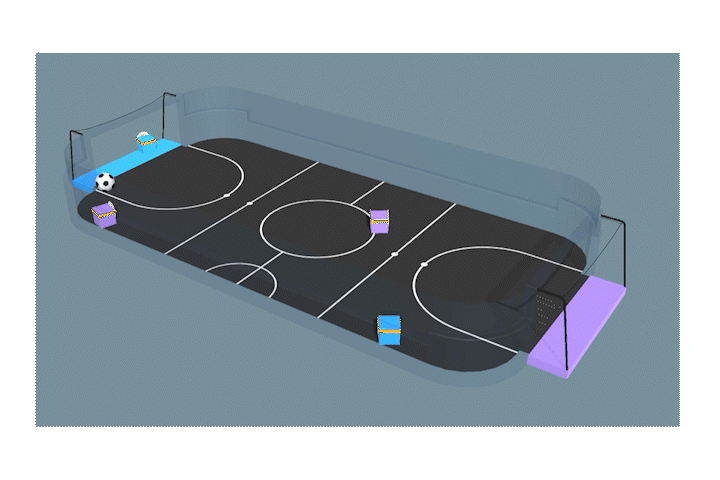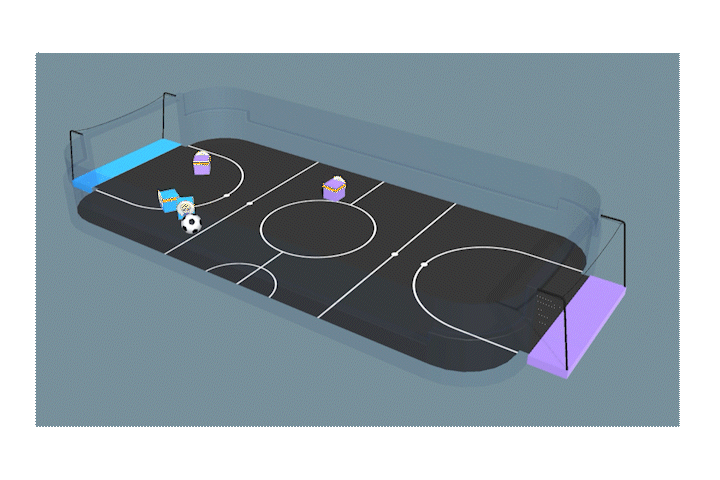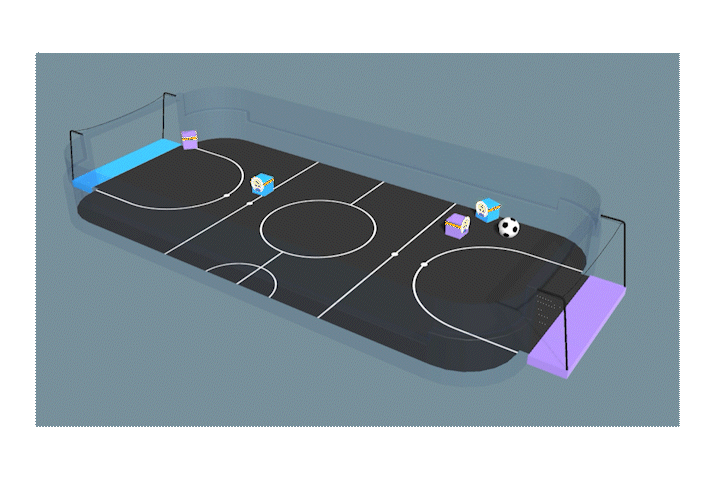
良い質問じゃ。学習の流れでも話した通り、モデルへの入力は環境の情報だけじゃ。良い行動が何かは報酬がもらえたかどうかで決まる。つまり、最初は目的であるゴールすら分からない状態なのじゃ。学習の初期段階の様子を撮影したので見てみるかの。



ありゃりゃ。ゴールどころか、ボールに見向きもしていませんね。


最初はランダムに動いてばかりで、得点はできていないの。じゃが、沢山の試合を経験すると、たまたまボールがゴールに入ったり、入れられたりする。この積み重ねで、良い行動・悪い行動を学習するのじゃ。さて、後は茶でも飲んでのんびり待つとしよう。

~~~数時間後~~~
学習結果

博士!そろそろ見てみましょう!


相手のゴールに入れることに成功しておる。学習は成功じゃな。



こっちはゴールの前に立ってキーパーのような役割をしているナガメもいますね!何も教えてないのに、すごい!


このように、強化学習を使うことでサッカーの問題を解くことができた。しかし、ご覧の通り”非常に簡略化された”学習環境じゃ。人数はたった4人じゃ。相手にぶつかってもOK。オフサイドやペナルティもない。
こういったルールや設定も、環境の一部じゃ。ぶつかった場合はマイナスの報酬を与えたり、PKを行うこともできる。


ナガメ?はまだ四角のキャラクターですが、足を使ったりヘディングしたりできるんでしょうか?


関節の動きも強化学習で獲得することは可能じゃ。しかし、沢山の関節の角度を決定するのは非常に難しい問題になるので、工夫が必要じゃの。そういった発展問題も、そのうちやっていこうかの。

おわりに

さて、今回の実験はここまでじゃ。ちと補足じゃが、今回のサッカーAIは”self-play”といって、AIが自分自身と対戦して強くなる強化学習手法の一つじゃ。対戦以外にもいろんなタスクをこなす複数の学習方法があるのじゃ。
今日触ったサンプルは、無料で使わせてもらえることができる。興味がある方はサンプルをカスタマイズして新しい問題を設定し、強化学習を使ってAIに解いてもらいたい。とても面白いぞ!


ありがとうございました。私もモンダイセッテイしてみます!

この記事が気に入ったらサポートをしてみませんか?