
AI勉強会 ~AIとは~

AIとは
AIの定義
「AI」は、1956年にアメリカのダートマス大学で開かれた研究会議にて、
人工知能研究者であるジョン・マッカーシーが初めて使った言葉です。
この会議では、人と同じように考える知的なコンピュータの事を「人工知能(Artificial Intelligence)」と呼びました。
この定義に従うならば、未だにAIは実現できていない事になります。
「人工知能とは何か」
この定義は、未だに定まっていません。
研究者たちの中でも解釈がさまざまだからです。
人工的につくられた人間のような知能、ないしはそれをつくる技術
人間の頭脳活動を極限までシミュレートするシステムである
人工的につくられた、知能を持つ実態。あるいはそれをつくろうとすることによって知能自体を研究する分野である
知能の定義が明確ではないので、人工知能を明確に定義できない
人間のもつ知性や知能の定義が明確になっていない中で、「人間と同等の知的な処理能力」を定義することはできません。
「人間と同等の知的な処理能力」を実現するために、何が必要か
・右脳と左脳の機能?
・感情や心?
・価値観?
・パーソナリティー?
研究者の数だけ解釈が存在します。
同じシステムに対して、
「これは人工知能である」と言う人、
「それは人工知能とはいえない」と言う人がいるという事です。
人間と機械(AI)の関係性
AI技術が発展すると共に、「人間」もアップデートが必要になってきました。法の整備やルールを見直すこと、
リテラシーを身に付けること、そもそもの人間の在り方についても再考する必要がありそうです。
人間とAIの関係性について書かれた資料・本を紹介します。
国立研究開発法人 科学技術振興機構(JST)
「人と情報のエコシステム」研究開発領域 小冊子vol.4
人間観と社会をアップデートする
https://www.jst.go.jp/ristex/hite/topics/img/hite_book-vol4.pdf
「人と情報のエコシステム(HITE)」領域は、 「なじみ」をキーワードとして取り組みを進めています。 人と機械を主従や対立的な関係ではなく、共生し、協調する関係として捉え、 ともに進化させたいというのが、領域名に込められた思いです。
これは哲学的な世界観の問題でもありますが、同時に、 どんな意思決定をどれくらい機械に任せて良いのか、 という現実的で差し迫った課題に答えを出す作業でもあります。
領域を始めたころはしばらく先の問題と考えていた問題が、 医療などの分野において急速に技術適用が進むことで、 差し迫った課題となってきました。
なじみの視点を持つと、西洋では「AIが雇用を奪う」といった視点で語られがちな雇用問題が、 機械の存在がいかに地域社会の分業関係や仕事の質を変えていくか、 といった視点で語ることができるようになります。 また、AIを人間とともに帰納と演繹を繰り返しながら 探索を行う存在としてとらえることも可能となります。
さらには機械に(合理性だけでなく)徳といった判断基準で 行動してもらうというような発想が可能となってきます。
なじみの考え方を追いかけていくと、「決定はあくまで人間が」とか「思い切って機械に委ねる」 といった二項対立ではなく、人間と機械が一体となった新しい主体が、 ともに社会を構成していくという考え方をとることができるようになります。
そのような世界は漫然と実現するわけではないのでしょう。
そのような状態が実現するように、機械の開発や利用ルールを決めたり、 人間側のリテラシーを高めていったりする努力を続けたいところです。
人間と機械について、人類学者の視点で書かれた本です。
2018年頃に初めて読んだ本ですが、とても気に入っています。
カニバリズム=他者の視点から自己を捉え、自己を変化させていく営為
システムである「AI」に対して、人間は比較する主体でありながら、自らを比較の対象にもしている。
このような比較の在り方を「可塑的な比較」と呼ぶ。
可塑性には、
「特定の姿かたちを与える能力」と
「異なる姿かたちを受け取る能力」がある。
私たちは自律的なテクノロジーに操られているわけではなく、自律的な私たちがテクノロジーを操っているわけでもない。
むしろ、私たちはテクノロジーへと生成している。
分類① 汎用型AIと特化型AI
汎用型AI
人間の様に自ら考え、行動するAI
特定のタスクに限定されない。
特化型AI
人間の行動を模倣するAI
特定のタスクに限定されている。
AIというと汎用型のイメージが強いですが、現在世に出ているものは、
ほぼ全て特化型といえます。
分類② AIの分類(4つのレベル)
AIと呼ばれるものは、4つのレベルに分類されています。

レベル1:シンプルな制御プログラム
単純な制御プログラムが組み込まれたもの。
決められたルールに従い、すべての振る舞いがあらかじめ決められているもの。
例:スマート家電(温度調整をするエアコン、水量調節を行う洗濯機など)
レベル2:古典的な人工知能
単純な制御プログラムを複数組み合わせたもの。
探索・推論、知識データを利用することで、複雑な振る舞いが可能になったもの。
例:お掃除ロボット、チャットボット
レベル3:機械学習を取り入れた人工知能
多くのサンプルデータを元に、ルールや知識を自ら学習する「機械学習」を取り入れたもの。
ビッグデータ時代を迎えて、ますます進化している。
古典的な人工知能の属している製品も、こちらの方式に移行されているものが数多くある。
例:将棋ソフト、IBM開発の「ワトソン」
レベル4:ディープラーニングを取り入れた人工知能
「ディープラーニング」という技術を取り入れたもの。
コンピュータが自ら、データ内の「特徴量」を見つけて学習をし、
人間と同じような判断を行うもの。
画像認識・音声認識・自動翻訳など、従来のコンピュータでは難しいとされていた分野で急速に応用が進んでいる。
現在、最も注目されている技術です。
例:自動運転
AI(人工知能)研究の歴史
AIの研究は、ブームと冬の時代を繰り返してきました。
第1次AIブーム:推論・探索の時代
1950年代後半~1960年代
コンピュータによる「推論」と「探索」の研究が進んで、特定の問題に対しての解が出せるようになったことから、ブームが到来しました。
迷路やパズル、数学の定理の証明などの限定された状況で設定された問題である「トイ・プロブレム」は解けますが、
現実で直面するような複雑な問題は解けないという事がわかり、1970年代頃に冬の時代を迎えました。
第2次AIブーム:知識の時代
1980年代
第2次ブームでは、コンピュータに「知識」を入れるというアプローチが流行しました。
大量の専門知識をデータベースに格納した「エキスパートシステム」というシステムが作られました。
しかし、知識を蓄積・管理することの大変さから、1995年頃から再度冬の時代に突入しました。
第3次AIブーム:機械学習・特徴表現学習の時代
2010年~
「ビッグデータ」と呼ばれる大量のデータを用いることで、
AIが自ら知識を獲得するという「機械学習」の実用化が始まりました。
また、特徴量をAIが自ら習得する「ディープラーニング」が登場しました。
AIブームを後押ししているもの
・IoTが発達して、データ取得が容易かつ膨大になっている。
・GPUの進展によって、膨大な量の計算が可能となっている。
・誰でも使える、無料の機械学習フレームワークが登場した。
ブームの火付け役
・2012年、画像認識の精度を競い合う競技会であるILSVRC(ImageNet Large Scale Visual Recognition Challenge)で、ディープラーニングを用いたチームが圧倒的な勝利を収めた。
・ディープラーニングを用いた人工知能であるAlphaGoが、人間の碁のチャンピオンに勝利した。
・シンギュラリティに対して言及する著名人が増え、懸念が広まった。
AI分野の課題
AI分野の研究にはまだまだ多くの課題があります。
そのいくつかを取り上げます。
シンギュラリティ

技術的特異点とも言います。
AIが人類の知能を超え、自分自身よりも賢いAIを作るようになると、その瞬間から無限に知能の高い存在を作り出し、想像を超えた知性が誕生すると言われています。
未来学者であるレイ・カーツワイル氏は、AIが人間よりも賢くなるのは2029年頃、シンギュラリティを迎えるのは2045年頃と予測しています。
収穫加速の法則
技術進歩においてその性能が直線的ではなく、指数関数的に向上するという法則のことです。
技術的な進歩が一度起きると、その技術が次の進歩までの期間を短縮させるため、ますます技術進歩が加速するという概念です。
専門家の見解
この超越的な知性を持ったAIが生まれる事に対し、数多くの著名人が言及しています。
宇宙物理学者のスティーブン・ホーキング氏
「完全な人工知能を開発できたら、それは人類の終焉を意味するかもしれない」
テスラCEOのイーロン・マスク氏
「人工知能にはかなり慎重に取り組む必要がある。結果的に悪魔を呼び出していることになるからだ。ペンタグラムと聖水を手にした少年が悪魔に立ち向かう話を皆さんもご存知だろう。少年は必ず悪魔を支配できると思っているが、結局できはしないのだ」
元人工知能研究者のヒューゴ・デ・ガリス氏
「今世紀後半に人工知能は、人類の一兆倍の一兆倍の知能を持つ可能性があります。さらに人工知性の開発に成功すれば、人類の一兆倍の一兆倍の一兆倍の能力を持つことになります」
チューリングテスト
人工知能ができたかどうかを判定する方法の一つとして、イギリスの数学者アラン・チューリング氏が提唱したチューリングテストというものがあります。
別の場所にいる人間がコンピュータと会話をして、
相手がコンピュータであると見抜けなかったら、そのコンピュータには知性があるとしたものです。
知能の定義が難しいことから、外から観察できる行動で判断せざるを得ないといった立場でテストする方法です。
1991年以降、チューリングテストに合格する会話ソフトウェアのコンテスト(ローブナーコンテスト)も毎年開催されていますが、
まだチューリングテストをパスできるレベルには達していません。
強いAI、弱いAI
アメリカの哲学者であるジョン・サール氏が、1980年に発表した
「Minds, Brains, and Programs(脳、心、プログラム)」という論文の中で提示した区分です。
強いAI
強いAIは、人間の知能と同等またはそれ以上の知能を持つ人工知能のことを指します。強いAIは、複雑な問題を解決したり、創造的な仕事を行ったり、自己学習や自己改善を行うことができます。
つまり、強いAIは、自己意識や感情などの人間的な特徴を持っていると考えられています。
ただし、現在の技術では、強いAIを開発するにはまだ多くの課題が残っており、実現には至っていません。また、強いAIの開発がもたらす社会的・倫理的な問題についても、今後の議論が必要とされています。
弱いAI
弱いAIは、ある特定のタスクに特化した人工知能のことを指します。
特定のタスクにおいて高いパフォーマンスを発揮することができますが、その他のタスクについては一般的には対応できません。
弱いAIは、音声認識、画像認識、自然言語処理、ゲームなどの分野で広く利用されています。
弱いAIは、人間の知能とは異なり、あくまでも特定のタスクにおいて高いパフォーマンスを発揮することが目的であり、自己学習や自己改善の能力は限られています。
そのため、弱いAIは、狭い範囲での活躍が期待されています。
ジョン・サール氏は、「中国語の部屋」という思考実験を挙げ、
人の思考を表面的に模倣する「弱いAI」は実現可能だが、
意識を持ち意味を理解する「強いAI」は実現不可能だと主張しました。
中国語の部屋
ある部屋に、英語しか分からない人が閉じ込められました。
その部屋には、中国語の質問に答えることのできる完璧なマニュアルが置かれています。
これを使えば、中国語での受け答えができるようになっています。
部屋の外の人が中の人に質問を投げ入れ、マニュアルの指示通りに置き換えた回答を返します。
これを繰り返すと、外の人は、部屋の中の人が中国語を理解していると判断します。でも実際には英語しか理解できていません。
ジョン・サール氏はこの思考実験を通して、
コンピュータは記号操作を行っているだけで、心にとっての本質的な意味論を欠いていると主張しました。
フレーム問題
フレーム問題(frame problem)は、人工知能が現実世界の状況に適切に対応するために必要な情報を効率的に扱うことができない問題です。
1969年にジョン・マッカーシー氏とパトリック・ヘイズ氏が提唱しました。
このフレーム問題は、初期の人工知能研究で広く議論されました。
未だに解決されておらず、人工知能研究最大の難問と言われています。
フレーム問題とは、「今しようとしていることに関係のある事柄だけを選び出すことが、実は非常に難しい」という問題です。
洞窟の中に台車があります。
その上にロボットの動力源となるバッテリーと、時限爆弾が置かれています。
ロボットが、バッテリーを持ってくるように命令されました。
ロボット1号は、台車ごと持ち出したため、洞窟から出た後に爆発してしまいました。
ロボット2号はロボット1号の失敗を踏まえて、台車を目の前にして、持ち出す際のあらゆる可能性を考えました。考えている間に時間切れになり、爆発してしまいました。
ロボット3号はロボット2号の失敗を踏まえて、関係があることとないことを仕分け始めました。
仕分け作業に没頭し過ぎて、洞窟に入る前にバッテリーが切れてしまいました。
このように、現実世界においては、情報の取捨選択が必要であり、どの情報が必要でどの情報が不要かを正確に判断することが重要です。フレーム問題は、このような現実世界の複雑さに対処するために、効率的かつ正確な情報処理技術が必要であることを示しています。
シンボルグラウンディング問題
シンボルグラウンディング問題(symbol grounding problem)は、人工知能における意味の問題の一つで、人工知能が自然言語や記号などの抽象的な表現を適切に理解するために必要な、物理的な世界との接続をどのように確立するかという問題です。
1990年に認知科学者のスティーブン・ハルナッド氏により議論されました。
フレーム問題と同様に、人工知能の難問とされています。
言語や記号は、一般的に、人々が物理的な世界で経験する事柄を抽象化し表現する手段として用いられます。しかし、人工知能にとっては、言語や記号が持つ意味を適切に理解するためには、それが表現する物理的な世界との接続を確立する必要があります。
人間の場合、シマ(縞・Stripe)の意味も、ウマ(馬・Horse)の意味も分かるため、シマウマ(Zebra)を初めて見た時に、「縞のある馬…シマウマだ」とすぐに認識することができます。
しかしコンピュータにとっては「シマウマ」という文字はただの記号の羅列に過ぎないため、「縞のある馬」と結びつけることができません。
「シマウマ」という記号に対して、それが意味するものが結びついていない=グラウンディングしていない
これをシンボルグラウンディング問題と呼びます。
AI分野の最新動向
GPT(ChatGPT)
OpenAI社によって開発された大規模言語モデル(LLM:Large Language Model)の一種です。
GPTとは、「Generative Pre-trained Transformer」の略で、Transformerという深層学習のアーキテクチャをベースに、大量のテキストデータを学習して自然言語処理のタスクを実行するモデルのことです。
ChatGPTはGPT-3.5アーキテクチャを採用しており、(ChatGPT本人に聞いたところ)約1.3兆のパラメータを持っています。
最新のアーキテクチャであるGPT-4の正確なパラメータ数は公表されていません。
ChatGPTは人工知能による対話を実現するために設計されており、自然な言語処理によってユーザーと対話を行います。ユーザーとの対話を通じて学習し、次の対話でより良い回答を提供することができます。
カスタムのトレーニングデータを使用して、特定の業界や分野に特化した対話システムを開発することもできます。
現在、オンラインチャットボットやカスタマーサポート、仮想アシスタント、言語翻訳、文章生成など、さまざまな応用分野で利用されています。
つい最近では、OpenAI社CEOのサム・アルトマン氏が日本に来日して、岸田首相と面会しました。
日本政府側もChatGPTの利活用を検討し始めているようです。
便利な反面、どう利用していくかは大きな課題となっています。
AIの開発停止を求める公開書簡
人工知能に関する専門家たちが、
GPT-4以上のAIシステムの開発を半年間停止するよう公開書簡で呼びかけています。
誤った情報の拡散や、労働市場への影響、
文明のコントロール不能に陥る懸念を理由として挙げていますが、
賛否両論の意見が飛び交っています。
そもそもGPT-4のスペックは公開されていませんし、
我先にと各国・各組織で進められている研究・開発を、止めることは容易ではなさそうです。
プロンプトエンジニアリング
自然言語を用いる対話型のAIから精度の高いアウトプットを得るための質問技術のことです。
AIモデルを有効に活用するためにはプロンプトの形式が非常に重要だと言われています。
DAIR.AIがオープンソースとして公開しているPrompt Engineering Guide
上記を翻訳した日本語版
機械学習(Machine Learning)とは
機械学習は、人工知能(AI)の一分野で、人間がプログラムを直接書くことなく、コンピュータがデータから自動的に学習することを可能にする技術です。
機械学習は、データからパターンを抽出して学習し、新しいデータに対して予測や分類を行うことができます。
大量のデータから「汎用的なパターン」を見つけだす際に、データのどのような特徴に着目すべきかを表す変数が「特徴量」です。
機械学習モデルを構築するために、特徴量を人が指定しなければいけません。
機械学習は、教師あり学習、教師なし学習、強化学習などの種類があります。
教師あり学習
与えられたデータ(入力)を元にして、
そのデータがどんなパターン(出力)になるのかを識別・予測する手法です。
・過去の売り上げを元にして、未来の売り上げを予測する。
→ 数字(連続する値)を予測するものを回帰問題と言います。
・与えられた画像が何の画像であるかを識別する。
→ カテゴリ(連続しない値)を予測するものを分類問題と言います。
・英語の文章を日本語の文章に翻訳する。
教師なし学習
教師なし学習で用いるデータには出力がありません。
入力データそのものが持つ構造・特徴が対象になります。
・ECサイトの売り上げデータから顧客層を分析する。
・入力データの各項目間にある関係性を把握する。
強化学習
行動を学習する仕組み。
ある環境下で、目的とする報酬を最大化するためにはどんな行動を取れば良いかを学習していくものです。
機械学習は、画像認識、音声認識、自然言語処理、推薦システムなどの分野で広く利用されています。また、ビジネス分野でも、顧客セグメンテーション、予測分析、詐欺検知などの用途で利用されています。
ディープラーニング(深層学習)とは
ニューラルネットワークとは
ニューラルネットワークは機械学習の一つです。
人間の脳神経回路を真似することで、学習を実現しようとする手法です。
人間の脳には「ニューロン」と呼ばれる神経細胞が何十億個も張り巡らされており、互いに結びつくことによって巨大なネットワークを構築しています。
何かの情報を受け取った時に、ニューロンに電気信号が伝わります。
この電気信号がネットワーク内を駆け巡ります。ネットワークのどの部分に対してどの位の電気信号を伝えるかによって、人間の脳はパターンを認識しています。
ニューラルネットワークは、このようなニューロンの特徴を再現させた手法になります。

単純なニューラルネットワークのモデルを、単純パーセプトロンと言います。複数の特徴量(入力)を受け取って、1つの値(出力)を出しています。
入力を受け取る部分を「入力層」、出力する部分を「出力層」と言います。
入力層における各ニューロンと、出力層における各ニューロンの間のつながりは「重み」で表されます。
重みで、どれだけの電気信号(値)を伝えるかを調整します。
出力が0か1かの値を取るようにすることで、正と負の分類が可能となります。
出力は0か1だけではなく、0~1の値を取るように閾値の調整も可能です。
どのように電気信号を伝播させるかを調整する関数のことを「活性化関数」と言います。
この単純パーセプトロンでは、線形分類しか行うことができません。
そこで、更に層を追加するモデルが考えられました。

層を追加したモデルを多層パーセプトロンと言います。
入力層と出力層の間に「隠れ層」が追加されました。中間層とも言います。
隠れ層は入力と出力を対応付ける関数に相当しています。
電気信号を伝播していくという仕組みは、単純パーセプトロンと同様です。
しかし、隠れ層が追加されたことで表現力が一気に増し、非線形分類も行うことが可能となりました。
層が増えることで、調整するべき重みの数も増えることになります。
予測値と実際の値の誤差をネットワークにフィードバックするアルゴリズム(誤差逆伝播法)も考えられたことで、より効率的に学習ができるようになりました。
学習するデータ数が多くない場合、
識別や予測性能は他の手法である「ブースティング」や「SVM(サポートベクターマシン)」の方が優れていたため、
ディープラーニングが登場するまでは人気の無い手法でした。
ディープラーニングとは
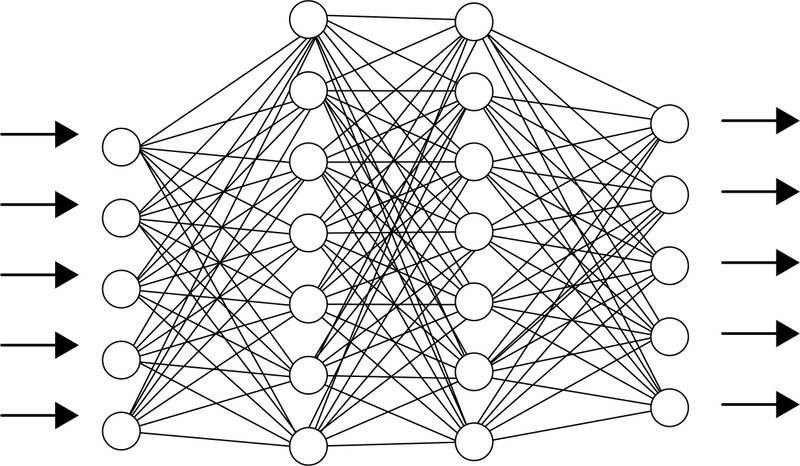
隠れ層を増やしたニューラルネットワークがディープラーニングです。
多層にするアイデア自体は昔から考えられていたのですが、
多層ニューラルネットワークを実用化するにはいくつかの課題があり、研究が下火になっていました。
2006年にトロント大学のジェフリー・ヒントン氏が問題を解決する手法を提唱し、ディープラーニングの主要な構成要素となりました。
研究が進んで課題を解決するアイデアが生まれたと共に、
ハードウェアの進歩とビッグデータのおかげで、ディープラーニングは急速に発展を遂げています。
通常の機械学習と異なり、特徴量の抽出や選択を人間が行う必要がなく、データから自動的に最適な特徴量を抽出することができます。
ディープラーニングは、画像認識、音声認識、自然言語処理など、膨大な量のデータが存在する分野での精度向上に特に優れており、最近では自動運転やロボティクス、医療分野などでも利用されています。
代表的な手法をいくつか紹介します。
フィードフォワードニューラルネットワーク(Feedforward Neural Network):FNN
入力層、中間層、出力層からなる、一方向に信号を伝搬させるニューラルネットワークです。最も基本的なディープラーニングの手法の一つであり、画像認識、音声認識、自然言語処理などの分野で広く利用されています。
畳み込みニューラルネットワーク(Convolutional Neural Network):CNN
画像認識や音声認識などの分野で、高い精度を発揮するニューラルネットワークです。
CNNの基本は、人間が持つ視覚野の神経細胞の2つの働きを模したものになります。
・単純型細胞(S細胞) 画像の濃淡パターン(特徴)を検出
・複雑型細胞(C細胞) 特徴の位置が変動しても同一の特徴であるとみなす
畳み込み層、プーリング層、全結合層から構成され、特徴量の局所性、不変性を考慮した学習ができます。
リカレントニューラルネットワーク(Recurrent Neural Network):RNN
時系列データなど、シーケンスデータを扱う際に使用されるニューラルネットワークです。
通常のニューラルネットワークに対して、過去の隠れ層が追加されています。これまでに与えられた過去の情報が、新しくやってきた情報に対してどのくらいの重みを持っているかを学習します。
時系列的な情報を取り込み、過去の状態から未来の状態を予測することができます。自然言語処理などによく使われます。
オートエンコーダー(Autoencoder)
可視層と隠れ層の2層からなるネットワークで、入力層と出力層はセットになっているものです。
「入力と出力が同じになるようなネットワーク」といえます。
この学習を繰り返すと、入力の情報が圧縮され、大事な情報だけが隠れ層に反映されることになります。
入力層→隠れ層への処理を「エンコード」、隠れ層→出力層への処理を「デコード」と言います。
主にデータ圧縮や特徴量抽出などのタスクで使われます。
敵対的生成ネットワーク(Generative Adversarial Network)
GANはジェネレータとディスクリミネータの二つのニューラルネットワークを競わせることで、新しいデータを生成する手法です。
二つの役割は以下です。
ジェネレータ
ランダムなベクトルを入力し、画像を生成して出力する。
ディスクリミネータ
画像を入力とし、その画像が本物であるか、ジェネレータが生成した偽物であるかを予測して出力する。
ディスクリミネータの予測結果は、ジェネレータにフィードバックされます。ジェネレータはディスクリミネータが本物だと間違えるような画像を作るように学習していき、ディスクリミネータは偽物だと見抜けるように学習をしていくので、最終的には本物と見分けがつかないような画像を作り出すことができます。
画像生成や音声合成などに使用されます。
This, and the variations that are now being proposed is the most interesting idea in the last 10 years in ML, in my opinion.
この記事が気に入ったらサポートをしてみませんか?