
【NISHIKAコンペ】債務不履行リスクの低減

今回のSIGNATEQuestは債務不履行リスクの低減!
Colaboratoryで行うのでまずはデータのマウントから
from google.colab import drive
drive.mount('/content/drive/')
#そして使いそうなライブラリ
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error as MSE
from pydrive.auth import GoogleAuth
from pydrive.drive import GoogleDrive
from google.colab import auth
from oauth2client.client import GoogleCredentials
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import LogisticRegression
import seaborn as sns
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import confusion_matrix
from sklearn.feature_selection import SelectFromModel
import cv2流れは、前処理をした後、オブジェクト行は削除。
不要な列はL1正則化で削除という感じです。
可視化は練習のときにわかっているのでしませんでしたが、可視化の結果として不要なものを削除はしませんでした。
試しにL1正則化で選んでも良いのでは?と思って可視化した結果で不要と判断しての削除はしませんでした。
import pandas as pd
train = pd.read_csv("/content/drive/My Drive/SIGNATE_saimu/train.csv")
test = pd.read_csv("/content/drive/My Drive/SIGNATE_saimu/test.csv")
sample_submit= pd.read_csv("/content/drive/My Drive/SIGNATE_saimu/submit.csv",header=None)目的変数のユニークの確認、クエストでは他に返済中のステータスもあったけれど。
train["loan_status"].unique()>>array(['FullyPaid', 'ChargedOff'], dtype=object)
今回は2種類返済完了と不履行のみでした。
#一緒に処理するために
train_test = pd.concat([train,test],ignore_index = True)目的変数のラベリング
def loan_status(x):
if "FullyPaid" == x:
return 0
elif "ChargedOff" == x:
return 1
else:
return -1Nanは-1に変換する。
def term(x):
if "1 years" == x:
return 1
elif "0 years" == x:
return 0
elif "2 years" == x:
return 2
elif "3 years" == x:
return 3
elif "4 years" == x:
return 4
elif "5 years" == x:
return 5
elif "6 years" == x:
return 6
elif "7 years" == x:
return 7
elif "8 years" == x:
return 8
elif "9 years" == x:
return 9
elif "10 years" == x:
return 10
else:
return 6勤続年数の文字は上記で変換Nanは中央値でだした6で入れる。
#これで計算した ↑
mean_a = train_test.dropna()
mean_a = train_test["employment_length"].apply(term)
mean_a.mean()>>6.292668604262214
train_test["employment_length"] = train_test["employment_length"].apply(term)
train_test["term"] = train_test["term"].apply(term)
train_test["loan_status"] = train_test["loan_status"].apply(loan_status)employment_lengthとtermとloan_status
をapplyにて処理。
#ワンホント変換
rabel = ["grade","purpose","application_type"]
dummy_df = pd.get_dummies(train_test[rabel],drop_first = True)
train_test = pd.concat([train_test,dummy_df],axis = 1)
train_test = train_test.drop(columns=rabel) #idも消す
train_test = train_test.drop(columns="id")いつものtestはNanにもどす。
train_test["loan_status"] = train_test["loan_status"].replace(-1,np.nan)
train_X = train_test[~train_test["loan_status"].isnull()]
train_Y = train_X["loan_status"]
train_X = train_test[~train_test["loan_status"].isnull()].drop("loan_status",axis = 1)
test_x = train_test[train_test["loan_status"].isnull()].drop("loan_status",axis = 1)分割。train_X、train_Y、test_x。
学習させて、評価するために
#l1正則化で試してみる 。
fs_model = LogisticRegression(penalty='l1', solver='liblinear',random_state=0)
fs_threshold = "mean"
# 組み込み法モデルの初期化
selector = SelectFromModel(fs_model, threshold=fs_threshold)
# 特徴量選択の実行
# lr_l1 = LogisticRegression(C=C, penalty='l1', solver='liblinear').fit(X_train, y_train)
selector.fit(X_train,y_train)
mask = selector.get_support()maskで残った列を採用する
train_X_mask = train_X.loc[:,mask]
test_x_mask = test_x.loc[:,mask]X_train,X_test,y_train,y_test = train_test_split(train_X_mask,train_Y,random_state = 20)lr = LogisticRegression()
lr.fit(X_train,y_train)
pred = lr.predict(X_test)学習させて評価出力
# f1_scoreのインポート
from sklearn.metrics import f1_score
# 実測値y_test,予測値predを使ってf1_scoreを計算
f_one = f1_score(y_test,pred)
# 評価結果の表示
print(f_one)>>0.013465801789966335
予測を0か1ではなく確率出だしてみる
# X_testに対する予測の確率値を算出
pred_proba = lr.predict_proba(X_test)
# 確率値をDataFrameに変換して格納
proba_df = pd.DataFrame(pred_proba)chargedoff_val =y_test.sum()
print(chargedoff_val)
# # 1である確率値を降順で並び替え
proba_desc = proba_df[1].sort_values(ascending = False)つまり、答えの1の数にをもとに閾値を決定する。
確率を降順で並び替え、受けから1の数を数える。そこの確率を閾値とする。
「その1になる確率は1とする」のか「0」
threshold = proba_desc[chargedoff_val]
print(threshold)
# 変数proba_dfに新たなカラムclass_newを作り、proba_dfのカラム「1」に自作関数classificationを適用した結果を代入
proba_df['class_new'] = proba_df[1].apply(lambda x: 1 if x >= threshold else 0)
proda2 = proba_df['class_new']
>>0.1705247415185119
0 0
1 1
2 0
3 0
4 0
Name: class_new, dtype: int64
閾値は0.17052
確率は0.17しか無いけれど1とする。
pred = lr.predict_proba(test_x_mask)
proba_df = pd.DataFrame(pred)maskをかけたtestデータを確率でだす。
proba_df['class_new'] = proba_df[1].apply(lambda x: 1 if x >= threshold else 0)>>0 0
1 1
2 0
3 0
4 0
..
60534 1
60535 1
60536 1
60537 1
60538 0
Name: class_new, Length: 60539, dtype: int64
proba_df['class_new'] proba_df確率のデータフレームに['class_new']を作った。
sample_submit[1] = proba_df['class_new'] それをsample_submit[1]に入れる。
>>
0 1
0 1496754 0
1 84909594 1
2 1165403 0
3 91354446 0
4 85636932 0
... ... ...
26901 5064630 0
26902 94416733 0
26903 120604638 0
26904 1110314 0
26905 5425387 0
26906 rows × 2 columns
auth.authenticate_user()
gauth = GoogleAuth()
gauth.credentials = GoogleCredentials.get_application_default()
drive = GoogleDrive(gauth)
PATH_MYDRIVE="/content/drive/My Drive/SIGNATE_saimu"
sample_submit.to_出力。
結果は
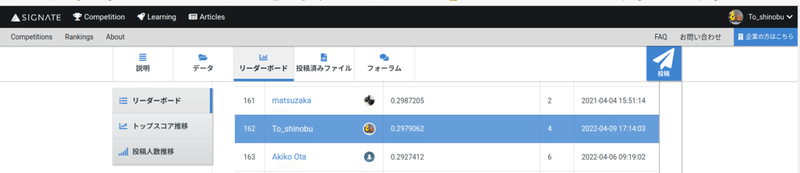
162位!
前のクエスを活かして、気がついたことは別シートのエクセルに記載し、処理の流れを明確にする。
コメントをちゃんと書く。で比較的解りやすくなったものの、
改善したと思ったら、前回と全く同じ数値になってた。ずっと確認していると、途中で改善前のデータを引っ張ってきていた。
コードをコピペして一部変えたもののちゃんと全部変えていなかった。。。
使わないコードをコメントアウトして残しておくと見にくいけど、勘違いして消してしまったり、必要だったら嫌だしと残すのでなんとかしないといけない。
完全に消すようにしてバージョン管理をするか、関数として処理。関数を使う使わないとして、無駄なコードを残さないようにするか、、、
次回の課題です。
この記事が気に入ったらサポートをしてみませんか?