LLM活用サービスのデザインパターン5選(システム編)

大規模言語モデル(LLM)を活用したサービスが次々と現れていますが、そんなLLM活用サービスにおいて、「誤った情報の呈示(Hallucination)」の回避が重要であることは、前回の記事で触れました。特に、顧客対応や医療・教育関連の「正確性」が強く求められるサービスでは、Hallucinationが致命的です。
この記事では、Hallucinationを抑えるための対策として知られているものを、正確性の制御のしやすさの順にまとめました。
LLMについては毎週のように新しい話題が現れますが、以下に挙げる抽象的な構造に関しては、まだ劇的には変化していないように思われます。
前回のUX/UIデザイン編はこちらです:
LLM活用サービスのデザインパターン
Hallucinationに対して、システム面からは様々な対策があります。今回は、以下のサーベイ論文[1]を参考に、Hallucinationを軽減するためのデザインパターンをランキング形式でまとめました。
結局のところ、Hallucination対策としては、LLMの出力をコントロールすることが重要です。より厳しくLLMの出力を統制する順で並んでいます。厳しくLLMの出力を統制できれば、出力の正確性を高められますが、準備のための労力が大きくなる場合もあります。
以下では、「正確性」と「手軽さ」について★で評価していますが、個人的な経験と印象に基づくものであり、定量的な測定によるものではありません。実践的には、個別の状況に依存する面が大きいので、あくまで目安として考えていただければと思います。
1位. LLMの出力をそのまま使わない

正確性:★★★★★
手軽さ:★★
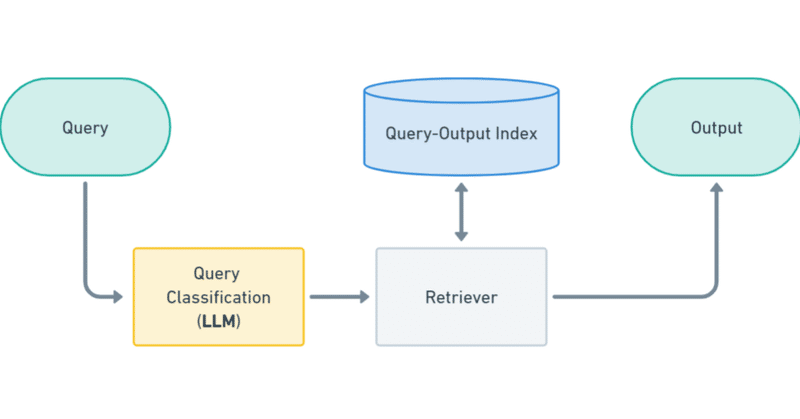
いきなりですが、1位は上記のサーベイで触れられていない方法です。最終出力の生成自体にLLMを使用しないパターンです。代わりに、入力テキストをLLMを使用してZero-shot/Few-shotで分類し、分類に応じて事前に用意した出力を選択します。
【長所】
出力をその場で生成せず、事前に定義しておくことで、ユーザに正確な情報のみを呈示することを担保できます [2]。(ただし、分類ミスによる文脈の齟齬などは発生します。)以下で述べるRAGなどの方法で十分な正確性を得られずに困る場合は、そもそもLLMにユーザ向けのテキストをさせない方向に考えると良いかもしれません。
LLM以前も、テキストの埋め込みモデルを用いた同様の取り組みは人気があったと思います。LLMをZero-shot learnerとして用いることで、個別のタスクに対してモデルを学習する必要が無くなったところが、LLM登場により大きく変わった点だと考えられています [2]。
【短所】
一方で、想定される出力を一通り用意しておかなければならないという点でお手軽でなく、用途によっては実現性が制限されます。
2位. RAG (Retrieval Augmented Generation)

正確性:★★★★
手軽さ:★★★★
2位はRAGです。RAGは、テキスト生成の際に、LLMに入力文に関連のある文書を参照させることで、出力の正確性を高めたり、特定のドメインに特化した応答をさせる方法です。LLM出力の正確性を高める目的で、現在最も人気のある方法となっていると思われます。
【長所】
下記のFine-tuningと比較されることが多いようですが、RAGがアウトパフォームする傾向にあるようです [6]。また、情報の更新の度にモデルを再学習する手間がないという利点もあります。
【短所】
Fine-tuningと比較すると、入力の埋め込みや、関連文書の抽出などの処理がクエリごとに発生するため、応答速度の面で劣ります。また、関連文書の内容がLLMへの入力に追加されるため、コスト面でも不利です。
RAGの良い解説記事は多くあるので、詳細はそちらに譲ります。RAGの中にも、様々な戦略があり、下記のような記事でまとめられています。
3. Fine-tuning

正確性:★★★
手軽さ:★★★
3位は、RAGと双璧で人気があるFine-tuningです。Fine-tuningでは、入力と出力のペアのデータセットを用意して、モデルを学習させる必要があります。
【長所】
RAGや「事前に用意した出力の選択」と比較すると、定義済みデータを参照するステップが無い分、速度面で有利です。また、RAGで行っている追加の情報のLLMへの入力もなく、コストも抑えられます。
【短所】
専用のデータセットの準備、情報の更新の度のモデル再学習という手間がデメリットです。
4. Prompt Tuning

正確性:★★+
手軽さ:★★★★
4位は、プロンプト自体を機械学習で最適化したものを使用する、Prompt tuningです。
【長所】
モデルのFine-tuningのように、LLMを学習させるのではなく、プロンプトに使用する語彙の並びを学習するため、調整対象のパラメータの数がFine-tuningより少なく、計算コストが小さくて済むことが多いです。一方で、GPT-3での結果ですが、性能はFine-tuningに匹敵するとの報告もあります [7]。
【短所】
一般に、Fine-tuningの性能は超えないと考えられているようです。
また、最適化したプロンプトは可読性があるとは限らないため、後で人手で調整することは考慮できず、下記のPrompt designの知見を導入しにくくなってしまいます。
5. Prompt Design

正確性:★★
手軽さ:★★★★★
5位は、Prompt designです。LLMへのプロンプトを工夫して所望の出力に近づける手法で、Prompt engineeringと呼ばれることも多いです。例えば、理想的な入出力の例をいくつか与えるFew-shot promptingや、段階的に推論させて過程も説明させるCoT (Chai of Thought)などが含まれます。
Prompt designに関しては、他の方法とも両立するので、組み合わせて用いることができます。(というか普通そうすると思います)
【長所】
とにかくお手軽。データなどなくてもすぐに始められます。
【短所】
正確性の向上はあまり期待できません。
以下のスライドでは、どこまでPrompt designを行い、データがどのくらいあればFine-tuningに切り替えるべきかが調べられており、参考になります。(プロンプトにFew-shotで与えるのは2件までという結論のようです。Prompt tuningという言葉は本記事と異なる意味で使われています。)
番外編
以上で紹介した5パターンは、一つの入力に対して、LLMに一度だけテキストを生成させていました。実際のサービス開発では、Agentの枠組みを利用して、LLMに複数回推論をさせるケースが多いのではないでしょうか。複数回の推論を工夫して統合すれば、かなりの正確性の向上が期待できます。ただ、複数回の推論を利用する方法はコスト面で不公平なので、今回は「番外編」として2パターンを取り上げます。
Iterative Querying

一つ目は、精度の高い回答が得られるまでLLMに出力の改善を繰り返させる方法です。一般的な総称がよく分からなかったのですが、[3] に倣ってここではIterative Queryingとしました。
WolverinやAutoGPT、AgentGPT、ReActなどのAgentベースのフレームワークでよくみられることが多いパターンです。
Multiple Completion

二つ目は、複数のLLMに回答を生成させ、多数決などの方法で複数の回答を統合して一つの結論を導く方法です。こちらも総称が分からなかったのですが、[4]に倣い、Multiple Completionとしています。
こちらも、Agentベースのフレームワークでよく使われる手法だと思います。Self-Consistency CoT というCoTの発展形を開発した文献[5]では、同じLLMに回答を複数回生成させた後に、多数決で最終回答を決定するという方法で、回答の精度向上を報告しています。
今回は、LLMの出力に誤りが含まれることを前提に、対策となりうるシステム面でのデザインパターンについてまとめました。
以上です。
参考資料
[1]
[2]
[3]
[4]
[5]
[6]
[7]
この記事が気に入ったらサポートをしてみませんか?