
プログラミング素人が2030年までの日本の人口減少数を予測!

5/12(木)9:00 AM 、イーロン・マスク(Elon Musk)が日本の出生率に注目し、人口を増やす努力をしなければ、日本は消滅の危機にあると警告。
(https://www.businessinsider.jp/post-254073)
そこでプログラミング初心者であるHorikawaMiyabiは、イーロン・マスクの発言を可視化することを試みた。将来的にどの程度の人口が減ってゆくのか?について、厚生労働省人口動態調査データと総理府統計局『第15回日本統計年鑑』(昭和39年版)より1899-2020年までの人口増減データを取得し、2020-2030年までの日本の人口増減値を予測し、その理由を考察してみた!
目次
1.PC環境
2.使用したデータ
3.私のレベル
4.やったこと
5.日本の人口減少に対する考察
6.反省点
1.PC環境
Microsoft Surface
Google Colaboratory
iPhone使用したデータ
2.使用データ
厚生労働省人口動態調査データおよび総理府統計局『第15回日本統計年鑑』(昭和39年版)より1899-2020年までの増加人口データを抽出
3.私のレベル
全くのプログラミング初心者
4.やったこと
1. 厚生労働省人口動態調査データおよび総理府統計局『第15回日本統計年鑑』(昭和39年版)から1899-2020年までの人口増減データを抽出。
2. Google Colaboratoryを使い、1899-2020年までの人口増加データを用いてSARIMAモデルを作成、1957-2030年までの人口増加データの予測値を算出。
( 時系列解析 I 統計学的モデルに従い解析 )
3. 1957-2020年の実測値・予測値の人口増加数のフィッティング具合により、その妥当性を検証するとともに2021-2030年までの人口増加数を予測。
#1 Google colaboratoryのマウント
#2 解析に必要なPython3ライブラリを読み込む
#3 データの読み込み
#4 データの整理
#5 人口の数値化
#6 orderの最適化関数
#7 SARIMAモデル構築
#8 予測値の計算
#9 グラフの可視化
#10 グラフのプロット
from google.colab import drive
drive.mount('/content/drive') #1 Google colaboratoryのマウント
Google Colaboratoryでcvsファイルを読み込めるようにマウント
#ライブラリの読み込み
import warnings
import itertools
import pandas as pd
import numpy as np
import statsmodels.api as sm
import matplotlib.pyplot as plt
%matplotlib inline#2 解析に必要なPython3ライブラリを読み込む
#データの読み込み
population = pd.read_csv( filepath_or_buffer="/content/population.csv",
dtype={'x02': 'float64'}) #3 データの読み込み
cvsファイルを’/content/drive'に入れるとなぜかエラーが出て読み込めない。’/content’に直入れで読み込みが可能になった(とりあえず決)
#データの整理
df = pd.DataFrame([[1944, "519,862"], [1945, "519,862"], [1946, "519,862"]],
columns=["Year", "population"])
population = population.dropna().append(df)
# indexに期間を代入してください。期間は"1899"から"2020"としてください
population.index = pd.to_datetime(population["Year"].astype("int").astype("str"))
population = population.sort_index()
# populationの"Year"カラムを削除してください
population = population.drop("Year", axis=1) #4 データの整理
(1944年、1945年、1946年は第二次世界大戦の影響によりデータが欠損、
1943年の1/2の値で代用した)
#人口の数値化
population["population"] = population["population"].str.replace("[,\(\)]",
lambda m: "-" if m.group(0) == "(" else "", regex=True).astype("in)
#5 人口の数値化
文字認識していたデータを数値に変換。csvファイルから読み込んでいたマイナス値に()値に変換されており苦戦。きちんとマイナス値になるように変換。チューターの方に多大なるお手間をかけてしまった。
#orderの最適化関数
def selectparameter(DATA, s):
p = d = q = range(0, 2)
pdq = list(itertools.product(p, d, q))
seasonal_pdq = [(x[0], x[1], x[2], s) for x in list(itertools.product(p, d, q))]
parameters = []
BICs = np.array([])
for param in pdq:
for param_seasonal in seasonal_pdq:
try:
mod = sm.tsa.statespace.SARIMAX(DATA,
order=param,
seasonal_order=param_seasonal)
results = mod.fit()
parameters.append([param, param_seasonal, results.bic])
BICs = np.append(BICs, results.bic)
except:
continue
return parameters[np.argmin(BICs)] #6 orderの最適化
ベイズ情報量基準によりSARIMAモデルパラメーター(p, d, q)の最適値を計算
#モデルの構築
# SARIMAモデルを用いて時系列解析をしてください
# 周期はs=12とした
# orderはselectparameter関数の0インデックス, seasonal_orderは1インデックスに
格納されています
best_params = selectparameter(population, 12)
SARIMA_population = sm.tsa.statespace.SARIMAX(population,order=best_params[0],
seasonal_order=best_params[1]).fit()#7 SARIMAモデル構築
#予測
# predに予測期間での予測値を代入してください
pred = SARIMA_population.predict("1957", "2030")#8 予測値の計算
#グラフを可視化してください 。予測値は赤色でプロットしてください
plt.plot(population)
plt.plot(pred, color="r")
plt.show()#9 グラフの可視化
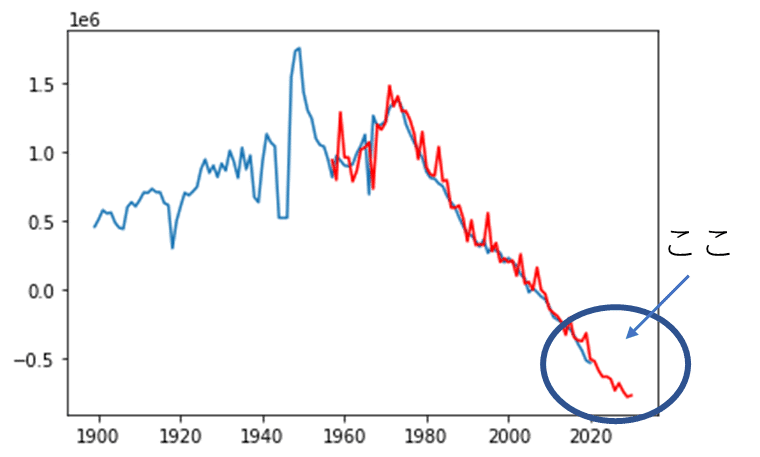
5.日本の人口減少に対する考察
a) 1899-1949年頃までは概ね50-100万人/年の割合で人口増加。1943-1945は第二次世界大戦の影響で人口増加が止まる。1947年以降、数年は戦地よりの日本の兵隊さんの帰国により、第一次ベビーブーム到来により170万人/年まで人口増加。
b) 第一次ベビーブームで誕生した方々が成人して子供を作る1970年代以降に第二次ベビーブーム到来。再び人口増加数が増加。
c) 本来であれば、1995-2000年ぐらいに第二次ベビーブームで誕生した方々が結婚適齢年齢に達し、第三次ベビーブームが起こるはず! であった。
d) しかし、そうはならなかった。結婚適齢年齢では結婚するもの!という考え方が変わり、結婚しない方も増えてきた。
e) 1990年ごろにバブルが崩壊し、日本全体が貧しくなったたため、子供を2人以上育てることが難しい、と考える方々が増えた(Double income no kidsなどの言葉が1990年代に流行、子供が一家庭から二人育って現状維持)。
f) 日本の戸籍制度が最悪!日本では婚外子を認めない戸籍制度になっており、結婚が前提、婚外子の割合は全体の2%程度しかない。
g) 一方、ヨーロッパは50年前に結婚を前提とした婚外子の戸籍制度を廃止、現在では全体に占める割合は40%程度だという。
h) 人口の増減は嘘をつかないので今日明日にすぐに成人が増えるわけではない。
i) 上記のシュミレーションによる予測値では、2030年までに600万人以上が減ってしまう計算。現在の大阪府の人口と同程度か?
j) 日本でも早急に移民を受け入れること、戸籍制度の改定などを議論してゆく必要がある。
6.反省点
色々なデータがあり、もっと高度な解析ができれば見栄えもよくなったであろうと考えた。データの読み込みなどで手間取り、アイデミーのチューターの方にお世話になりすぎて申し訳なかった。
この記事が気に入ったらサポートをしてみませんか?