実用化を目指す。最新版画像が読めるAI MiniGPT-v2にマルチセッション対応APIを追加

過去に何度か記事にしていますが、MiniGPT4-v2 (MiniGPT-Vという記述もあるんです)はとても素晴らしいマルチモーダルLLMです。ローカルで10GByte程度のVRAMでここまでできることは驚きです。簡単に紹介しますと、
1)画像全体の印象を表現できる
2)画像から複数の主な物体の検出ができて、ラベリングをしてくれる
3)指定した物体を検索し、位置を指定してくれる
4)指定したエリアに有る物体が何なのか答えてくれる。
5)これらの結果を元に色々とチャット形式で質疑応答してくれる
今回はプログラムから実用的に使えることを考慮してAPIを開発しました。
目次
1,実用性への配慮
2,MiniGPTの処理過程
3,セッション管理とクラス化
4,FastAPIによるASOGwebサーバAPIの実装
5,サーバコード
6,APIのテスト
7,クライアント側APIクラスの実装
8,gradioによるクライアント側アプリケーションの例
9,様々な利用例
10、Githubリポジトリ
1,実用性への配慮
公開されているリポジトリではDemoを動かすことが出来ます。解析するとどのように推論してるのかはわかるでしょう。利用している関数を呼べばいい、それだけなんですけど、Demoコードがgradioと密接に絡んでいて、コードを解析するのは大変です。更に厄介なのは実用的にプログラムから推論を利用するためには、どんな引数を準備するのか、そしてどのような出力が得られるのか、を調べなくてはなりません。さらに、オリジナルのDemoでは推論過程やチャットのログをgradioのstate()で管理しているため、推論関数を呼ぶためチャットステートの管理を行わないと複数のチャットセッションが維持できない問題があります。通常のローカルLLMですと、チャットのログは容易にユーザーで管理できるわけですが、マルチモーダルでは画像を基に様々なタスクをこなしていくため、画像や位置情報などをセッション毎に管理しなくてはなりません。今回、実用性を重点においてこれらの懸案点を解消したマルチセッション対応APIをMiniGPT-v2に適応し、推論サーバとクライアントを分離できるようにしました。複数のクライアントから共同利用できること以外にも単一アプリで複数のセッションを並行して扱うことが出来ます。
2,MiniGPTの処理過程
MiniGPTシリーズは以下のような過程で推論を進めます。
1)画像のアップロード(対象画像をGPUへアップロード)
2)画像に対して質問をする(タスク指示、プロンプト、位置情報)
3)回答を得る(推論)
4)結果を視認できるように加工する
ここで、マルチセッションの場合は1)の前にセションkey生成(新規セッションクエスト)が入ります。
1)〜4)まで画像は保持し続ける必要がありますし、4)では画像も出力されてきます。また3)では文字情報に位置情報やラベルなど記号が多用された文が生成されてきます。そのために4)で文章を分離し、位置情報を基にバウンディングboxを記入したり、ラベルを作成したりします。
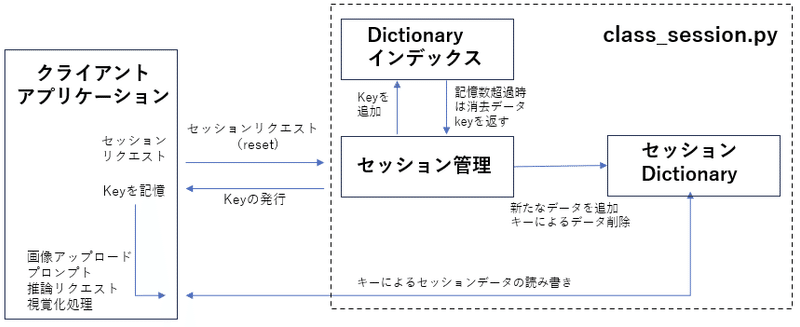
3,セッション管理とクラス化
通常のサービスですとセッション管理はcookieやクライアント側で持つセッション番号などとデータを紐づけしてD/Bで管理する手法が取られていると思います。今回もMySQLやSQL-lightを利用することも考えました。しかし、用途が汎用サービスではないので大掛かりにはしたくないしD/Bの管理も簡単に済ませたいと考え、dictionaryで管理する方法を取りました。Pythonのdictionaryはjesonとよく似ていますが、値やオブジェクトが保持できることがjsonとの大きな違いです。今回でいうとPillowのイメージオブジェクトなどです。一方でdictionaryの保持順番が保証されるかという問題もあります。最新のPythonだと保持されるようですが、万が一のことを考慮し、あえてリスト形式のdictionaryインデックスを持つことにしました。
以下は管理の流れです。
クライアントから新たなチャットセッション開始のリクエストが来るとKEYを発行し、dictionaryにKEYをキーとする新たなdictionary型のデータを追加します。同時にdictionaryインデックスリストにKEYを追加し、dictionaryインデックスリストが予め定められた数よりも大きくなれば、最も古いKEYとそのKEYに該当するdictionary内データを削除します。
セッションデータ
self.chat_sessions[key] = { "chatbot": [], "chat_state": None, "gr_img": [], "img_list": [], "upload_flag": 0, "replace_flag": 0, "out_image": None, }
4,FastAPIによるASOGwebサーバAPIの実装
FastAPIは高速なASOGwebサーバAPI構築にはよく利用されます。非同期処理によるマルチプロセス化が標準で行われており、高速なサーバを構築できます。ASOGwebサーバAPIにおいてはリクエストBodyはjeson形式が用いられています。また返り値も通常はjeson形式です。jeson形式は見かけ上はdictionaryと同じですが、文字列データでありdictionaryのようにオブジェクトは収容出来ません。そのため、画像データ(例えば音声データも同じ)を送受信する場合は、FastAPIエンドポイントがバイナリデータを受け取り、BytesIOを使用してPIL形式の画像に変換します。送信時は逆になります。
サーバ側
from fastapi import FastAPI, HTTPException
from PIL import Image
from io import BytesIO
app = FastAPI()
@app.post("/upload/")
async def upload_image(image_data: bytes):
try:
# バイナリデータをPIL形式に変換
pil_image = Image.open(BytesIO(image_data))
# ここでpil_imageを使用して必要な処理を行うことができます
# 例えば、画像の処理や分類、保存など
return {"message": "Image received and converted to PIL format."}
except Exception as e:
raise HTTPException(status_code=400, detail=str(e))
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)クライント側
テストコード、client_upload.pyです。
import requests
from PIL import Image
from io import BytesIO
# 送信するPIL形式の画像データ
image_file_path = '00016-331097358.png'
# FastAPIエンドポイントのURL
url = 'http://0.0.0.0:8001/uploadfile/' # FastAPIサーバーのURLに合わせて変更してください #Maskを作成 。IDENTIFYタスクで使う。その他の場合はイメージと同じ大きさのファイルを作成
pil_image=Image.open(image_file_path )
width, height = pil_image.size
mask = Image.new('L', (width, height), 0)
# ファイルデータをバイナリ形式に変換
img_byte_arr_m = BytesIO()
mask.save(img_byte_arr_m, format='PNG')
mask_img = img_byte_arr_m.getvalue()
# ファイルデータをバイナリ形式で読み込む
file_data = open(image_file_path, "rb").read()
# ファイルをアップロードするためのリクエストを作成
files = {
"file": ("img.png", BytesIO(file_data), "image/png"),
"mask": ("mask.png", BytesIO(mask_img), "image/png"),
}
# POSTリクエストを送信
response = requests.post(url, files=files)
# レスポンスを表示
if response.status_code == 200:
result = response.json()
print("サーバーからの応答message:", result.get("message"))
print("サーバーからの応答chatbot:", result.get("chatbot"))
else:
print("リクエストが失敗しました。ステータスコード:", response.status_code)複数の画像データの送受信も同様に可能ですし、jeson形式のデータとの混在も可能です。
5,サーバ側コード
構成は以下のとおり
class_chat_session.py セッション管理用クラス
minigpt_v2_api_r2.py サーバ本体(FastAPIサーバとLLM関数の呼び出し)
function.py サーバ本体で利用する各種の関数群
class_chat_session.py セッション管理用クラス
以下のような5つのメソッドから構成されています。
create_session 新たにセッション(+KEY)を作成、削除
read KEYを用いた特定データの読み出し
write KEYを用いた特定データの書き込み
read_all KEYを用いた全データの読み出し
write_all KEYを用いた全データの書き込み
import pprint
class ChatSession:
max_sessions = 10 # 最大セッション数の設定
def __init__(self):
self.chat_sessions = {}
self.session_keys = []
def create_session(self, key):
"""新しいチャットセッションを作成する"""
if key in self.chat_sessions:
raise ValueError("Session key already exists.")
self.chat_sessions[key] = {
"chatbot": [],
"chat_state": None,
"gr_img": [],
"img_list": [],
"upload_flag": 0,
"replace_flag": 0,
"out_image": None,
}
self.session_keys.append(key)
if len(self.session_keys) > ChatSession.max_sessions:
first_key = self.session_keys.pop(0)
del self.chat_sessions[first_key]
pprint.pprint(self.chat_sessions)
#print (self.session_keys)
def read(self, key, sub_key):
"""指定されたキーのデータを読み取る"""
return self.chat_sessions[key][sub_key]
def write(self, key, sub_key, data):
"""指定されたキーのデータを書き込む"""
self.chat_sessions[key][sub_key] = data
#pprint .pprint(self.chat_sessions)
def read_all(self, key):
"""特定のキーのすべてのデータを読み取る"""
session = self.chat_sessions[key]
return (session["chatbot"], session["chat_state"], session["gr_img"],
session["img_list"], session["upload_flag"],
session["replace_flag"], session["out_image"])
def write_all(self, key, data):
"""特定のキーのすべてのデータを書き込む"""
session = self.chat_sessions[key]
session["chatbot"] = data["chatbot"]
session["chat_state"] = data["chat_state"]
session["gr_img"] = data["gr_img"]
session["img_list"] = data["img_list"]
session["upload_flag"] = data["upload_flag"]
session["replace_flag"] = data["replace_flag"]
session["out_image"] = data["out_image"]
#pprint .pprint(self.chat_sessions)サーバ本体(FastAPIサーバとLLM関数の呼び出し)
説明は省略しますが、前半に各種の定義があり、LLMのロードも行います。中頃から下が、FastAPIのエンドポイントです。キーを用いてセッションデータの読み書きを行っています。このコードを動かすためにはfunction.pyが必要ですが、ここでは割愛します。Githubリポジトリにアップロードされているので必要ならば参照してください。
import argparse
import os
import random
import cv2
import numpy as np
from PIL import Image
import torch
import re
import torchvision.transforms as T
import torch.backends.cudnn as cudnn
from minigpt4.common.config import Config
from minigpt4.common.registry import registry
from minigpt4.conversation.conversation import Conversation, SeparatorStyle, Chat
# imports modules for registration
from minigpt4.datasets.builders import *
from minigpt4.models import *
from minigpt4.processors import *
from minigpt4.runners import *
from minigpt4.tasks import *
# ========== args
def parse_args():
parser = argparse.ArgumentParser(description="Demo")
parser.add_argument("--cfg-path", default='eval_configs/minigptv2_eval.yaml', help="path to configuration file.")
parser.add_argument("--gpu-id", type=int, default=0, help="specify the gpu to load the model.")
parser.add_argument("--options", nargs="+", help="override some settings in the used config, the key-value pair "
"in xxx=yyy format will be merged into config file (deprecate), "
"change to --cfg-options instead.", )
args = parser.parse_args()
return args
#========== INIT
random.seed(42)
np.random.seed(42)
torch.manual_seed(42)
cudnn.benchmark = False
cudnn.deterministic = True
print('Initializing Chat')
args = parse_args()
cfg = Config(args)
device = 'cuda:{}'.format(args.gpu_id)
model_config = cfg.model_cfg
model_config.device_8bit = args.gpu_id
model_cls = registry.get_model_class(model_config.arch)
model = model_cls.from_config(model_config).to(device)
vis_processor_cfg = cfg.datasets_cfg.cc_sbu_align.vis_processor.train
vis_processor = registry.get_processor_class(vis_processor_cfg.name).from_config(vis_processor_cfg)
model = model.eval()
CONV_VISION = Conversation(
system="",
roles=(r"<s>[INST] ", r" [/INST]"),
messages=[],
offset=2,
sep_style=SeparatorStyle.SINGLE,
sep="",
) #バウンディングboxで使用する色を定義
colors = [(255, 0, 0), (0, 255, 0), (0, 0, 255), (210, 210, 0), (255, 0, 255), (0, 255, 255), (114, 128, 250), (0, 165, 255),
(0, 128, 0), (144, 238, 144), (238, 238, 175), (255, 191, 0), (0, 128, 0), (226, 43, 138), (255, 0, 255), (0, 215, 255),]
color_map = {
f"{color_id}": f"#{hex(color[2])[2:].zfill(2)}{hex(color[1])[2:].zfill(2)}{hex(color[0])[2:].zfill(2)}" for
color_id, color in enumerate(colors )
}
used_colors = colors
chat = Chat(model, vis_processor, device=device)
# =================================== FastAPI ==============================
from fastapi import FastAPI, File, UploadFile, Form
from fastapi.responses import HTMLResponse,StreamingResponse,JSONResponse
from pydantic import BaseModel
from io import BytesIO
import json
import base64
import datetime
import string
import pprint
from function import mask2bbox, reverse_escape , escape_markdown, visualize_all_bbox_together
from class_chat_session import ChatSession
app = FastAPI()
cs = ChatSession()
# >>>>>>>>>>>>>>> chat リセット <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
@app.post("/reset/")
def reset( ):
print(">>>>> reset")
#chatキーの発行
now = datetime.datetime.now()
dtc= now.strftime('%Y%m%d%H%M%S') #秒単位のtsc作成と5桁のランダムな英文字によるkey
rand_name=''.join(random.choices(string.ascii_letters + string.digits, k=5))
key = dtc + rand_name
#key ="20231120144545NbrnT" # For TEST & Debug
cs.create_session(key)
print(" key=", key)
return {'message': "complete","key":key}
# >>>>>>>>>>>>>>> LLMへ イメージのアップロード <<<<<<<<<<<<<<<<<<<<<<<<<<
@app.post("/uploadfile/")
def upload_file(file: UploadFile = File(...), mask:UploadFile=File(...),key: str = Form(...)):
chatbot , chat_state , gr_img , img_list , upload_flag, replace_flag, out_image = cs.read_all(key)
print(">>>>> uploadfile")
print("key=",key)
if file:
image_data = file.file.read()
pil_img = Image.open(BytesIO(image_data)) # バイナリデータをPIL形式に変換
mask_img = mask.file.read()
pil_mask= Image.open(BytesIO(mask_img)) # バイナリデータをPIL形式に変換
else:
return {"message":"Error"}#"Error"
gr_img = {"image" :pil_img ,"mask":pil_mask}
cs.write(key,"gr_img",gr_img )
upload_flag = 1 # set the upload flag to true when receive a new image.
if img_list: # if there is an old image (and old conversation), set the replace flag to true to reset the conv later.
replace_flag = 1
try:
cs.write(key,"upload_flag",upload_flag )
cs.write(key,"replace_flag",replace_flag )
result="Uploadded"
except:
result="Key is not defined"
return {"message": result,"chatbot": chatbot}
# >>>>>>>>save_tmp_img
def save_tmp_img(visual_img):
file_name = "".join([str(random.randint(0, 9)) for _ in range(5)]) + ".jpg"
file_path = "/tmp/gradio" + file_name
visual_img.save(file_path)
return file_path
# >>>>>>>>>>>>>>> LLMへ ask <<<<<<<>>><<<<<<<>><<<<<<<<<<<<<<<<<<<<<<<<<
class Ask(BaseModel):
user_message: str
key:str=""
@app.post("/ask/")
def ask(gen_request:Ask):
print(">>>>> ask")
user_message = gen_request.user_message
key = gen_request.key
print("Key=",key)
print("user_message=",user_message)
chatbot , chat_state , gr_img , img_list , upload_flag, replace_flag, out_image = cs.read_all(key)
if isinstance(gr_img, dict): #gr_imgが辞書型か ?
gr_img, mask = gr_img['image'], gr_img['mask'] #辞書型ならimageとmaskを抜き出す
else:
mask = None #辞書型でないなら gr_imgはimageであり、maskはなし
# ユーザーが[identify]でバウンディングboxの位置を指定している時の処理
if '[identify]' in user_message:
integers = re.findall(r'-?\d+', user_message) #txtから数字列を探し 、integersにリスト作成。'-?\d+'--> - が0か1回現れる. \d+: 1以上の数字が1回以上
print("0 '[identify]'",integers )
if len(integers) != 4: # ユーザーが4箇所のbboxを指定していない場合
bbox = mask2bbox(mask)
user_message = user_message + bbox
print("1 '[identify]'",user_message)
if chat_state is None:
chat_state = CONV_VISION.copy()
if upload_flag:
if replace_flag:
chat_state = CONV_VISION.copy() # new image, reset everything
replace_flag = 0
chatbot = []
img_list = []
llm_message = chat.upload_img(gr_img, chat_state, img_list)
upload_flag = 0
chat.ask(user_message, chat_state)
chatbot = chatbot + [[user_message, None]]
if '[identify]' in user_message:
visual_img, _ = visualize_all_bbox_together(gr_img, user_message,colors)
if visual_img is not None:
file_path = save_tmp_img(visual_img)
chatbot = chatbot + [[(file_path,), None]]
print("2 '[identify]'",chatbot )
out_image=visual_img #バウンディングbox付きの画像をout_imageに保管
print("chatbot=",chatbot)
data_d={"chatbot":chatbot, "chat_state":chat_state,"gr_img":gr_img, "img_list": img_list ,"upload_flag":upload_flag,"replace_flag":replace_flag, "out_image": out_image}
cs.write_all(key,data_d )
result="Accepted"
return {'message':result, "chatbot":chatbot}
# >>>>>>>>>>>>>>> LLMからの結果をストリームで取得 <<<<<<<>>>>>>>>>>
class Streem(BaseModel):
temperature: float=0.6
key:str=""
@app.post("/get_stream/")
async def get_stream(gen_request :Streem):
print(">>>>> get_stream")
temperature = gen_request.temperature
key = gen_request.key
print("key=",key,"temperature=",temperature)
chatbot , chat_state , gr_img , img_list , upload_flag, replace_flag, out_image = cs.read_all(key)
generator_obj = stream_answer(chatbot, chat_state, img_list, temperature)
try:
for result in generator_obj:
output= result
print(".", end="")
except:
return {'message':"Generate error, try ask"}
print(output)
html_txt=reverse_escape(chatbot[-1][1])
html_txt = re.sub(r'\{.*?\}', '', html_txt).replace("<delim>","")
print("html_txt=", html_txt)
text=html_txt.replace("<p>","").replace("</p","").replace("{","").replace("}","")
data_d={"chatbot":chatbot, "chat_state":chat_state,"gr_img":gr_img, "img_list": img_list ,"upload_flag":upload_flag,"replace_flag":replace_flag, "out_image": out_image}
# 数値と特殊記号を除去する正規表現
clean_text = re.sub(r"[<>0-9]", "", text)
print("clean_text=",clean_text)
try:
print("key=",key)
cs.write_all(key,data_d )
result="Generated"
except:
print("*****Key is not defined")
result="Key is not defined"
return {'message':result, "chatbot":chatbot, "html_txt":html_txt,"text":text,"clean_text":clean_text }
# >>>>>>>>>>>>>>> LLMからの結果を視覚化 <<<<<<<>>>>>>>>>>>>>>>
class Viz(BaseModel):
key:str=""
@app.post("/visualize/")
def visualize(gen_request :Viz):
print(">>>>> visualize")
key = gen_request.key
chatbot , chat_state , gr_img , img_list , upload_flag, replace_flag, out_image = cs.read_all(key)
if isinstance(gr_img, dict): # gr_imgはも元の画像, maskはイメージと同じサイズの黒い画像, 画像はPLIオブジェクト
gr_img, mask = gr_img['image'], gr_img['mask']
try:
unescaped = reverse_escape(chatbot[-1][1])
except:
return {'message':"visualize error ,try ask"}
print("v1-gr_img=",gr_img)
visual_img, generation_color = visualize_all_bbox_together(gr_img, unescaped,colors)
print("0-unescaped-",unescaped)
if '[identify]' in chatbot [0][0]:
visual_img=out_image
print("generation_color =",generation_color )
if visual_img is not None:
if len(generation_color):
chatbot[-1][1] = generation_color
chatbot = chatbot + [[None, "file_path"]]#DUMMY
try:
html_colored_list=chatbot[-2]
except:
html_colored_list=""
else:
visual_img = gr_img
html_colored_list=["None",unescaped]
print("html_colored_list",html_colored_list)
#jesonで返信するためにbase64にエンコード
try:
img_byte_array = BytesIO()
visual_img.save(img_byte_array, format="PNG")
img_base64 = base64.b64encode(img_byte_array.getvalue()).decode()
except:
img_base64=""
data_d={"chatbot":chatbot, "chat_state":chat_state,"gr_img":gr_img, "img_list": img_list ,"upload_flag":upload_flag,"replace_flag":replace_flag, "out_image": out_image}
try:
cs.write_all(key,data_d )
result="Created"
except:
result="Key is not defined"
return {'message':result, "chatbot": chatbot ,"html_colored_list":html_colored_list,"visual_img":img_base64}
#LLMからのストリームデータを取得
def stream_answer(chatbot, chat_state, img_list, temperature):
if len(img_list) > 0:
if not isinstance(img_list[0], torch.Tensor):
chat.encode_img(img_list)
streamer = chat.stream_answer(conv=chat_state,
img_list=img_list,
temperature=temperature,
max_new_tokens=500,
max_length=2000)
output = ''
for new_output in streamer:
escapped = escape_markdown(new_output)
output += escapped
chatbot[-1][1] = output
yield chatbot, chat_state
chat_state.messages[-1][1] = '</s>'
return chatbot, chat_state
if __name__ == "__main__":
import uvicorn
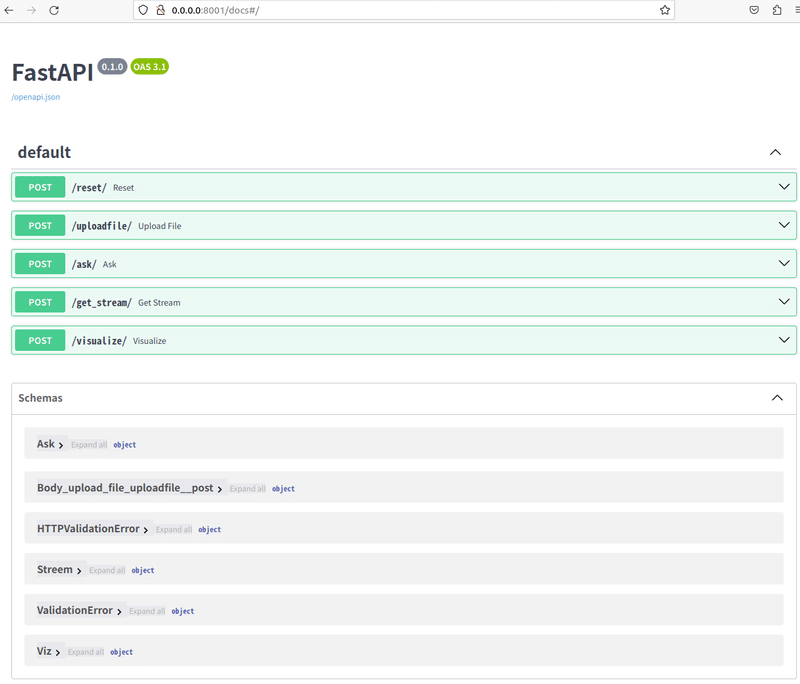
uvicorn.run(app, host="0.0.0.0", port=8001)起動後 http://0.0.0.0:8001/docs でFastAPIのエンドポイントサービスを表示出来ます。
6,APIのテスト
サーバコードを起動します。
以下のGitHubをクローンし、オリジナルのREADME.mdに沿ってMiniGPT-v2が動く環境を作成します。以下の記事で実際の作業を解説しています。ここではオリジナルリポジトリで作業を解説していますが、オリジナルをフォークし今回のコードを追加したリポジトリを公開しているので、そちらをダウンロードして作業をしても同じです。記事の最後にリンクがります。
リポジトリのAPIフォルダの中のAPI_multi_settionフォルダ内にサーバがありclientフォルダにクライアント側の各種テストプログラムとクライアントAPI及びGUIアプリがあります。これらをmainへコピーしてください。
サーバの起動
python minigpt_v2_api_r2.py
===================================BUG REPORT===================================
Welcome to bitsandbytes. For bug reports, please submit your error trace to: https://github.com/TimDettmers/bitsandbytes/issues
================================================================================
Initializing Chat
Loading checkpoint shards: 100%|████████████████████████████████| 2/2 [00:02<00:00, 1.22s/it]
trainable params: 33554432 || all params: 6771970048 || trainable%: 0.49548996469513035
Position interpolate from 16x16 to 32x32
Load Minigpt-4-LLM Checkpoint: ./checkpoint/minigptv2_checkpoint.pth
INFO: Started server process [16956]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8001 (Press CTRL+C to quit)以下は新たなターミナルを開いて作業をします
リセット client_reset_s.py
セッション開始のリクエストとKEYの取得、及び変数の初期化
コンソールを開きクローンしたリポジトリディレクトリに移動して作業をします。
import requests
from PIL import Image
from io import BytesIO
# FastAPIエンドポイントのURL
url = 'http://0.0.0.0:8001/reset/' # FastAPIサーバーのURLに合わせて変更してください
# POSTリクエストを送信
response = requests.post(url)
# レスポンスを表示
if response.status_code == 200:
result = response.json()
print("サーバーからの応答message:", result.get("message"))
print("サーバーからの応答key:", result.get("key"))
else:
print("リクエストが失敗しました。ステータスコード:", response.status_code)生成されたKEYが出力されるのでコピーしておきます。
アップロード client_upload_s.py
画像をアップロードします。コピ−しておいたKEYをペーストして起動ます。
import requests
from PIL import Image
from io import BytesIO
# 送信するPIL形式の画像データ
image_file_path = '00016-331097358.png'
# FastAPIエンドポイントのURL
url = 'http://0.0.0.0:8001/uploadfile/' # FastAPIサーバーのURLに合わせて変更してください #Maskを作成 。IDENTIFYタスクで使う。その他の場合はイメージと同じ大きさのファイルを作成
pil_image=Image.open(image_file_path )
width, height = pil_image.size
mask = Image.new('L', (width, height), 0)
# ファイルデータをバイナリ形式に変換
img_byte_arr_m = BytesIO()
mask.save(img_byte_arr_m, format='PNG')
mask_img = img_byte_arr_m.getvalue()
# ファイルデータをバイナリ形式で読み込む
file_data = open(image_file_path, "rb").read()
# ファイルをアップロードするためのリクエストを作成
files = {
"file": ("img.png", BytesIO(file_data), "image/png"),
"mask": ("mask.png", BytesIO(mask_img), "image/png"),
"key": (None, "20231124233503IqK3y")
}
# POSTリクエストを送信
response = requests.post(url, files=files)
# レスポンスを表示
if response.status_code == 200:
result = response.json()
print("サーバーからの応答message:", result.get("message"))
print("サーバーからの応答chatbot:", result.get("chatbot"))
else:
print("リクエストが失敗しました。ステータスコード:", response.status_code)Ask client_ask_s.py
タスクやプロンプトをリクエストします。コピ−しておいたKEYをペーストして起動ます。いくつかタスクを選べるようにしています。適当にコメントアウトを変更して試せます。一旦画像をアップロードするとAskからのスタートでokです。
import requests
from PIL import Image
from io import BytesIO
import json
# 送信するデータを準備
data = {
"user_message": "[grounding] describe this image in detail",
"key": "20231124233503IqK3y",
} #data ={
# "user_message": "[refer] color of clock tower",
# "key": "20231120144545NbrnT"
# } #data ={
# "user_message": "[detection] clock tower",
# "key": "20231120144545NbrnT",
# } #data ={
# "user_message": "[identify] color of clock tower",
# "key": "20231120144545NbrnT"
# } #data ={
# "user_message": "[vqa]Please explaine colore of a clock tower",
# "key": "20231120144545NbrnT",
# }
# FastAPIエンドポイントのURL
url = 'http://0.0.0.0:8001/ask/' # FastAPIサーバーのURLに合わせて変更してください
# POSTリクエストを送信
response = requests.post(url, json=data)
# レスポンスを表示 return {"message": "ask_completed ","chatbot":chatbot}
if response.status_code == 200:
result = response.json()
print("サーバーからの応答message:", result.get("message"))
print("サーバーからの応答chatbot:", result.get("chatbot"))
else:
print("リクエストが失敗しました。ステータスコード:", response.status_code)Ans client_stream_ans_s.py
推論を実行します。コピ−しておいたKEYをペーストして起動ます。LLMからはStreamingで出力されますが、API経由の過程で一括文字列に変換しています。筆者の力不足です。
import requests
from PIL import Image
from io import BytesIO
import json
# 送信するデータを準備
data = {
"temperature": 0.6,
"key": "20231124233503IqK3y",
}
# FastAPIエンドポイントのURL
url = 'http://0.0.0.0:8001/get_stream/' # FastAPIサーバーのURLに合わせて変更してください
# POSTリクエストを送信
response = requests.post(url, json=data)
# レスポンスを表示
if response.status_code == 200:
result = response.json()
print("サーバーからの応答message:", result.get("message"))
print("サーバーからの応答chatbot:", result.get("chatbot"))
print("サーバーからの応答html_txt:", result.get("html_txt"))
print("サーバーからの応答text:", result.get("text"))
print("サーバーからの応答clean_text:", result.get("clean_text"))
else:
print("リクエストが失敗しました。ステータスコード:", response.status_code)
Visualization client_viz_s.py
コピ−しておいたKEYをペーストして起動ます。端末には生成された文字、ラベルなどが出力され、[grounding] タスクでは、バウンディングboxとラベルが記入された画像が表示されます。以下の様な画像です。(大きなピンクの文字はありません) これでサーバAPIの動作確認は出来ました。このテストプログラムを参考に皆さんのプログラムへ組み込んでも大丈夫ですが、煩雑なんのでAPIクラスを準備しています。
7,クリアント側APIクラスの実装
クライアント側のアプリで容易にAPIを呼び出し、Visualも取得できるよう関数及び関数をクラス化をしたAPIクラスを準備しました。どちらでも動きますがclaaの方が便利です。
client_api_v2.py 関数で記述
import requests
from PIL import Image
from io import BytesIO
import json
import base64
def reset(url ):
url = url+"/reset/" # FastAPIエンドポイントのURL
response = requests.post(url) # レスポンス
if response.status_code == 200:
result = response.json()
return response.status_code, result.get("message") , result.get("key")
else:
return response.status_code,"None","None"
def upload(url , key, pil_image="",mask=""): # image_file_path 送信するPIL形式の画像データ
print("api_key=",key)
#バイナリストリームに画像を保存
img_byte_arr = BytesIO()
pil_image.save(img_byte_arr, format='PNG')
img_data = img_byte_arr.getvalue()
if mask=="":
width, height = pil_image.size
mask = Image.new('L', (width, height), 0)
else:
img_byte_arr_m= BytesIO()
mask.save(img_byte_arr_m, format='PNG')
mask_img = img_byte_arr_m.getvalue()
# ファイルをアップロードするためのリクエストを作成
files = {
"file": ("img.png", BytesIO(img_data), "image/png"),
"mask": ("mask.png", BytesIO(mask_img), "image/png"),
"key": (None, key)
}
url =url+"/uploadfile/" # FastAPIエンドポイントのURL
response = requests.post(url, files=files) # レスポンス
if response.status_code == 200:
result = response.json()
return response.status_code, result.get("message") , result.get("chatbot")
else:
return response.status_code,"None","None"
def ask(url , key, task , user_message):
data = {
"user_message": task + user_message,
"key": key,
}
url =url+"/ask/" # FastAPIエンドポイントのURL
response = requests.post(url, json=data) # レスポンス
if response.status_code == 200:
result = response.json()
return response.status_code, result.get("message"), result.get("chatbot")
else:
return response.status_code,"None","None"
def generate(url , key, temperature=0.6):
data = {
"temperature": temperature,
"key": key,
}
url =url+"/get_stream/" # FastAPIエンドポイントのURL
response = requests.post(url, json=data) # レスポンス
if response.status_code == 200:
result = response.json()
return response.status_code, result.get("message"), result.get("clean_text"), result.get("text"), result.get("html_txt") , result.get("chatbot")
else:
return response.status_code,"None","None","None","None","None"
def visualize(url , key):
data = {
"key":key,
}
url =url+"/visualize/" # FastAPIエンドポイントのURL
response = requests.post(url, json=data) # レスポンス
if response.status_code == 200:
result = response.json()
if result.get("message")=="Created":
decoded_image_data = base64.b64decode(result.get("visual_img"))
pil_image = Image.open(BytesIO(decoded_image_data ))
chatbot=result.get("chatbot")
return response.status_code, result.get("message"), result.get("html_colored_list"), pil_image , chatbot
else: #通信は成功したが上手く生成出来なかった時
print(result.get("message"))
return response.status_code, result.get("message"),"None","None","None"
else:
return response.status_code, "None","None","None","None"
APIクラスを準備しました。
Class化 こちらの方が便利です
class_client_api.py
import requests
from PIL import Image
from io import BytesIO
import base64
class ImageAPI:
def __init__(self, url):
self.url = url
def reset(self):
response = requests.post(self.url + "/reset/") # レスポンス
if response.status_code == 200:
result = response.json()
return response.status_code, result.get("message"), result.get("key")
else:
return response.status_code, "None", "None"
def upload(self, key, pil_image, mask=None): # image_file_path 送信するPIL形式の画像データ
print("api_key=", key)
#バイナリストリームに画像を保存
img_byte_arr = BytesIO()
pil_image.save(img_byte_arr, format='PNG')
img_data = img_byte_arr.getvalue()
if mask is None:
width, height = pil_image.size
mask = Image.new('L', (width, height), 0)
img_byte_arr_m = BytesIO()
mask.save(img_byte_arr_m, format='PNG')
mask_img = img_byte_arr_m.getvalue()
# ファイルをアップロードするためのリクエストを作成
files = {
"file": ("img.png", BytesIO(img_data), "image/png"),
"mask": ("mask.png", BytesIO(mask_img), "image/png"),
"key": (None, key)
}
response = requests.post(self.url + "/uploadfile/", files=files) # レスポンス
if response.status_code == 200:
result = response.json()
return response.status_code, result.get("message"), result.get("chatbot")
else:
return response.status_code, "None", "None"
def ask(self, key, task, user_message):
data = {
"user_message": task + user_message,
"key": key
}
response = requests.post(self.url + "/ask/", json=data) # レスポンス
if response.status_code == 200:
result = response.json()
return response.status_code, result.get("message"), result.get("chatbot")
else:
return response.status_code, "None", "None"
def generate(self, key, temperature=0.6):
print(" temperature=", temperature)
data = {
"temperature": temperature,
"key": key
}
response = requests.post(self.url + "/get_stream/", json=data) # レスポンス
if response.status_code == 200:
result = response.json()
return response.status_code, result.get("message"), result.get("clean_text"), result.get("text"), result.get("html_txt"), result.get("chatbot")
else:
return response.status_code, "None", "None", "None", "None", "None"
def visualize(self, key):
data = {
"key": key
}
response = requests.post(self.url + "/visualize/", json=data) # レスポンス
if response.status_code == 200:
result = response.json()
if result.get("message") == "Created":
decoded_image_data = base64.b64decode(result.get("visual_img"))
pil_image = Image.open(BytesIO(decoded_image_data))
chatbot = result.get("chatbot")
return response.status_code, result.get("message"), result.get("html_colored_list"), pil_image, chatbot
#通信は成功したが上手く生成出来なかった時
else:
print(result.get("message"))
return response.status_code, result.get("message"), "None", "None", "None"
else:
return response.status_code, "None", "None", "None", "None"from class_client_api import ImageAPI
api_client = ImageAPI(url) #ImageAPIのインスタンス変数として定義
のよにアプリ側で準備してください
以下メソッドと変数定義です。
使用例
api_client = ImageAPI(url) URLインスタンスと初期化
responce, message , key = api_client.reset()
responce, message, chatbot = api_client.upload(key, pil_image , mask)
responce, message , chatbot = api_client.ask(key, task , user_message)
responce, message, clean_text, text, html_txt , chatbot = api_client.generate(key, temperature=0.6)
responce, message , html_colored_list , pil_image , chatbot = api_client.visualize(key)
*付きの引数は必須項目になります。
メソッド reset
引数 key*
pil_image* レファレンスイメージ。PIL形式。イメージを元に推論
mask identyifyタスク時のエリア指定。PIL形式。
出力 message 結果のメッセージ
chatbot チャット記録
メソッド ask
引数 key*
task* 実行させたいタスク
[grounding]、[refer] 、[detection] 、[identify]、[vqa]
user_message* ユーザーのプロンプト
出力 message 結果のメッセージ
chatbot チャット記録
メソッド generate
引数 key*
temperature=0.6
出力 message 結果のメッセージ
clean_text テキスト出力(記号類のない純粋なテキスト) text 推論出力
html_txt html化をしたテキスト(色情報付き)
chatbot チャット記録
メソッド visualize
引数 key*
出力 message 結果のメッセージ
html_colored_list html化をしたテキスト(色情報付き)のリスト pil_image PLI形式の出力イメージ
chatbot チャット記録
8,gradioによるクライアント側アプリケーションの例
オリジナルDemoとほとんど同じGUIを準備しました。ただし、API経由ですから大幅に改良されています。
違い−: LLMからの出力がストリーミングではない
image Uploadボタンのクリックが必須
違い+ :検出画像の位置情報表示機能
起動直後の画像 ほぼオリジナルと同じです。

9,様々な利用例
オリジナルが準備してくれているサンプルの左上を実行します。
右側色のついた文字列下が追加した検出物の位置情報です。この情報を基に[avg] で色々な質問をすることが出来ます。
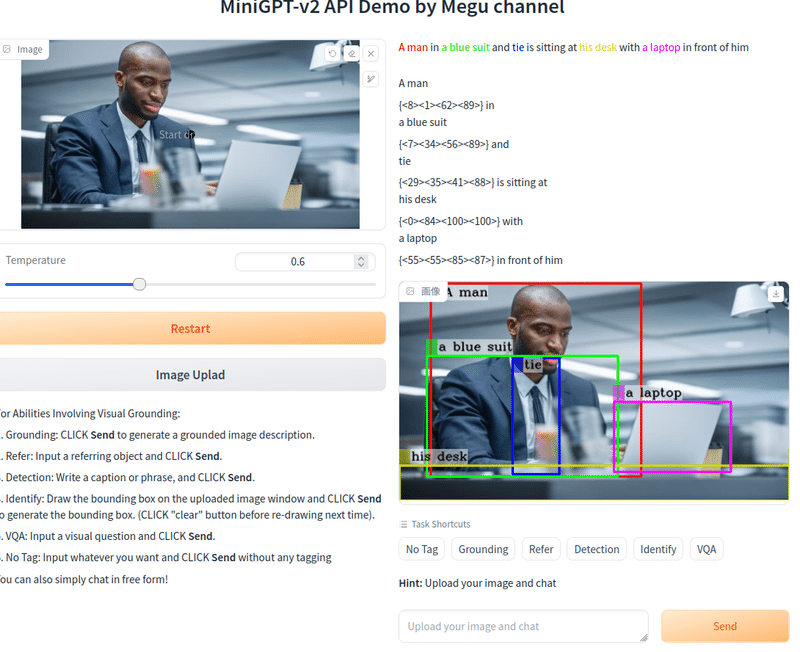
右側上のサンプルです。
[vqa] where should I hide in this room when playing hide and seekがプロンプトです。
回答は右上 behind couch になっています。

[identify] を試します。
[identify] what is this がプロンプトで、オリジナル画像に認識させたいエリアをスケッチ機能で書き込みます。
ラフに囲んでアップロードし、Sendボタンをクリックすると、バウンディングboxをが現れて、the shelves(=本棚)と回答してくれます。
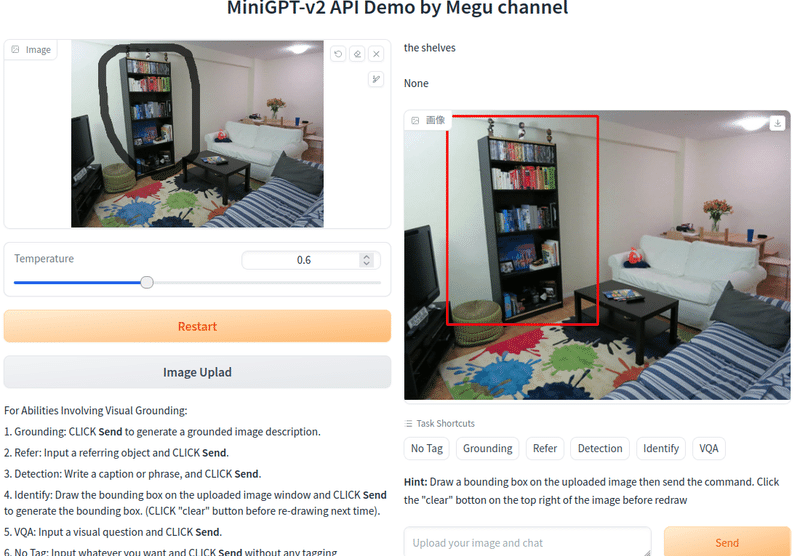
そのままで[vqa] How many books are thereと意地悪な質問をSendすると
16と答えてきました。多分合ってないですね。本が乱雑すぎます。
それではサンプルから離れて現実的?な画像を試してみます。
以下のニケちゃんさんの記事面白いので、読んでみてください。今回はここからニケちゃんの画像をお借りしました。
キャラクタ可愛いですね。
[grounding] describe this image in detail がプロンプト
なんか、たくさん検出されたようです。
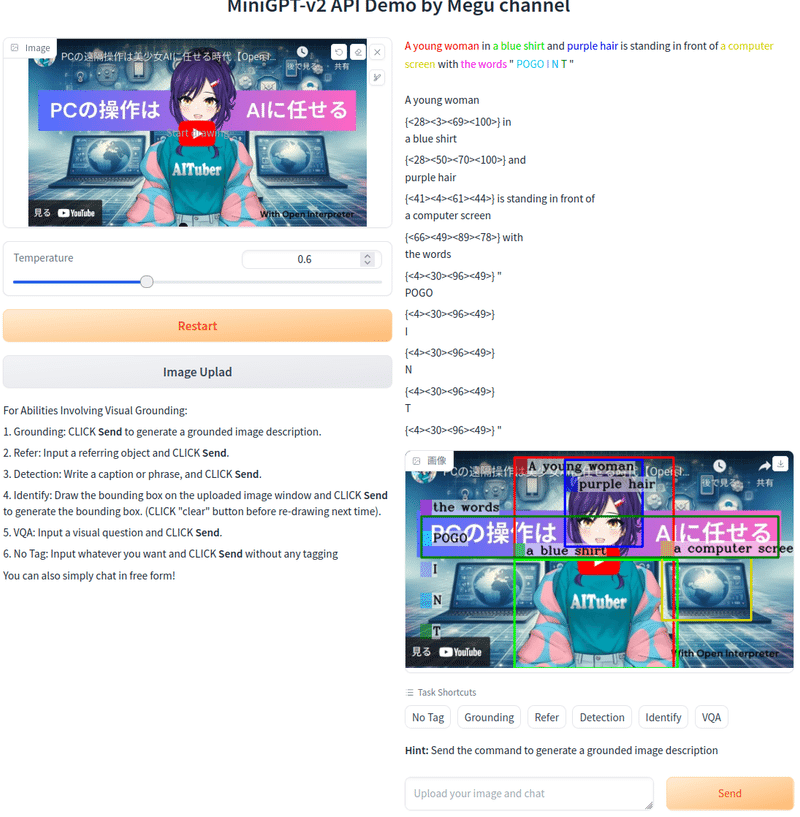
エリアを指定して訪ねてみます
[identify]what is thisがプロンプト
Anime girlと回答がでました。

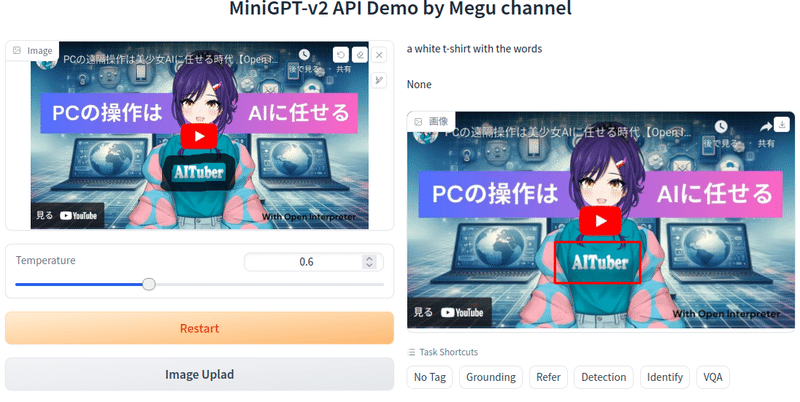
文字の認識
胸の文字を認識させようとしてエリア指定をしたんですが、結果は
a white t-shirt with the words だそうです。文字を聞きましたがjapaneseと帰って来ました。AITuberは英語には語彙が無いんでしょうね。
Please write a poem about the imageでポエムを書いてくださいとプロンプトにいれると、以下のような文章を書いてくれました。この例ではタスクを指定せず自由な文章の入力で推論させています。

A young woman in a pink sweater and blue shirt stands in front of a computer, smiling at the camera. She wears a red headband, and her hair is styled in a bun. The image is surrounded by numerous icons, including two laptops, a cell phone, a TV, and a mouse. In the background, there are two more people visible, one with a laptop and the other holding a cell phone.
和訳
ピンクのセーターと青いシャツを着た若い女性がコンピューターの前に立ち、カメラに向かって微笑んでいます。彼女は赤いヘッドバンドを着けており、髪はお団子にまとめられています。この画像は、2 台のラップトップ、携帯電話、テレビ、マウスなど、多数のアイコンで囲まれています。背景にはさらに 2 人の人物が見えます。1 人はラップトップを持ち、もう 1 人は携帯電話を持っています。
[ditection]laptopを試しました。
なぜ1個だけ?と思いますが、検出は出来ています。位置情報が表示されてないのは私のプログラムのバクですかね。

10、Githubリポジトリ
今回は多数のコードがあることから全てのコード及び、シングルセション、更にプログラムに直接apiを記述するEMBEDDEDのコード(こちらは動作未確認なのでエラーになるかも)を追加したリポジトリをオリジナルリポジトリをフォークして作成し公開しています。ぜひこの高機能なマルチモーダルLLMをみなさんも試してください。
まとめ
今回は開発にずいぶん苦労しました。gradioと推論部のコードが密接に絡んでいるのと、マルチモーダルで機能が上がり、位置情報やタスク機能など旧バージョンに対して大変複雑になっています。一方でローカルLLMでここまでできるとは驚きです。日本語が使えないのは残念ですが、高速の翻訳はCtransrateなどを使えばローカルLLMで高速に実行できるので大きな障害では無いと考えています。これでAIキャラに目をもたせることができるんじゃないかと思います。コードにはまだまだバグがあると思いますので、改良をしながらご利用いただくと嬉しいいです。