
キャッシュ構造とアラインメント

超高性能プログラミング技術のメモ(2)
高性能プログラミングに必要なキャッシュメモリの基礎知識を記録しておきます。
なぜキャッシュメモリが必要なのか?
CPUで実際に演算処理を行うと演算器は、CPU内部に実装されているレジスタ(メモリの1種)にあるデータしか使えません。そのため、アセンブラ言語レベルでは、ほとんどの演算処理は、次のようなステップを踏みます。
1. 汎用メモリからレジスタにデータを転送する(ロード処理)
2. レジスタ上のデータを処理し、レジスタに書き込む(演算処理)
3. レジスタから汎用メモリにデータを転送する(ストア処理)
1998年以来、CPUの処理速度は劇的に速くなり、今ではナノ秒単位で処理できます。しかし、汎用メモリからレジスタへの転送速度は、緩やかに進化してきたため、ロード処理は演算処理の100倍以上遅いこともあります。これでは、せっかく処理速度を向上しても、データ転送がボトルネックになってしまいます。そこで、汎用メモリの手前に一時保存しておく倉庫(キャッシュメモリ)が実装されています。わざわざ産地(汎用メモリ)まで行かなくても、倉庫(キャッシュ)からデータを持ってくるようにして、データの流通の高速化を実現しています。
キャッシュメモリの構造
Intelの最適化マニュアル"Intel® 64 and IA-32 Architectures Optimization Reference Manual"から、SKYLAKE MICROARCHITECTUREのキャッシュ情報Table 2-5によると、第1層データキャッシュ(First Level Datra, L1D)と第1層命令キャッシュ(Instruction, L1I)、第2層キャッシュ(Second, L2)、第3層共有キャッシュ(Shared L3)という3層構造になっていることが分かります。
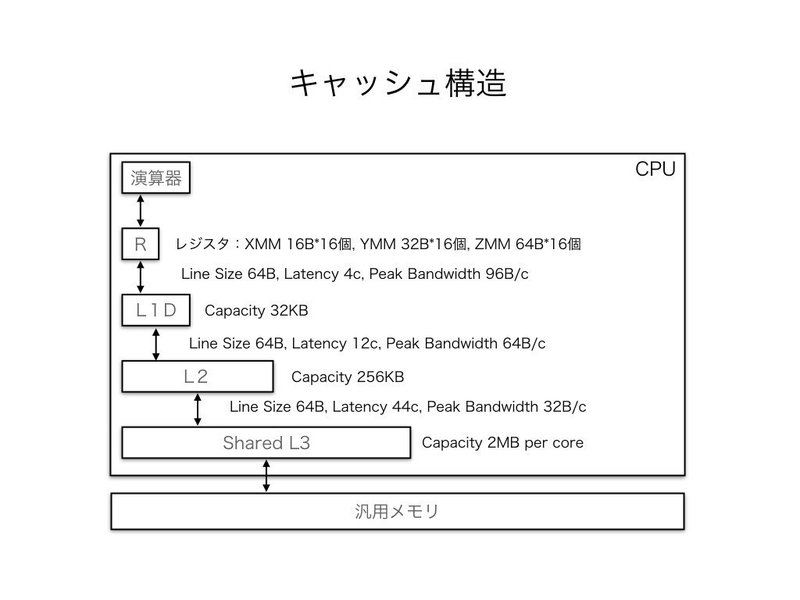
Table 2-5の中で、特に気にしなければならないのは、CapacityとLine SizeとLatencyです。より高性能なプログラミングではAssociativityも考慮する場合があります。Capacityは倉庫の大きさ(キャッシュ容量)、Line Sizeはパッケージの大きさ、Latencyは輸送時間(転送時間)のことです。これを高性能プログラミング的に解釈すると、⑴よく使うデータ量はCapacityを超えないようにすること、⑵Line Size分ずつデータを小分けにすること、⑶Latency分の時間は何か別の仕事をさせること、という注意点になります。
また、現在のシステムには、各層に自動的に転送する機能が装備されています。自動的と言っても、ランダムに転送する訳ではありません。大帝の場合は、直前に転送されたデータの次のデータを自動転送するように設計されています。この機能は、プリフェッチ機能と呼ばれます。これを高性能プログラミング的に解釈すると、読み込むデータを連続データにすると最も効率が良いとなります。なぜなら、連続データであれば無駄なプリフェッチを最小化できるからです。
メモリの区画に合わせる(アラインメント)
さらに、Table 2-34を見ると、キャッシュメモリは16Bの区画に分けられており、読み込むデータの先頭データが、区画の境界上にある(aligned)か、区画の途中から始まっている(unaligned)かによって、処理速度が異なることが分かります。Unalignedの場合、区画の何処から始まっているか計算し、2つの区画に分けて計算するため、alingnedが前提の場合よりも処理が増加するためです。高性能プログラミング的には、データは可能な限り区画の境界で区切ること、という解釈になります。
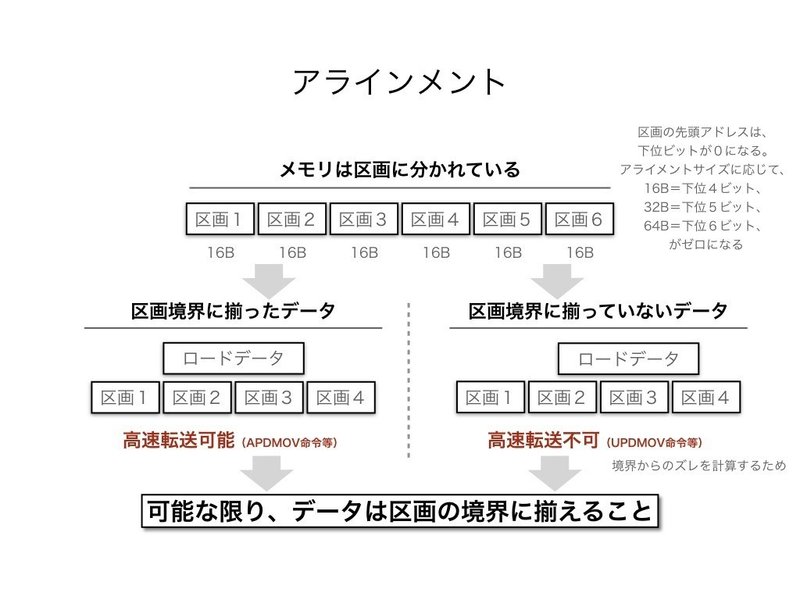
区画の境界かどうかは、C言語のポインタアドレスの下位4ビットが0かどうかで分かります。下位4ビットが0以外の場合は、区画の途中ということになります。そこで、下記のようなコードで、ポインタを区画の境界に合わせることができます。
#ifndef CHECK_ALIGN_C #define CHECK_ALIGN_C
#define ALIGN_BOUND 0xf #define ALIGN_BYTE 16
#include <stddef.h> #include <stdlib.h> #include <stdio.h>
typedef struct AlignPtr {
unsigned char * align;
unsigned char * origin;
size_t size;
size_t n;
} align_ptr_t;
align_ptr_t malloc_align( size_t n, size_t size ){
align_ptr_t p;
p.origin = (unsigned char*) malloc( n * size + ALIGN_BYTE );
p.n = n;
p.size = size;
size_t unalign = (size_t)(p.origin) & ALIGN_BOUND;
if( unalign ){
p.align = p.origin + (ALIGN_BYTE - unalign);
}else{
p.align = p.origin;
}
return p;
}
void free_align( align_ptr_t* p ){
free( p->origin );
p->align = 0;
p->n = 0;
p->size = 0;
}
int main( int argc, char** argv ){
align_ptr_t p = malloc_align( 256, sizeof(double) );
printf("origin=%p, aligned=%p\n",p.origin,p.align);
free_align(&p);
return 0;
}
#endif /* CHECK_ALIGN_C */
align_ptr_tはポインタを格納する構造体でoriginに元のポインタのアドレスが、alignに区画の境界に合わせたポインタのアドレスが格納されます。この構造体のメモリ割当と解放する関数をそれぞれmalloc_align/free_alignで定義しています。
このプログラムを実行すると次のように出力されます。
origin=0x7ffe0b801000, aligned=0x7ffe0b801000
上記の場合、境界に合わせてメモリが割り当てられているため、どちらも同じアドレスになっています。
まとめ
今回は、キャッシュメモリーの構造とアラインメントの確認方法を書きました。次回は、Latency分の時間を稼ぐについて書こうと思います。
この記事が気に入ったらサポートをしてみませんか?