
知らないとやばい! AI時代の最先端を走る StreamDiffusion とは?リアルタイム画像生成を体験しよう!

新年明けましておめでとうございます。
葉加瀬あいの「新年一発目」の記事は今の生成AIの時代を先取る『Stream Diffusion』について解説したいと思います。
StreamDiffusion 自体は、2023年12月の下旬にリリースされた技術ですが、既に葉加瀬のYouTubeも含めて多くの方が導入方法についての解説をしているので、今回の記事では、『StreamDiffusion とは?』と、いうことで、Stream Diffusionの概要や特徴、性能、動画、基礎知識、応用例などを詳しく解説していきたいと思います。Stream Diffusionに興味がある方は、ぜひ最後までお読みください。
また、導入に関しては以下のYoutubeでも解説しているので、本稿と合わせてこちらも見ていただいて、動画が良いと思ってくれたらチャンネル登録や👍ボタンなどもよろしくお願いします。
それでは、解説していきたいと思います。
Stream Diffusionとは何か?
Stream Diffusionとは、GitHubトレンドランキング1位のAIツールとして話題になっている画像生成AIツールにます。
そして、実態としてはStable Diffusion WebUI やComfyUIのようなウェブ上で動作するツールではなく、『パイプライン』といったものになります。
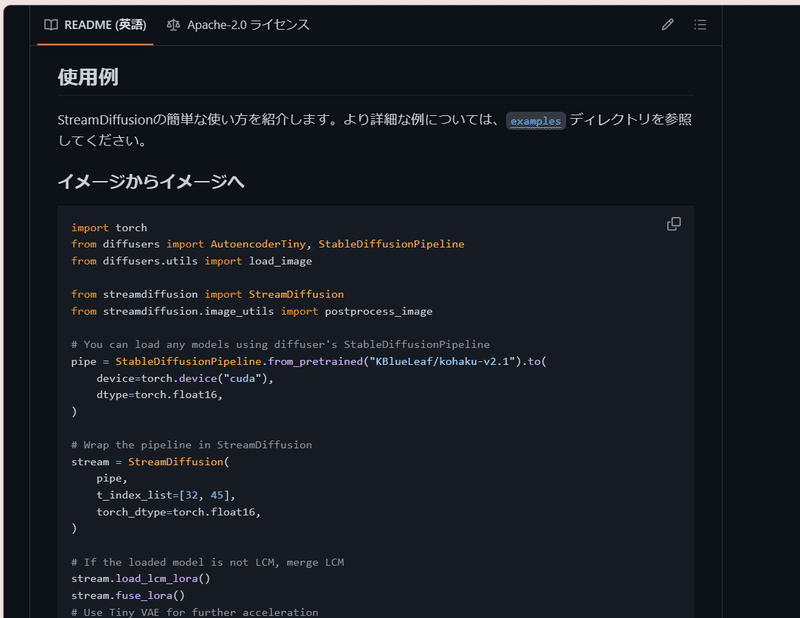
パイプラインとは、複数の処理を連結して一連の流れを作るプログラミングの仕組みのことで、Stream Diffusionでは、これによって入力から画像生成までの各段階を効率的に管理しています。
また、Stream Diffusionは、日本人研究者らによって開発され、オープンソースとして公開されているので、誰でも無料で利用でき、ドキュメントもとてもわかりやすく書かれているのが特徴です。
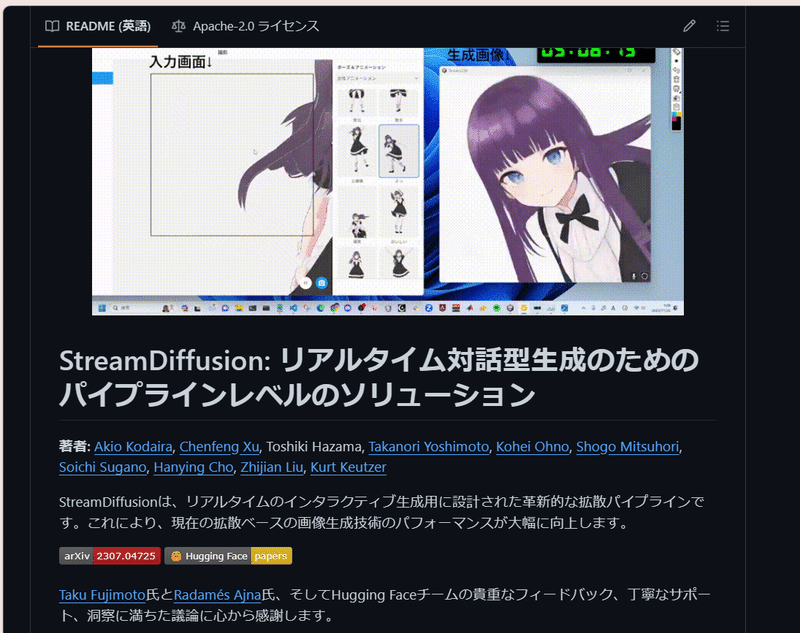
そして、何よりもStream Diffusionの最大の特徴は、リアルタイムで高品質な画像を生成できるということです。これは、従来の画像生成AIと比較して飛躍的な速度向上を実現したことを意味しており、Stream Diffusionでは、テキストや画像などの入力に応じて、リアルタイムで、超高速に、動的に背景やオブジェクトなどの画像を生成することができます。また、Stream Diffusionは、さまざまなツールとの連携や環境構築の方法も紹介しているので、初心者でも簡単に使うことができます。

なお、ControlNetやSDXL などは、まだ使えないということで、Stable Diffusion WebUI のように、ウェブ上でわかりやすく使う方法についても、互換性の問題でまだ実装は先になる気がしています。
実行に必要なVRAMは10GBほどで、ミドルレンジのグラフィックボードやクラウドサービスでも十分に動かすことが可能です。
また、以下のように『イラスト⇨リアル』はデフォルトでは難しくなっています。おそらくDenoising という設定で元画像にかけるノイズの量を減らしているためだと思われます。つまり、「絶対にできない」というわけではないので、その点はご安心ください。

Githubはこちら!
Stream Diffusionの特徴は何か?
Stream Diffusionは、リアルタイムで高品質な画像を生成できる画像生成AIのパイプラインですが、ここでは、Stream Diffusionが他の画像生成AIと比べて優れている点を5つ紹介します。
バッチ処理によるデータ処理の効率化
画像生成AIでは、入力データをモデルに渡す際に、一つずつ処理するのではなく、複数のデータをまとめて処理することで、待ち時間を削減することができます。これをバッチ処理と呼びます。Stream Diffusionでは、独自の効率的なバッチ処理方式を採用しています。これにより、画像生成の速度を向上させるとともに、画像の品質も保つことができています。
計算の冗長性を最小限に抑えるガイダンス
画像生成AIでは、入力から画像生成の目標を指定することで、不要な計算を省くことができます。これをガイダンスと呼びます。Stream Diffusionでは、分類器に依存しないガイダンスを改善し、冗長な計算を削減することができます。つまり、これにより、画像生成の精度を高めるとともに、計算コストを抑えることができていると言うことです。
GPUの使用効率を最大化するフィルタリング
画像生成AIでは、画像処理に特化した演算装置であるGPUの性能を最大限に引き出すことがカギとなってきますが、GPUの使用効率は、画像の内容や変化、実行するアルゴリズムなどによって変わります。その点、Stream Diffusionでは、類似度によるフィルタリングで、GPU使用効率を最大化することができ、画像生成の速度を保つとともに、消費電力を最適化することができます。
入出力操作を効率的に管理するキュー
画像生成AIでは、データの読み書きや送受信などの入出力操作を効率的に管理することがで、これをキューと呼びます。Stream Diffusionでは、データ入力とモデルスループットの頻度差を扱うため、処理を並列化することができます。これにより、画像生成のスムーズさを向上させるとともに、入出力の遅延を防ぐことにつながっています。
モデルの最適化と性能向上を実現するツール
画像生成AIでは、画像生成のための人工知能であるモデルを高速化や安定化などの面で改善することができ、Stream Diffusionでは、画像生成AIの一般的な手法であるスコアベース手法の一種であるStable Diffusionをベースにしています。これにより、画像生成の品質を向上させるとともに、モデルの最適化と性能向上を実現しています。
Stream Diffusionの性能はどれくらいか?
ここでは、Stream Diffusionがどのくらいの速度で画像を生成できるか、また、どのような環境で動作するかについて紹介します。
RTX 4090なら1秒間に100枚以上の画像を生成できる
Stream Diffusionの開発者は、最新のグラフィックボードであるRTX 4090を使って、Stream Diffusionの性能をテストしたのですが、その結果、1秒間に100枚以上の画像を生成できることが分かりました。これは、従来の画像生成AIと比較して圧倒的な速度で、RTX 4090自体、グラフィックボード単体でも約30万円ほどするものではありますが、このような高性能なグラフィックボードを使えば、Stream Diffusionの性能を最大限に引き出すことができます。

16GBほどの一般的なクラウド環境でのグラフィックボードなら1秒間に20枚ほど生成可能
もちろん、RTX 4090のような高価なグラフィックボードを持っていなくても、Stream Diffusionを使うことはできます。例えば、クラウドサービスを利用する場合、12~16GBほどの一般的なグラフィックボードであれば、1秒間に20枚ほどの画像を生成できます。大体、16FPSと言った、1秒間に16枚ほど生成できる位の速度があれば、動画等しては成り立つので、これはまだ十分な速度で画像を生成できると言えます。
また、Google colabやpaperspace、Amazon Sagemaker Studio Lab などのクラウドサービスでは、インターネット経由で16 GBほどのグラフィックボードなどのコンピュータリソースを利用できるので、そのようなものを使用すれば、自分のPCのスペックに関係なく、Stream Diffusionを実行できます。
また、Stream Diffusionを、クラウド環境で使用する方法に関しては、後ほど、紹介したいと思います。
高速化オプションがあるが、機能するまでに時間かかる
Stream Diffusionには、画像生成の速度をさらに上げるためのオプションが用意されています。例えば、TensorRTやXFormersなどのツールを利用することで、モデルの最適化や性能向上を実現できます。しかし、これらのオプションを使うには、初回の起動時に時間がかかることに注意してください。これは、オプションを使うために必要なライブラリのインストールや設定などが行われるためです。
#速度アップ
python screen/main.py --acceleration tensorrt⚠ 本題に移る前に、メンバーシップの説明をさせてください。
🎈 たった一晩でプロのイラストレーターになれるメンバーシップ 『あいラボ (AI-Labo)』
このブログでは、月980円で私が書いた有料記事が全て読み放題になるメンバーシップに加入することができます。
有料記事では、生成AI を使った創造的なコンテンツをお届けしています。
具体的には、以下のようなものがあります。
どんなPCでも、たとえスマホでも Stable Diffusion XL(SDXL)を無料 or 低額で使用する方法
SDXL を使用するには VRAM16GB 以上のGPUを搭載したPCが必要であり、そのスペックのものを購入しようとすると最低でも30万円はします。
これを、ある方法を利用することで無料もしくは低額で利用できますので、実質 約30万円 が丸々お得になります。
👇 詳細は以下クリック👇(マガジンにまとめてあります。)
SDXL で思い通りの画像を生成して、自分の絵をもっと好きになる方法
Stable Diffusion は最も画像生成の幅が広く大変機能の充実したジェネレーティブAI ですが、使いこなすにはコツがあります。
実は、少し工夫を加えるだけで生成画像のクオリティが格段に良くなるのですが、あまり多くの人はその方法を使っていません。
つまり、その方法を使うだけで、例え初心者であってもすぐに周りを追い越すことができます。その最短距離をお教えします。
👇 詳細は以下クリック👇(マガジンにまとめてあります。)
SNS を自動化して、Stable Diffusion を使ったSNS運用をする方法
SDXLの導入と画像生成のコツがわかったら、次はSNSなどで発信して、ポートフォリオを作り副業にしたり、社会貢献に使ったりなどなど、色々な道があると思います。
そのため、Stable Diffusion の知識に加えて、SNSを自動化する方法も案内しています。ここでは、SNSで毎日決まった時間に画像付きの投稿をする方法などもまとめておりますので、毎日のSNS運用がぐっと楽になるはずです。そうして空いた時間を、画像生成や他の活動に回すこともできます。
👇 詳細は以下クリック👇(マガジンにまとめてあります。)
このように、メンバーシップではこれらの記事が全て読み放題になり、その中には通常は3000円近い有料記事も含まれていますので、今ならそれらも980円で閲覧できる事になります。
今が最もお得な時期になりますので、是非メンバーシップに登録して生成AIの魅力を体験してみてください!
👇 以下をクリックして、すぐに登録できます👇
それでは、続きを解説していきたいと思います。
Stream Diffusionの動画
冒頭でも説明しましたが、Stream Diffusionの導入方法に関しては、葉加瀬がこちらでYouTubeの動画を撮影しているので、そちらをご覧ください。
この動画では、Stream Diffusionの概要やインストール方法、リアルタイムで画像を生成する方法などを紹介しています。動画の中で、Stream Diffusionがどのくらいの速度で画像を生成できるか、また、どのような画像を生成できるかを確認できます。
また、Stream Diffusionは、テキストや画像を入力として、それに応じた画像を生成できます。例えば、「1girl with brown dog hair, thick glasses, smiling」というテキストを入力すると、そのような女の子の画像を生成できます。具体的には、以下のようにオプションを入力することによって、プロンプトの変更やモデルの変更などができますので、ぜひお試しください。
#プロンプトの入力
python screen/main.py --prompt "a girl with red hiar, realitc"
#モデルを選択
python screen/main.py --model_id_or_path "モデルの場所\beautifulRealistic_v7.safetensors"なお、ComfyUIを使用することもできます。
ComfyUIに関しては以下の記事で詳しく解説しておりますので、ご参照ください。
ワークフローは以下になります。
ここから先は
この記事が気に入ったらサポートをしてみませんか?