
学術研究!日本姓氏語源辞書から名字の情報をスクレイピングする

日本姓氏語源辞書とは?
日本姓氏語源辞典は、日本の姓氏に関する語源や由来を探求する辞書です。これは、日本の姓氏がどのように生まれ、発展してきたかを解明するための専門的な資料やリソースです。日本の姓氏は、古代から現代に至るまで、さまざまな時代や地域の影響を受けながら発展してきました。そのため、姓氏の語源や意味には多くの謎や興味深い話が含まれています。日本の姓氏に関心のある人々や学者、歴史愛好家にとって貴重な情報源となっています。姓氏の語源や由来に興味がある方は、このような辞典を活用することで、より深い理解を得ることができるでしょう。
スクレイピングツールの概要
ScrapeStormとは、強い機能を持つ、プログラミングが必要なく、使いやすい人工知能Webスクレイピングツールです。違う基盤のユーザーに二つのスクレイピングモードを提供し、1-Clickで99%のWebスクレイピングを満たします。ScrapeStormにより、大量のWebデータを素早く正確的に取得できます。手動でデータ抽出が直面するさまざまな問題を完全に解決し、情報取得のコストを削減し、作業効率を向上させます。
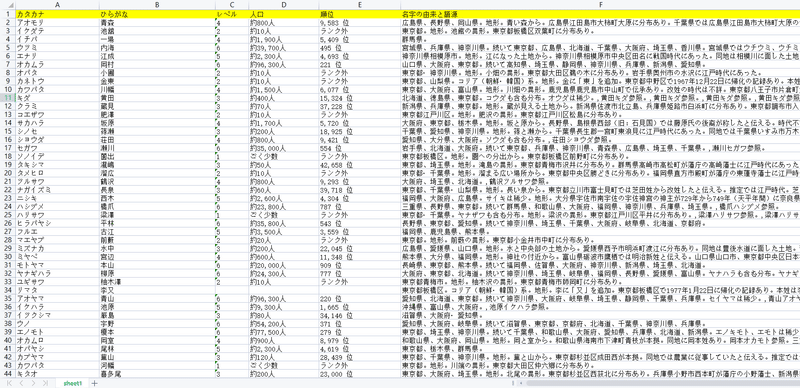
抽出されたデータをご覧ください。
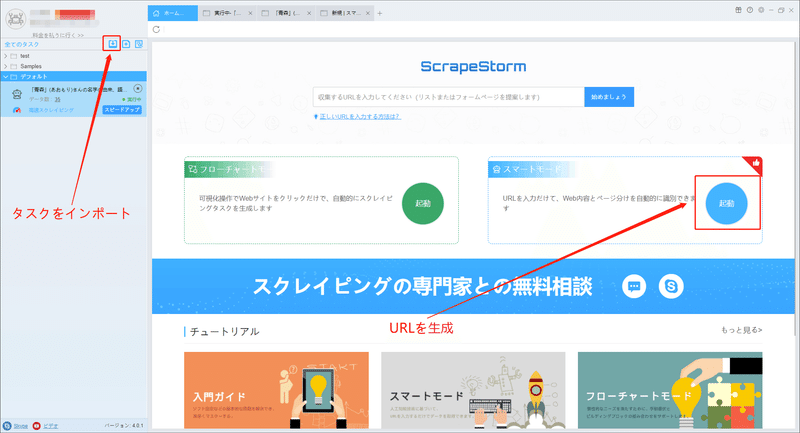
1.タスクを新規作成する
今回はURLジェネレーター機能を利用して、名字によってURLを生成します。
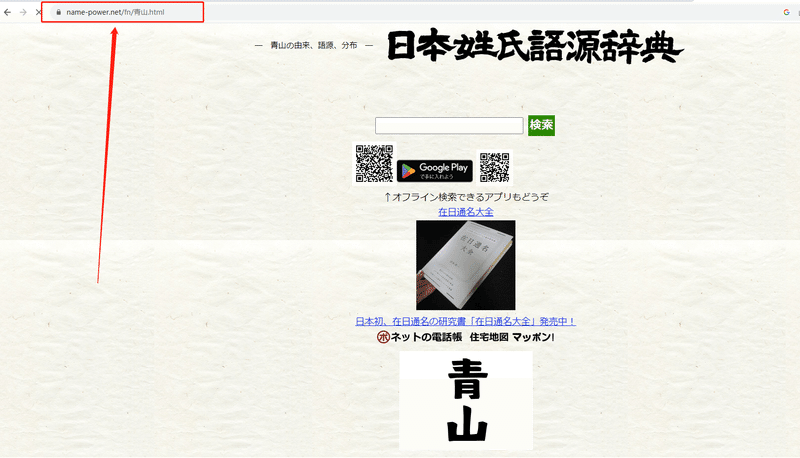
(1)URLをコピーする
まず、一つの名字を入力し、その検索結果のURLをコピーしてください。
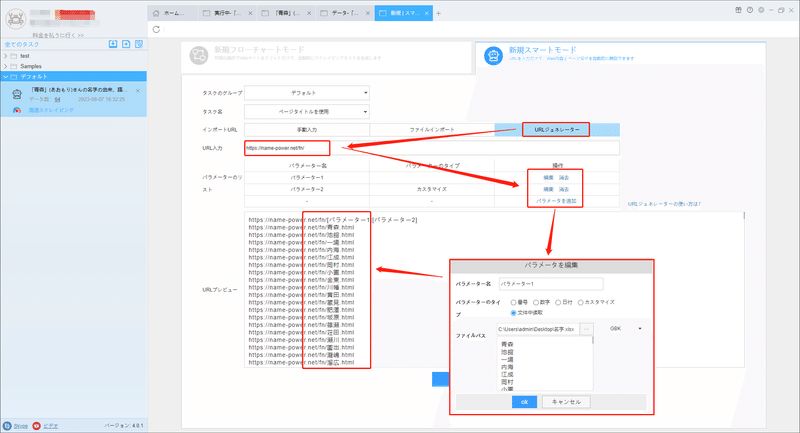
(2)パラメーターを追加する
「ファイルから読み込む」を選んで、名字を入力します。そして、「カスタマイズ」を利用し、パラメータを入力します。生成したURLはプレビュー画面でチェックしてください。
2.タスクを構成する
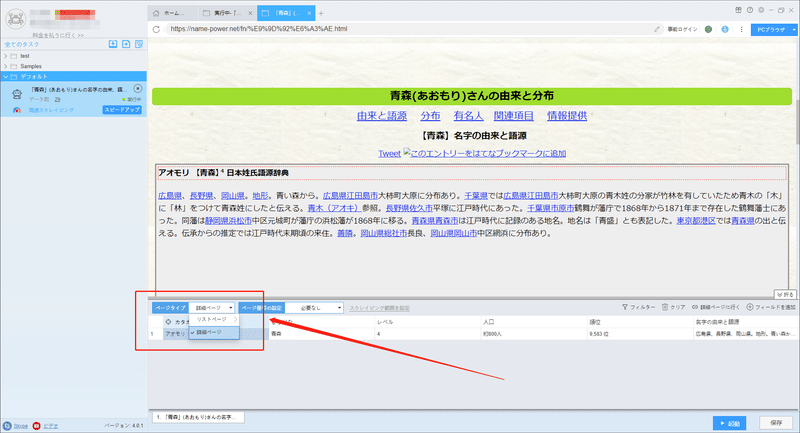
(1)ページタイプ
通常、ScrapeStormは自動的にリスト要素とページボタンを識別できますが、今回生成したリンクは詳細ページのリンクから、「ページタイプ」を詳細ページに変更してください。下記のチュートリアルも参照してください。
ページタイプの設定方法
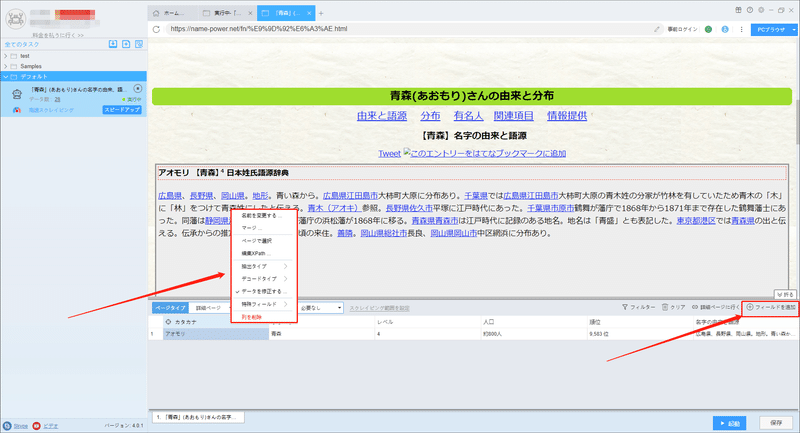
(2)フィールドの追加と編集
「フィールドを追加」ボタンをクリックして、画面に必要な要素を選択、データが自動的に抽出されます。また、必要に応じてフィールドの名前の変更または削除、結合できます。
フィールドの設定の詳細には下記のチュートリアルをご参照ください。
抽出されたフィールドを配置する方法
3.タスクの設定と起動
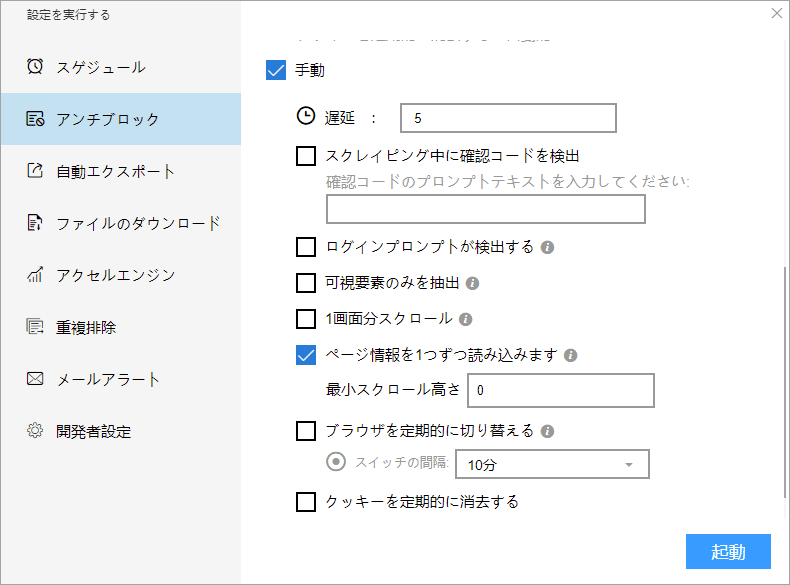
(1)起動の設定
必要に応じて、スケジュール、アンチブロック、自動エクスポート、写真のダウンロード、スピードブーストを設定できます。サーバーに負荷しないように、遅延時間を設定してください。5秒以上を推薦します。スクレイピングタスクを配置する方法については、下記のチュートリアルをご参照ください。
スクレイピングタスクを配置する方法
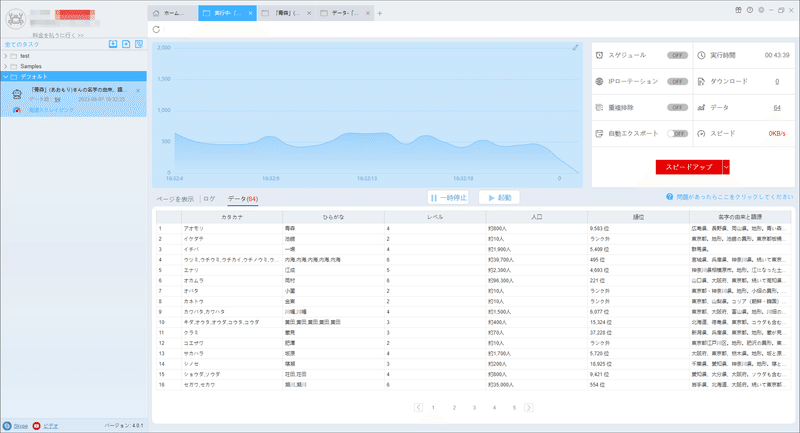
(2)しばらくすると、データがスクレイピングされる。
4.抽出されたデータのエクスポートと表示
(1)エクスポートをクリックして、データをダウンロードする
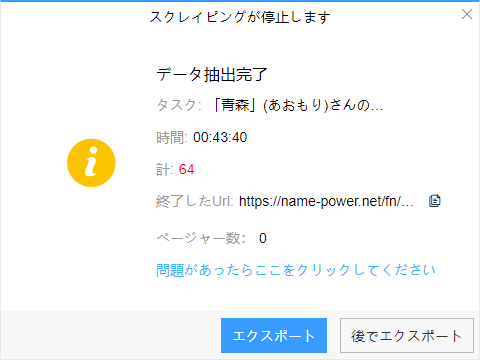
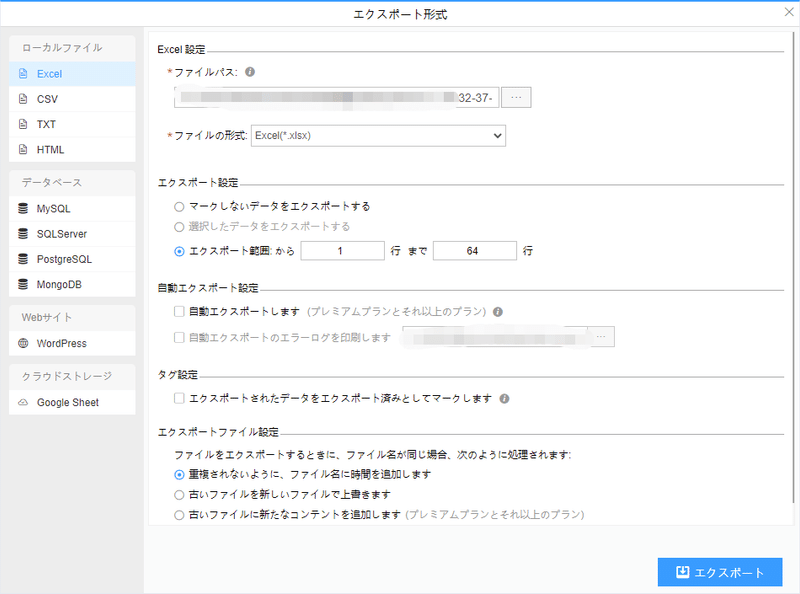
(2)必要に応じてエクスポートする形式を選択します。
ScrapeStormは、Excel、csv、html、txt、データベース、ローカルなどさまざまなエクスポート方法を提供します。抽出結果のエクスポート方法の詳細には下記のチュートリアルをご参照ください。
抽出されたデータのエクスポート方法
注意:法律違反しないため、抽出されたデータを悪用禁止です!
この記事が気に入ったらサポートをしてみませんか?