
中古車価格分析して718ケイマンを狙う。

ロードスター購入時にML使って、価格予測、販売価格との差分が大きいものを”お得”として購入しました。購入時の判断基準として改めて
経過年度、走行距離に応じた価格下落が少ない車種であること。
予測価格より離れている、いわゆる”異常値”をお得車両として見つける。
ポルシェについても同手法で予測式からの差分確認しますが、ロードスター予測式での30−40万価格差分と”718ケイマン”での価格差分50万ではいわゆる「お得感」が違うんではないかという疑問が湧いてきました。
新車時の価格が違うんだし、、いや財布的に50万離れていれば絶対値でお得なはず。
ここで、chatGPTへ質問。
”中古車の価格分析で年式や走行距離などのパラメータを考慮に入れて、より総合的な「お得感」を評価するためには、これらの特性を相対的な重み付けやスコアリングシステムに組み込む方法が考えられます。”
とアドバイされたので、スコアリングすることにしました。
マルチクリテリア決定分析(MCDM)の一般的な手法の一つに「加重合計法」(Weighted Sum Method)があり、この方法では、各車両の特徴(年式、走行距離、価格差分など)に重みを割り当て、それらを合計して総合スコアを計算するようです。価格分析の時にはSHAP(特徴量の重要度指標)は確認しており、ロードスターの分析では以下となってました。
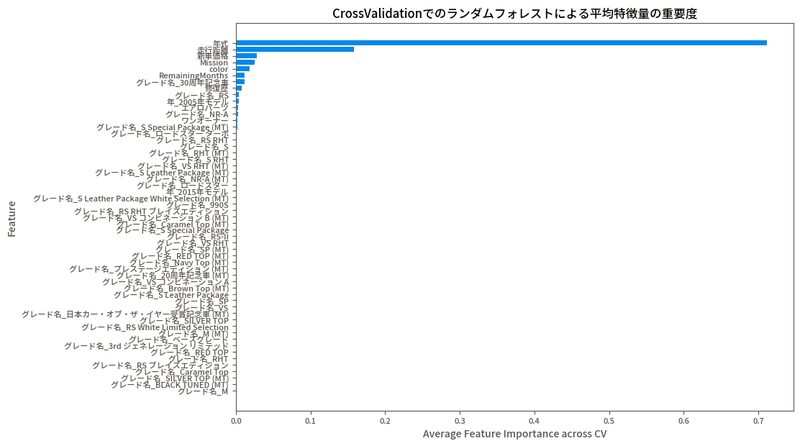
価格に対しては何が重要なのかを視覚化したもので、特徴量の係数について目的変数(価格)にどれが大きく影響するかということです。要するにこの車を買うなら年式を気にすべし。(ポルシェやフェラーリなどの例外もありますが。)
ただ経過年ごとに、大きく下がるかどうかはまた、車種、グレードによって異なります。
スコアリング
次にスコアリングに向けて、plotlyへ入力したdataframe形式を確認。データフレーム構造は以下となっており、正規化に不要な列をドロップして。
Index(['名称', '年式', 'グレード名', '年', '色', 'Class_Category', 'Url', 'Mission', '修復歴', 'difference', '新車価格', '価格', '総額', 'predicted_price', '走行距離', 'predicted_price_zero_mileage', 'filename', 'CarMaker', 'date', 'Carname', '年式年数', '経過年数', '残価率', '残価率比率'], dtype='object')
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
df['difference_new'] = df['predicted_price'] - df['new_price']
df['difference_norm'] = scaler.fit_transform(df[['difference_new']])
df['score'] = 1 / (df['difference_norm'] + 0.01)
df.sort_values(by='score', ascending=False, inplace=True)スコアリングといっても、予測価格からの差分を正規化して、スコアづけしただけで結果からいうと。失敗。 AMG_GT とかランボルギーニ_ウルス、GT-R NISMO とか、4000−9800万円の車がランキングされる。新車価格に対しての正規化が必要でしたか、、ちょっとこのアプローチは次回以降に回します。
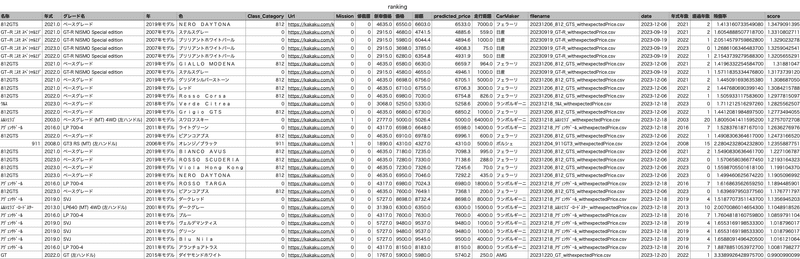
余裕のある方はご参考ください。。ちなみに20年選手のランボルギーニ/
ムルシエラゴが上位に食い込んでました。当時の新車価格の2倍。
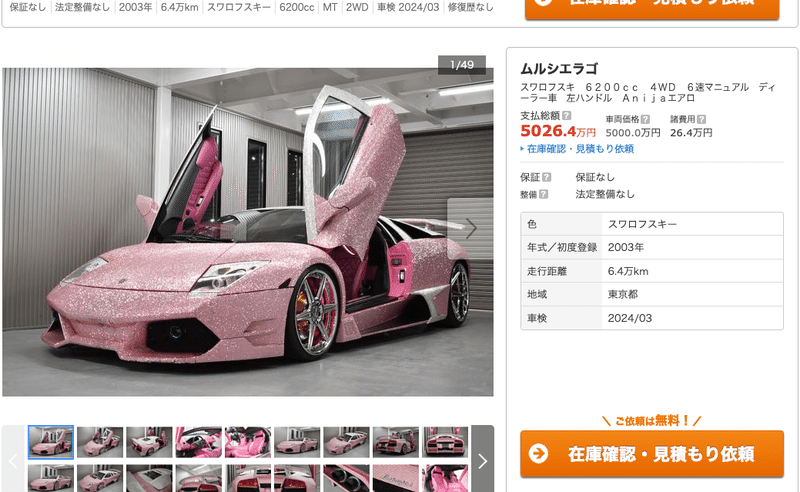
718ケイマン
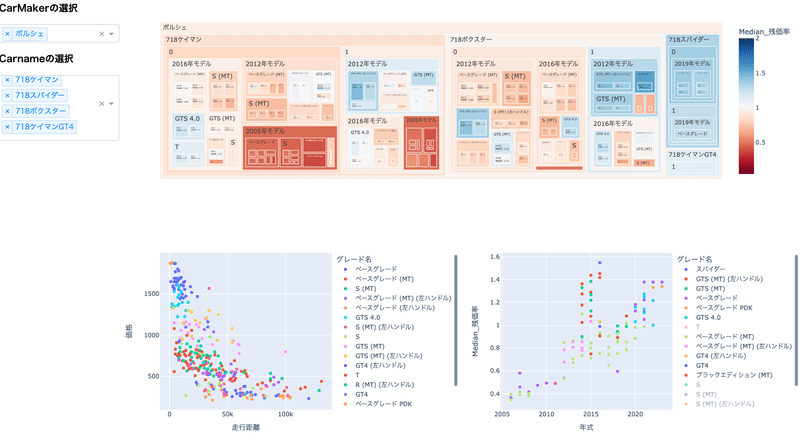
でやっと本題の718ケイマンについて経過年ごとの残価率を見ていきます。まず全体像で、メーカー/車名/モデルイヤー/年式 でグルーピングしています。(グルーピングの0,1はAT,MTを表します。)メーカーごとに色が偏って見えますが、これは選定している車種が理由であり、メーカー別の傾向ではありません。
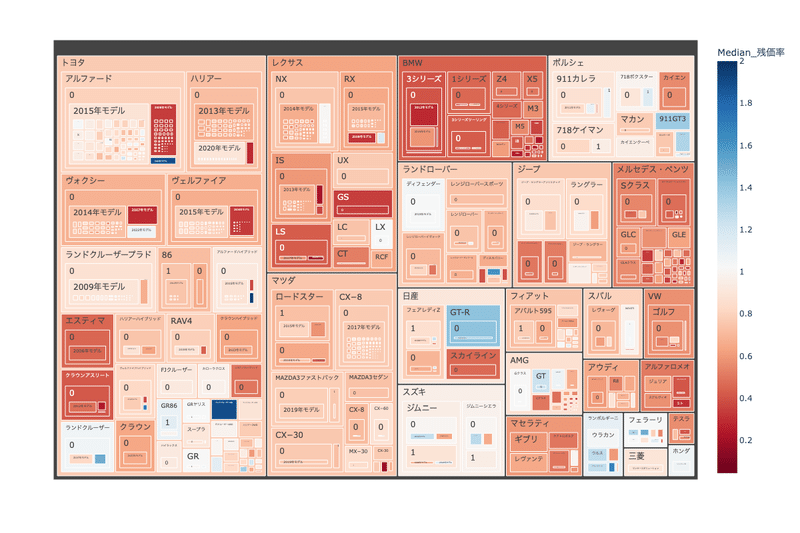
次に、ポルシェで絞ります。718ケイマンでのターゲットは決まりました!
経過年後の残価率が高いものが見えてきたと思います。あとは継続webをウォッチしながら、予測価格から離れた”お得車両”がでてきたらアクセスしていきます。
なお、データの出典は価格こむさんです。
この記事が気に入ったらサポートをしてみませんか?