パワーとは力にあらず!!DeepLabの学習率ポリシー

DeepLabを自作データで回し始めると、学習率等のハイパーパラメータが気になってくる。ところがtrain.pyのフラグ群を眺めてみても…
base_learning_rate: The base learning rate for model training.
learning_rate_decay_factor: The rate to decay the base learning rate.
learning_rate_decay_step: Decay the base learning rate at a fixed step.
learning_power: The power value used in the poly learning policy.
training_number_of_steps: The number of steps used for training
momentum: The momentum value to use
なんか学習率関連のパラメータが多い。
パッと見は上3つと最後のmomentumで計算できそうだけどどういうこと???となる。Powerとは結局何に使われる力なのか?
検索してもリファレンスに当たらない。
仕方なくフラグの使用箇所を直接見てみると、deeplab.utils.train_utils.get_model_learning_rate()のDocstringに説明が書いてある。なぜこっちに書いたのか…?
DeepLabにおける学習率の計算式
Docstringの数式によると、以下の数式で現在の学習率は決定される。(global_stepは現在のステップ)
(1) learning policyが"step"の場合:
current_learning_rate = base_learning_rate *
learning_rate_decay_factor ^ (global_step / learning_rate_decay_step)
(2) learning policyが"poly"の場合:
current_learning_rate = base_learning_rate *
(1 - global_step / training_number_of_steps) ^ learning_power
やはり全てのフラグを計算に使用しているわけではなく、選択したポリシーによってbase_learning_rate、learning_rate_decay_factor、learning_rate_decay_stepとbase_learning_rate、training_number_of_steps、learning_powerのいずれかを決めればいいことがわかる。
言われてみれば関数でpowerとかよくある。
両ポリシーについては以下サイトにグラフ付で解説してある。
train.pyのフラグlearning policyのデフォルトは'poly'で、local_test.shを使用している場合、training_number_of_stepsはNUM_ITERATIONSに設定した学習回数が代入されている。
とりあえずやってはいけないこと
polyのグラフを見ると、最終ステップで0になるように学習率が更新されていくので、「lossが減らないのでとりあえずもう10000ステップ追加で回してみよう」というのは明らかに誤り(やっていた)。
いかにパラメータを決定するか
おそらく、少なめの学習回数で試行してlossが収束するまでbase_learning_rateを大きくしていって、base_learning_rateを決定したら学習回数を多くして精度を高める、といった運用が正しそう。
learning_powerはべき乗の指数なので、1に近いほどグラフが直線になる。
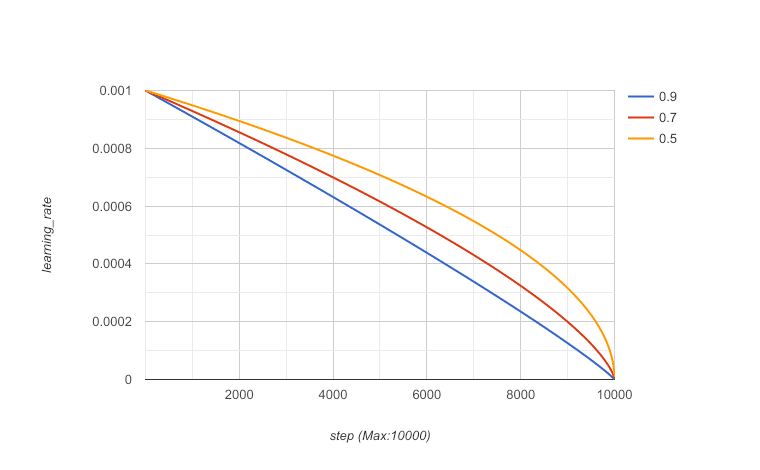
学習回数が少ない時はpowerを大きめにして、学習回数を増やしたらpowerを小さくして最後にグッと精度を上げてく感じ?
とりあえず自分のデータセットで試してみる。 ■
この記事が気に入ったらサポートをしてみませんか?