[PSPP]マクネマー検定とコクランのQ検定
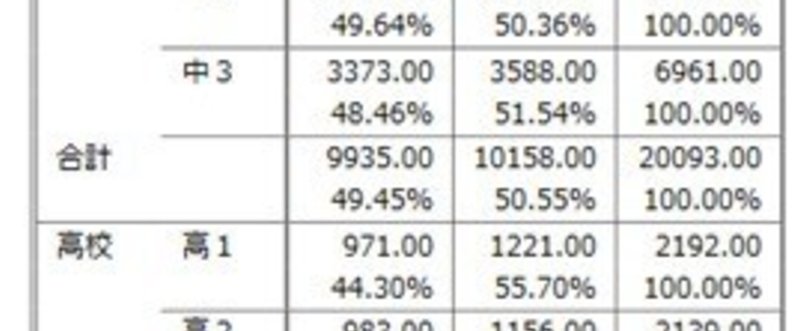
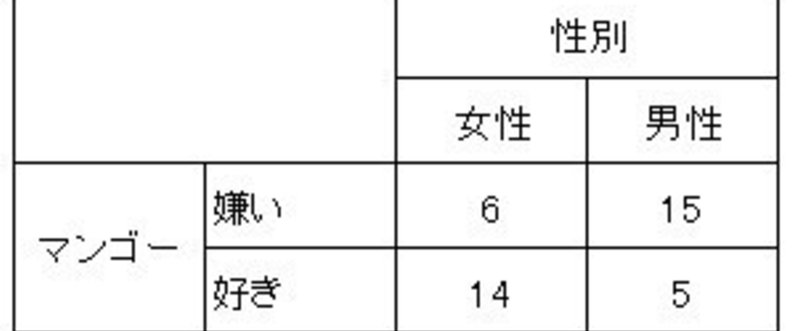
マクネマー検定マクネマー検定(McNemar Test)は、対応のある2値変数(1/0データの変数)について、すべての変数間で比率に差があるかどうかを検定します。
χ2検定とよく似ているが、両者の検定結果は無関連です。一方で有意だったからといって、もう一方でも有意だとは限りません。χ2検定は「質問A にYESと答えると、質問B にもYESと回答しやすい」などの、2つの変数の関連性の検定であるのに対して、マクネマー検定は、「質問AにYESと回答し質問B にNOと回答したものと、