
中古車価格分析のお話(ロードスター編)

中古車価格の現状
中古車市場は、近年大きな変動をしています。新車販売が鈍化している一方で、中古車への需要は増加傾向にあります。さらには資源高騰、材料不足、経済情勢などによる新車の入手性悪化なども影響して、中古車価格は高値を維持したものが多いように思います。さらには環境問題や物価高騰が影響する中、多くの人々がコストを抑えて車を持ちたいと考えています。
若い世代では、中古車もスマートな選択肢として認識されていますが、これは、クオリティの高い中古車が増え、それに伴って情報収集の方法も多様化してきたことが背景にもあります。中古車取引のプラットフォームや評価サイトも増え、消費者は以前よりも多くの選択肢と情報を手にでき購入時の選択肢選びに迷うものです。
車の価格の構成要素
中古車市場も、近年の経済変動と技術の進化でかなり複雑になってきています。一昔前と比べ、多くの車種やグレードが出てきて、どれがいいのか迷いますし、さらに、輸入車や国産車、エコカーの影響で、価格のバランスも把握しづらいです。
このような中、正直「この価格で良いのだろうか?」と思うことがあります。情報は増えたけど、その分、何が正しいのかを見極めるのが難しくなってきてます。ここでは中古車価格の妥当性について分析していこうと思います。まずは代表的な中古車サイトの表示情報を確認してみます。
ND ロードスターです。余談ですが、私はこれから示す価格分析手法によって、2015年式のRSグレードを購入しています。
年式、走行距離、修復歴、車検、車体色、グレード情報、内装、外装情報が並んでいます。古くて、走行距離が多ければ値段は下がって然るべきですが、一部90年代のスポーツカーや人気車種などは例外で価格が高値安定してるものもありますが、今回はこの車種を例に取ります。
価格帯の確認方法
実際に中古車サイトをscrapingして価格プロットしています。走行距離と価格の相関図になります。
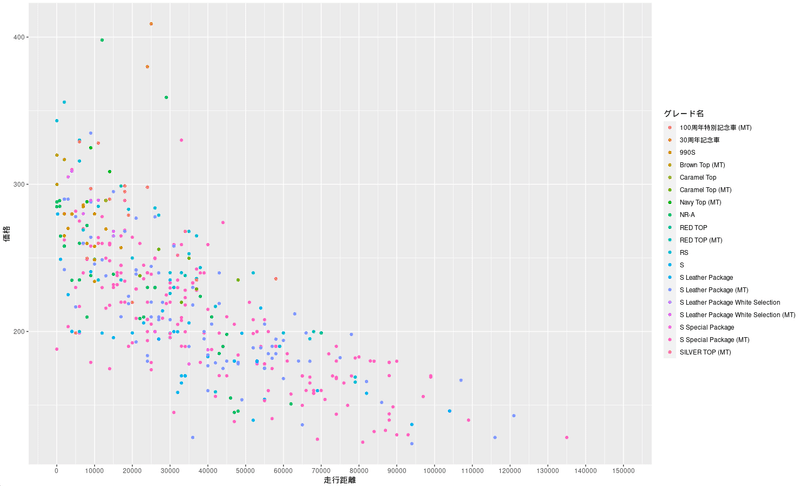
ここではグレード、MT/ATに色付けましたが、年式、色、残車検、エアロパーツ、ワンオーナーかなど、それぞれ価格にどの程度影響しているかも気になってきます。
そこで、🎥 特徴量の重要度を視覚化してみました。
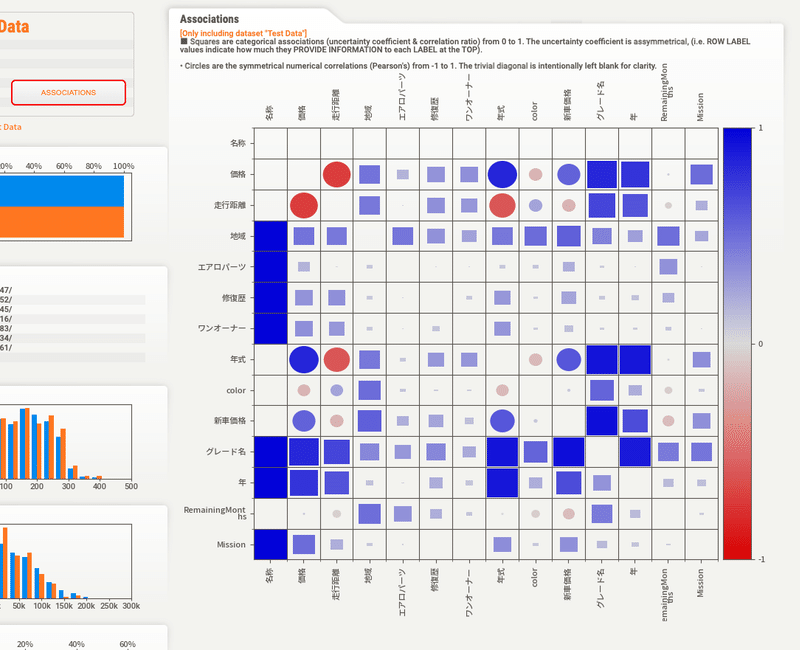
分析結果を視覚的に表すとこうなります。このグラフの意味するところは、価格に対してどの項目が特別なのか。車の価格予測するのにどの情報が一番大切なのかを見るためのものになります。
🔲は質的変数を表し、🔴は量的変数同士の量的相関を表します。
予想通りですが、走行が増えれば価格は下がり、年式が上がれば価格が上がる(新車価格に近くなる。)ということになります。
表を見ても分かる通り、すべての情報が同じくらい大切なわけではありません。ある特徴量は非常に価値がある一方、他の情報はそれほど影響を持たないことがあります。これは、例えば、ある車の機能は価格に大きく影響するけど、別の小さな機能はそんなに影響しない。スポーツカーであればMT/ATの差異も価格への影響度は大きいです。
予測価格の紹介(k-fold、回帰分析)
視覚的に価格への影響度が如何程のものか把握できましたが、ここではさらに価格を目的変数として、それをデータ特徴量(グレード、年式、走行距離、車検残月、カラー、エアロ有無、ミッション種別)でどのような式で表現できるかを、5分割のK-Foldクロスバリデーションで重回帰モデルを評価して予測してみます。
多数のデータ取得でデータ欠損や異常値の処理などのハードルが様々生じましたが、データ取得や処理過程における欠損値は平均値で補完。怪しげなデータはレコード削除しています。
R^2スコアでモデルの精度を測定し、最終的に、モデルの係数と切片を用いて予測式を構築し、走行距離が0のケースの価格予測も含めて分析を行います。’23/12におけるweb上のデータ774台分について、計算結果は以下のようになります。
モデルの精度としては問題なさそうです。さらに価格についても逆算可能なものとなっています。
K-Fold Cross-Validation
R^2 scores: [0.8875844 0.85477025 0.84505316 0.86703114 0.87908717]
Average R^2 score: 0.87予測式: 価格 = -17553.0812 + (-0.0006 * 走行距離) + (14.0278 * エアロパーツ) + (-19.9313 * 修復歴) + (-0.0117 * ワンオーナー) + (8.8141 * 年式) + (0.1305 * color) + (0.5183 * 新車価格) + (0.1135 * RemainingMonths) + (21.9340 * Mission) + (-43.8876 * グレード名_20周年記念車 (MT)) + (147.5830 * グレード名_30周年記念車) + (-39.7500 * グレード名_3rd ジェネレーション リミテッド) + (-11.2542 * グレード名_990S) + (-35.6785 * グレード名_BLACK TUNED (MT)) + (-0.1366 * グレード名_Brown Top (MT)) + (6.9242 * グレード名_Caramel Top) + (21.1066 * グレード名_Caramel Top (MT)) + (-65.4731 * グレード名_M) + (-84.5992 * グレード名_M (MT)) + (-23.8295 * グレード名_NR-A) + (-15.8270 * グレード名_NR-A (MT)) + (-10.6966 * グレード名_Navy Top (MT)) + (-8.7023 * グレード名_RED TOP) + (7.1687 * グレード名_RED TOP (MT)) + (-31.8861 * グレード名_RHT) + (-28.3778 * グレード名_RHT (MT)) + (-28.8752 * グレード名_RS) + (-31.6598 * グレード名_RS RHT) + (-23.4276 * グレード名_RS RHT ブレイズエディション) + (-3.2556 * グレード名_RS White Limited Selection) + (-52.7509 * グレード名_RS ブレイズエディション) + (-40.4194 * グレード名_RS-II) + (-26.9875 * グレード名_S) + (-9.9481 * グレード名_S Leather Package) + (-28.6188 * グレード名_S Leather Package (MT)) + (-29.0887 * グレード名_S Leather Package White Selection (MT)) + (-51.9187 * グレード名_S RHT) + (-23.4709 * グレード名_S Special Package) + (-17.8577 * グレード名_S Special Package (MT)) + (-19.1099 * グレード名_SILVER TOP) + (-20.9403 * グレード名_SILVER TOP (MT)) + (-96.8488 * グレード名_SP) + (-81.2540 * グレード名_SP (MT)) + (-34.0669 * グレード名_VS) + (-55.4974 * グレード名_VS RHT) + (-37.2449 * グレード名_VS RHT (MT)) + (-126.5272 * グレード名_VS コンビネーション A) + (-41.8984 * グレード名_VS コンビネーション B (MT)) + (-43.9137 * グレード名_プレステージエディション (MT)) + (-16.7889 * グレード名_ベースグレード) + (-22.0304 * グレード名_ロードスター) + (-54.2552 * グレード名_ロードスター ターボ) + (-47.5902 * グレード名_日本カー・オブ・ザ・イヤー受賞記念車) + (-98.5666 * 年_2005年モデル) + (-152.5217 * 年_2015年モデル)式の意味するところは、
新車価格*0.5183から、1km増えれば、-0.0006、年式上がれば8.8141/年で上昇。修復歴や、MT/AT(1 or 0)、エアロパーツ係数、モデルグレードを選択すると価格逆算されます。
予測価格からの差分
この予測式から実際価格との差分を計算し、割安な車両を見出せないかを検討します。コードは以下で、#9で計算させてます。
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import KFold, cross_val_score
from sklearn.impute import SimpleImputer
import numpy as np
# 1. データの準備
X = encoded_df.drop(columns='価格')
y = encoded_df['価格']
# 2. K-Fold クロスバリデーションの設定
kf = KFold(n_splits=5, shuffle=True, random_state=42)
# 3. 重回帰モデルのインスタンス生成
reg = LinearRegression()
# 4. 欠損値の確認・補完
imputer = SimpleImputer(strategy='mean')
X_imputed = imputer.fit_transform(X)
# 5. k-foldクロスバリデーションでモデルの評価
cv_scores = cross_val_score(reg, X_imputed, y, cv=kf, scoring='r2')
# 6. R^2 スコアの表示
print(f"K-Fold Cross-Validation R^2 scores: {cv_scores}")
print(f"Average R^2 score: {np.mean(cv_scores):.2f}")
# 7. モデルの訓練(全データを使用)
reg.fit(X_imputed, y)
# 8. 予測式の表示
print("Coefficients:", reg.coef_)
print("Intercept:", reg.intercept_)
print("予測式: \n")
print(f"価格 = {reg.intercept_:.4f}")
for coef, feature in zip(reg.coef_, X.columns):
print(f" + ({coef:.4f} * {feature})")
# 9. 予測値の計算
predicted = reg.predict(X_imputed)
# 10. 予測値をデータフレームに追加
encoded_df['predicted_price'] = predicted.round(2)
# print(encoded_df[['価格', 'predicted_price']].round(1))
# 11. 予測値と実際の価格の差分を計算
encoded_df['difference'] = (encoded_df['価格'] - encoded_df['predicted_price']).round(2)(web scrapingやデータクレンジングのコードは割愛しています。)以下が出力データで、予測式より安いものをいくつかみてみましょう。
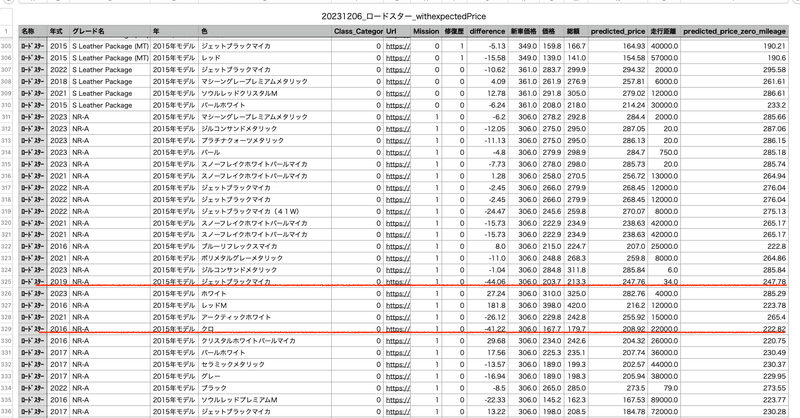
いや、、、安いでしょ。と思うのは私だけでしょうか。
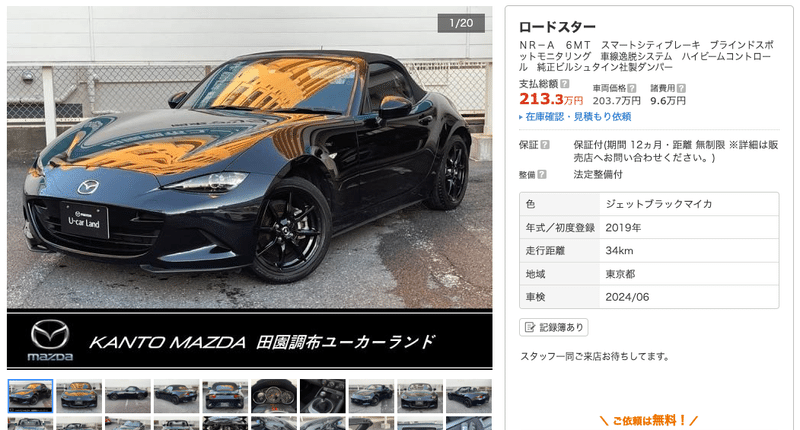
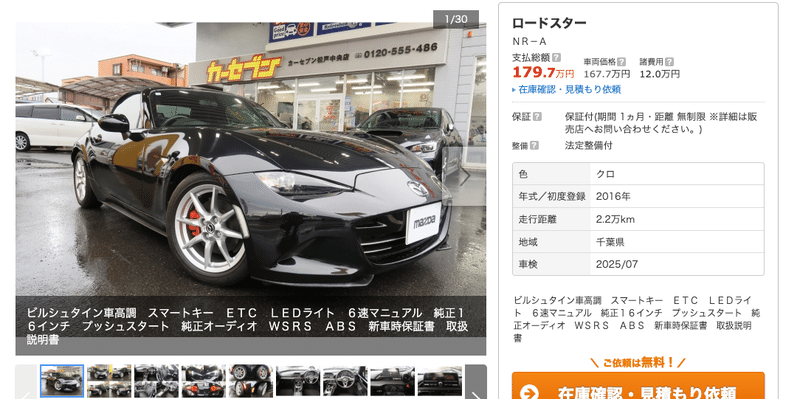
色々と価格調査していくうちに、web上の価格データって結構な頻度で更新されてることがわかりました。販売会社の思惑があってのことでしょうが、データを追っかけていると、1,2ヶ月で数十万単位の値上げ、値下げも確認されます。うまくすれば、相当購入費用が変わってきます。
欲しいと思った車をウォッチし続けることも必要ですね。
以上、中古車価格を分析でした。
価格の値上げ、値下げ、年間下落率、時系列価格変動などもみていきたいと思います。
この記事が気に入ったらサポートをしてみませんか?