
【TRILL】レコメンドシステムの改善検証と機械学習へのチャレンジについて

delyでバックエンドエンジニアをやっている安尾(@yusuke_yasuo)と申します。
最近はユーザーがTRILLアプリに夢中になって長時間見続けてしまう(沼る)ような体験を目指し、レコメンドシステムの改善を行っています。
本記事では弊社CTO井上さん(@gomesuit)の以下の記事で紹介されているレコメンドシステムに関して、直近約半年間で取り組んできたこと、今後チャレンジしていきたいことを紹介したいと思います。
なぜレコメンドシステムの開発を行っているのか
TRILL、UGCプラットフォームを目指す
TRILLは2021年にUGCプラットフォームへのチャレンジをスタートし、アプリ内のユーザー(以下、クリエイターと呼ぶ)が投稿する動画や画像がメインコンテンツとなりました。それによってTRILL内のコンテンツの数が大きく増加するとともに、より多様なコンテンツが投稿されるようになりました。
2021年はUGCプラットフォームとして最低限必要となる基礎的な機能の開発をしながら、TRILLユーザーにUGCの機能が受け入れられるかの検証を中心に行っていました。
そして、2022年の初旬まではレコメンドシステムに関しては手つかずの状態で、全てのユーザーに対して人気順、新着順などのシンプルなロジックでのレコメンドを行っていました。
「沼る体験」を届けるレコメンドシステムへの改善
UGC機能自体の価値検証を終え、コンテンツの増加スピードも上がってきたことに伴い、既存のレコメンドシステム(当時のロジックはレコメンドシステムと呼べるレベルではありませんでした)に対するチーム内での課題感が大きくなっていきました。
我々が目指す「TRILLアプリに沼る」体験をユーザーに届けるためにはレコメンドシステムを改善し、アプリを使えば使うほど自分にあったコンテンツがおすすめされるパーソナライズレコメンドを行うことが重要なのではないかという仮説のもと、2022年の初めごろ我々はレコメンドシステムの改善にチャレンジすることを決めました。
直近約半年間のレコメンドシステムの開発
目指すべきシステムを可視化する
最初に行ったのはレコメンドシステムを構成する要素を可視化し、これから開発するものに関してチーム内での目線を合わせることでした。
レコメンドシステムと一言で言っても様々な実現方法があり、どれを選ぶかでかかるコストやレコメンドの精度が大きく異なります。TRILLにはレコメンドシステムの開発に関する知見がお世辞にも豊富とは言えない状況だったため、目指すレコメンドシステムのイメージもメンバーによって千差万別でした。
そのため、まずはリサーチを行った上でこれらを可視化することでチーム全員の目線を合わせた上で議論が行える状態を目指しました。
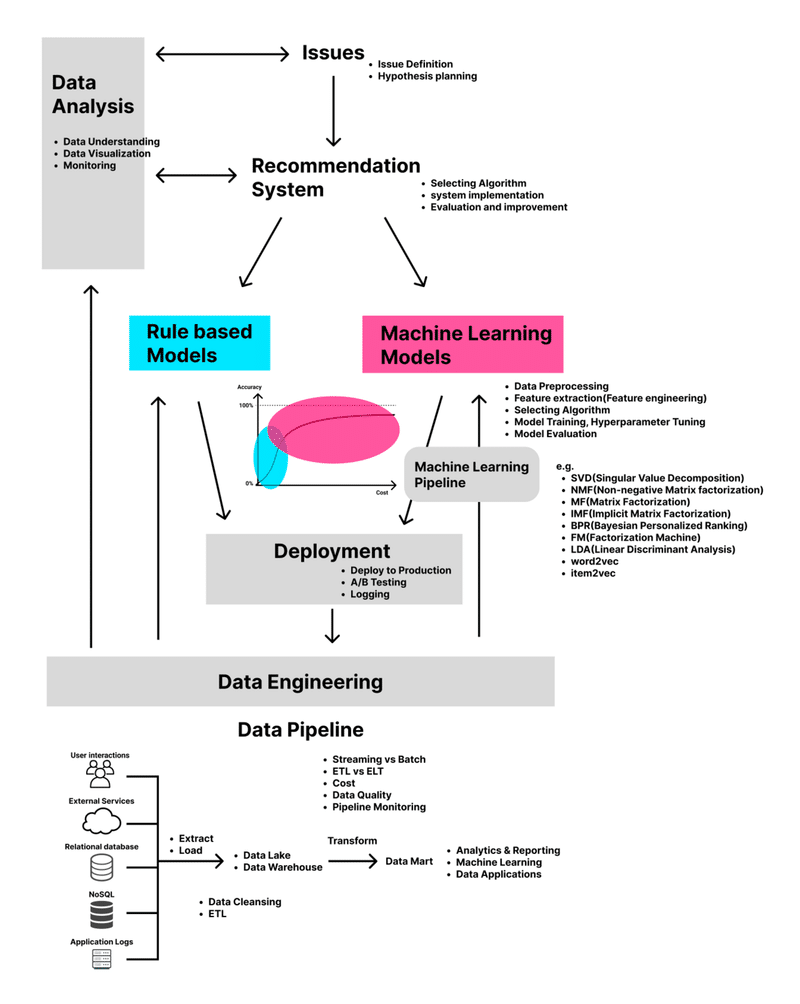
機械学習を用いない、という選択
世の中で注目されているレコメンドシステムと言えば、全てと言っても過言ではないほど機械学習を用いて実現されており、インターネット上の記事や書籍を探しても機械学習によるレコメンド手法を中心に解説されているものが大半でしたが、我々はレコメンドシステムの実現方法の違いによるコストと精度の関係性に着目し、まずは機械学習を用いずルールベースのレコメンドシステムを低コストで開発し、パーソナライズレコメンドによってユーザー体験は本当に向上するという仮説の検証を行うことを決めました。
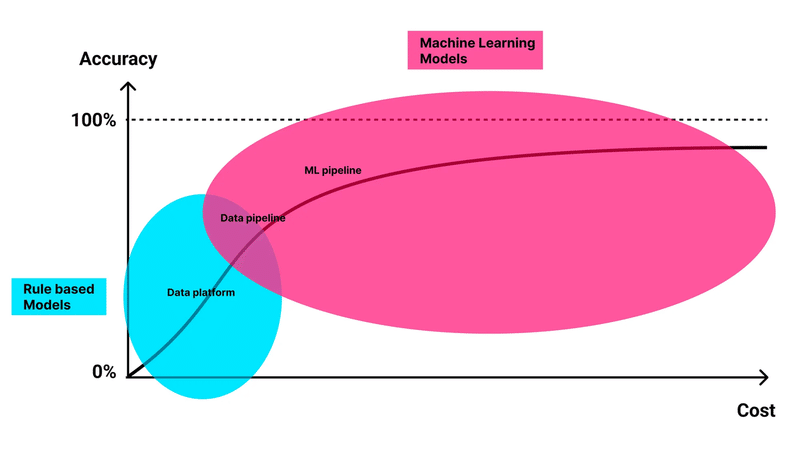
検証1. パーソナライズレコメンドによってユーザー体験は向上するのか
具体的にどのようなルールでレコメンドを行うか考える際には、まず競合プロダクトを使い込み、プロダクト内でどのような行動を行うとレコメンド結果がどのように変化するのかということを調査するところからはじめました。
そして調査結果をもとに、なるべくシンプルな形でパーソナライズレコメンドの効果検証をするための方法として以下のような仕様を考えました。
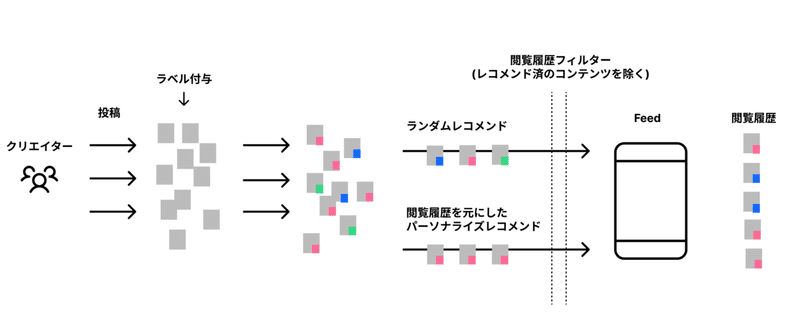
まずクリエイターが投稿したコンテンツに対してラベルを付与することで、コンテンツを分類可能にします。
その上でユーザーの閲覧履歴に含まれるコンテンツのラベル情報を用いてユーザーの興味関心を推測し、その結果に基づいてコンテンツをレコメンドするという仕様です。
閲覧履歴がない場合はランダムレコメンドを行い、ユーザーがひとつでもコンテンツを見れば、その閲覧履歴をもとにリアルタイムに次のリクエストからはパーソナライズレコメンドが行われます。
シンプルな仕様ですが、実際にユーザーとして試してみると自分の行動によってレコメンドされるコンテンツがすぐに変わり、自分の興味に沿ったコンテンツのレコメンド比率が明らかに増えるので十分にパーソナライズされているという感覚を得ることができました。
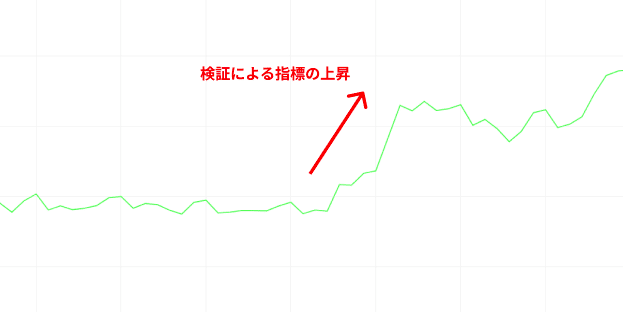
また1ユーザーとしての定性的な感覚だけでなく、モニタリングをしていた各種指標も飛躍的に向上することが確認できました。
検証2. パーソナライズレコメンドの精度向上によって更にユーザー体験は大きく向上するのか
パーソナライズレコメンドによってユーザー体験が向上させられることは無事確認ができましたが、さらに継続してレコメンドシステムへの投資を行っていくか意思決定するためにも、レコメンドの精度向上によって更にユーザー体験は大きく向上するということを証明する必要がありました。
パーソナライズレコメンドの精度を向上するにあたって参考にしたのは、TikTokの「Flow Pool」という仕組みでした。
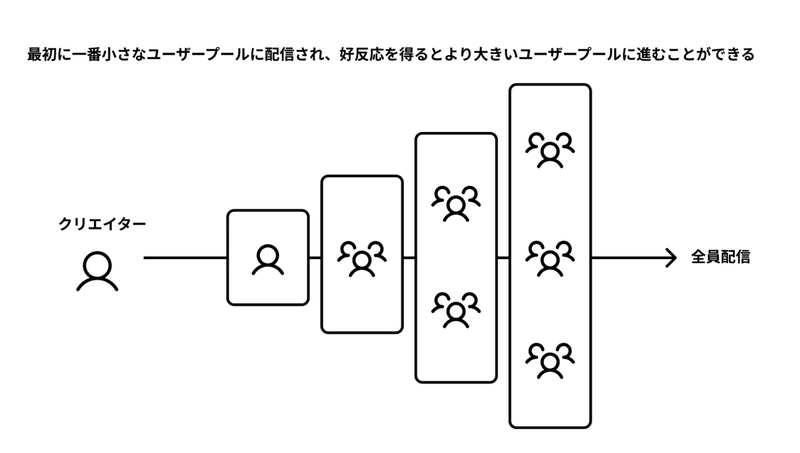
「Flow Pool」とは上の図で示すように、クリエイターが投稿したコンテンツは最初に一番小さなユーザープールに配信され、そのプール内で好反応を得ることができればより大きなユーザープールに配信されていくという仕組みです。
この仕組みによって、評価が低いコンテンツのレコメンドをすばやく止め、評価が高いコンテンツはより多くのユーザーに配信することが可能になります。
TikTokと今のTRILLではユーザー数やコンテンツ数が大きく異なるため、この仕組みをTRILLに合わせた形にアレンジした上で検証を行いました。
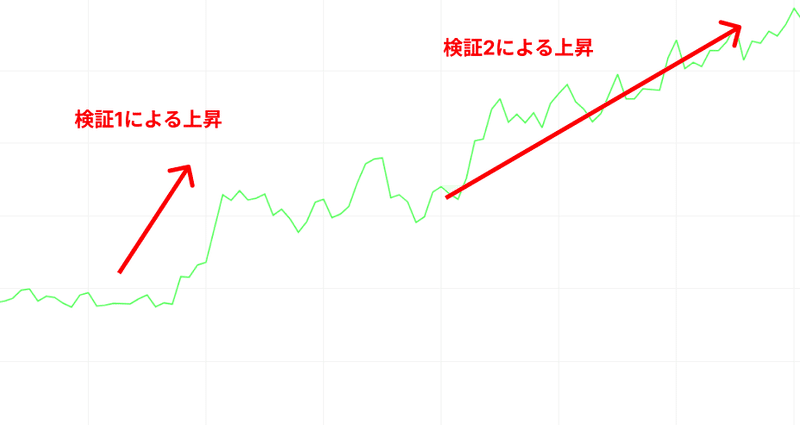
結果は検証1以上に良い結果を得ることができました。
まず定性的な感想として、明らかにレコメンドされるコンテンツのクオリティが高くなりました。自分自身そう感じるとともに他の社内メンバーからも同様のフィードバックを多くもらうことができました。
また、今回についても各種モニタリング指標が大きく向上することが確認できました。
機械学習ベースのレコメンドシステムの実現へチャレンジします
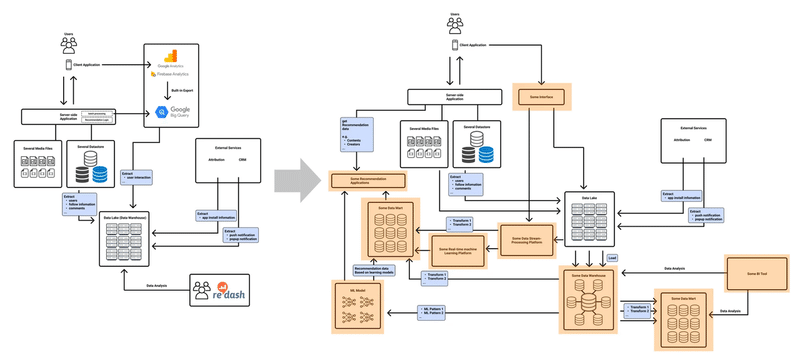
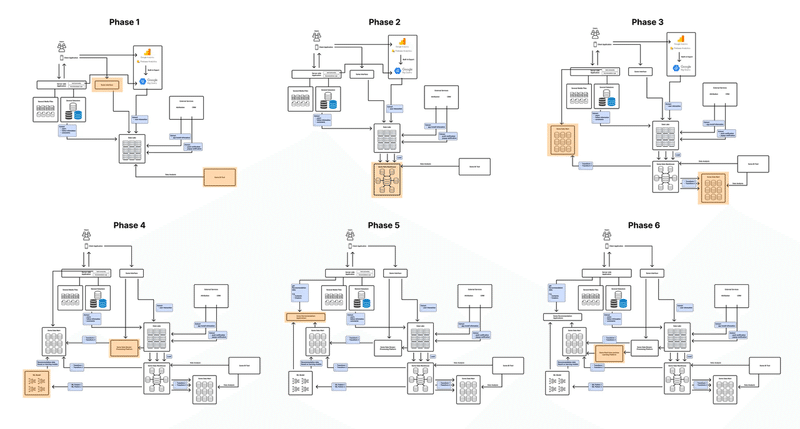
この半年間の取り組みによって、パーソナライズレコメンドの精度向上がユーザー体験向上に大きく寄与することが確認できたため、今後は更にレコメンドシステムの精度向上に投資し、いよいよ機械学習ベースのレコメンドシステムの実現にチャレンジしていきます。
そのためにはデータ基盤、ML基盤の構築など大幅なアーキテクチャの見直しが必要となるため、将来像の可視化するとともに実現フェーズを区切り、それをこれから一歩一歩進めていく予定です。
最後に
TRILLではレコメンドシステムの精度向上への投資が決まり、これから機械学習導入に向けたチャレンジを行っていくとても面白いタイミングです。
僕自身、機械学習の活用には前々からチャレンジしたいと思っていたため、いよいよそのフェーズが来たかと、とてもワクワクしています!
ゼロから機械学習ベースのレコメンドシステムの実現をリードしていただける機械学習エンジニアの方はもちろん、まだ実務では触ったことがないけれど「機械学習には興味がある」というバックエンドエンジニアの方も積極募集しておりますので、是非お気軽にカジュアル面談などご応募いただけると嬉しいです!
その他の職種に関しても幅広くメンバーを募集しています!(PdM / iOS / Android / バックエンド [データ / インフラ / ML] / UI/UXデザイナー)
この記事が気に入ったらサポートをしてみませんか?