[R,Onyx]共分散構造分析②

3.潜在変数を含んだモデル
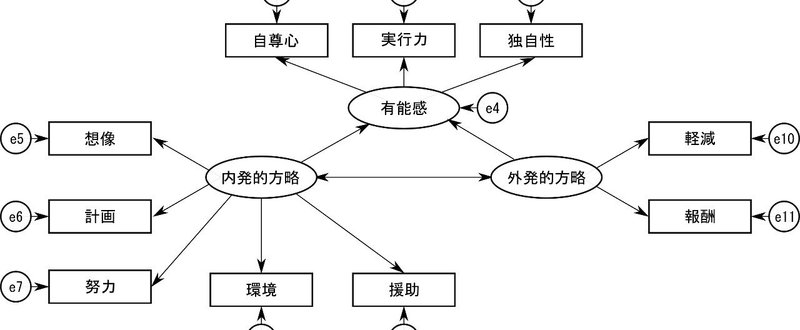
観測変数だけではなく、潜在変数を含んだモデルとして、最初に示したパス図のうち、「有能感」を取り出し、これに「想像」「計画」「努力」「環境」「援助」「軽減」「報酬」という自己調整方略を加えて、潜在変数が影響関係を持つモデルを作ってみます。
潜在変数である「有能感」は「自尊心」「実行力」「独自性」に影響を与えていますので、この部分は観測方程式になります。
また、「想像」「計画」「努力」「環境」「援助」の5つの観測変数は「内発的方略」という潜在変数から、「軽減」「報酬」の2つの観測変数は「外発的方略」という潜在変数から、それぞれ影響を受ける観測方程式が成り立つと想定します。
この2つの潜在変数は、意欲を左右する方略という構成概念であり、互いに相関関係を持ちながら、潜在変数である有能感に影響を与えていると考えます。この部分は、構造方程式になります。
これをパス図に表すと、次のようになります。

IBMのAmosでは観測方程式と構造法的式は、描く手順が異なりますし、Rのスクリプトでも当然異なりますが、Onyxで描く場合は手順上はほぼ区別がありません。描かれたパス図から、自動で方程式を判断してスクリプトが作成されます。
■パス図の作画
Onyxを起動し、観測変数をシート上にドロップするところまでは、「2.観測変数を用いたモデル」と同じです。
異なるのは、潜在変数を描く部分です。

・シート上で右クリック・メニューから[Create Variable]→[Latent]を選択する。
※[Latent]が潜在変数、[Observed]が観測変数ですから、データを読み込まなくてもパス図を書くことは可能です。
・右クリック・メニューの[Variable Name]の名前を変更しておく。
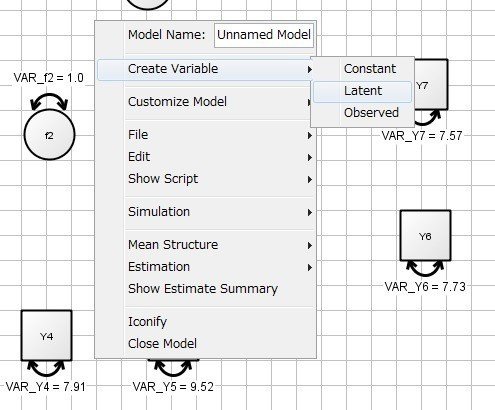
潜在変数を配置し終えると、次のようになります。

ここから、パスを引いていきます。
・原因となる変数上で右クリックをし、そのまま影響を受ける変数までドラッグして、パスを引く。
・原因となる変数上で右クリック・メニューを表示し、[Add Path]を選択、影響を受ける変数上で左クリックでも同様にパスを引くことができる。
・パス上で右クリック・メニューを表示し、[Toggle Rath Heads]を選択すると、矢印の向きが反転する。もう一度同じ操作をすると、双方向の矢印になる。
・パス上で右クリック・メニューを表示し、[Free Parameter]を選択する。係数が自由母数であるパスはすべてこの操作を行う。

ただし、識別性の確保のため、潜在変数から観測変数へのパスのいずれか1つは[Free Parameter]にせず、[value]を1のままにしておきます。また分散や誤差を表す双方向の矢印を固定値1に([Fix Parameter]を選択して、[value]を1に設定)してもかまいません。いずれの場合も、標準化係数は同じになります。
実はこの時点で一応推定は行われていて、パスには非標準化係数が表示されています。パス上で右クリック・メニューを表示し、[Customize Path]→[Show Standardized Estimates]を選択すると、標準化係数を表示することができます。
また、右クリック・メニューを表示し、[Show Estimate Summary]を選択すると、推定結果の詳細を見ることができます。
「2.観測変数を用いたモデル」と同様に、Rで処理するためのスクリプトを書き出します。
・シート上で右クリックメニューを表示し、[File]→[Export Script]→[lavaan]を選択。
分析できるように、保存されたスクリプトのデータの読み込み部分などを修正します。基本的には、「2.観測変数を用いたモデル」と同様に行います。
■Rでの分析
ここでは、データを
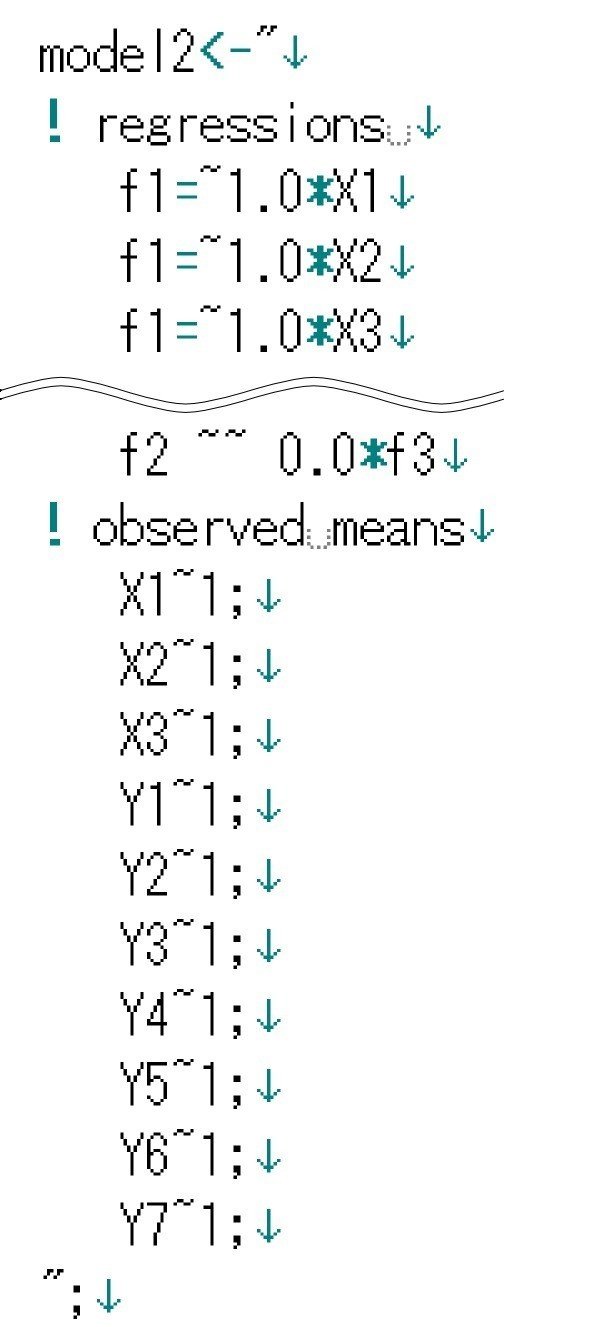
そして、ここでは、
result2 <- sem(model=model2,data=modelData,estimator = "ML")
と、ここでは、lavaanパッケージのsem()関数で分析してみました。
■出力の見方
その結果をsemPlotパッケージで書き出し、ドローソフトのinkscapeで修正を加えたものが、次の図です。

係数はすべて標準化されています。なお、sem()での分析結果のsammary()による出力は、下で示す適合度指数以外の部分は割愛します。

適合度指標は、CFIが0.887、TLIが0.850で、この2つは1に近い、つまり値が大きい方があてはまりがよく、0.95以上でよいモデルとなりますので、悪くはないモデルであると判断できます。
AIC、BICは相対的な評価ですので、1モデルしか分析していない現状では、あまり意味を持ちません。
RMSEAは0.086、SRMRは0.063です。RMSEAは0.05以下でよいモデル、0.1以上で悪いモデルと判断しますし、SRMRは下限の0に近いほど、つまり値が小さい方があてはまりがよいと判断しますので、こちらの指標でも悪くはないモデルであると言えるでしょう。
この記事が気に入ったらサポートをしてみませんか?