
私がC言語を好きな理由 ポインタ変数が必要なデータ構造って?

前回の続きである。
その前回において、
ポインタを持たないプログラミング言語でもポインタは使っているはずだ
と書いた。ポインタを使った方がシンプルで高速で汎用的になる構造というのがある。が、前回はそれを書かなかった。今回はそれを書いてみようかと思う。
例えば、配列
例えば、ここに1つの配列があるとする。
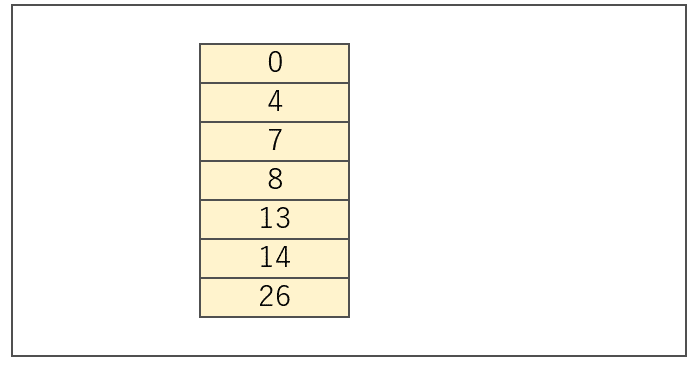
char data[20] = {0, 4, 7, 8, 13, 14, 26};実に実に、ベタな配列だ。
世界最小配列と言っていいかもしれない。
ちなみに、配列というのは
箱の数の上限は決まっていて、箱の位置に意味があるような場合
に適している。
配列は、各要素に対して即座にランダムにアクセスできるという特徴がある。例えば、次のように学生のデータを学籍番号で管理しているとする。
struct _STUDENT students[MAX_STUDENT_NUMBER] = {0};学籍番号さえわかればデータへのアクセスは簡単だ。
students[number-1].name;これだけでこと足りる。
コンパイラは
students の先頭アドレスから number を用いて students[number] のアドレスを計算するというアセンブラ
を出力する。このように四則演算を使って計算できるのであれば、あっという間にアドレスを割り出し students[number] にアクセスできる。何を今さらという内容ではあるが、この「即座にランダムに」アクセスできるというのは大きい。
だが、どんなデータ構造でも苦手分野はある。
配列の最も苦手とするもの。それは、データの挿入削除である。
先ほど例にあげた学生管理データは学籍番号が配列のデータ位置となるので、途中にデータを挿入したり途中のデータを削除したりということはない。なので、この記事の先頭に書いた世界最小配列である「data[20]」で考えてみる。いちいちページをさかのぼるのも面倒なので再掲する。
char data[20] = {0, 4, 7, 8, 13, 14, 26};配列「data」は1byteデータを格納する領域が20個ある。「1byteデータを20個」という配列の実用性はさっぱり思い付かないが、とにかくわかりやすいということだけが取り柄の配列である。ともかくも、数は20個で、今は7個のデータだけが登録されている。そこへ新たなデータの登録が発生する。しかも、登録はベッタコではない(ベッタコ=最後尾。旧大阪弁。最近はあまり聞かず)。例えば、0 の後ろに 2 を追加する場合は、どうすればいいのか。後続の「4、7、8、13、14、26」を全部後ろにずらさなければならない。こんな風に。
for (i = 18; i > 0; i--)
{
data[i+1] = data[i];
}コード上ではたった4行でずらすことは簡単である。しかも今回はわずか18個のデータを移動するだけなので処理時間もないに等しい。だが、データ量が多くなるとその処理時間は膨大なものとなる。新たに登録する度に待たされるのではたまらない。
このように、途中の挿入削除が想定されるようなデータの場合には別のデータ構造が適している。
連結リストである。
実は連結リストについては note の記事でも幾つか書いた。後で列挙する。連結リストとはどんなものか。
まず、配列は [0]~[19] までが1つのかたまりである。1つ1つの要素は配列全体の中の一部分にすぎない。
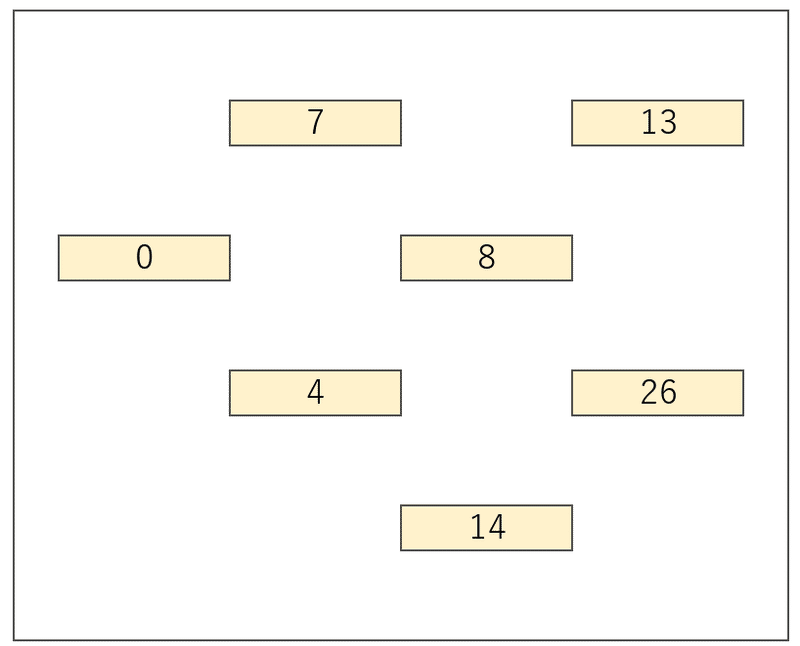
連結リストの場合、まずこれら1つ1つの要素をバラバラにする。
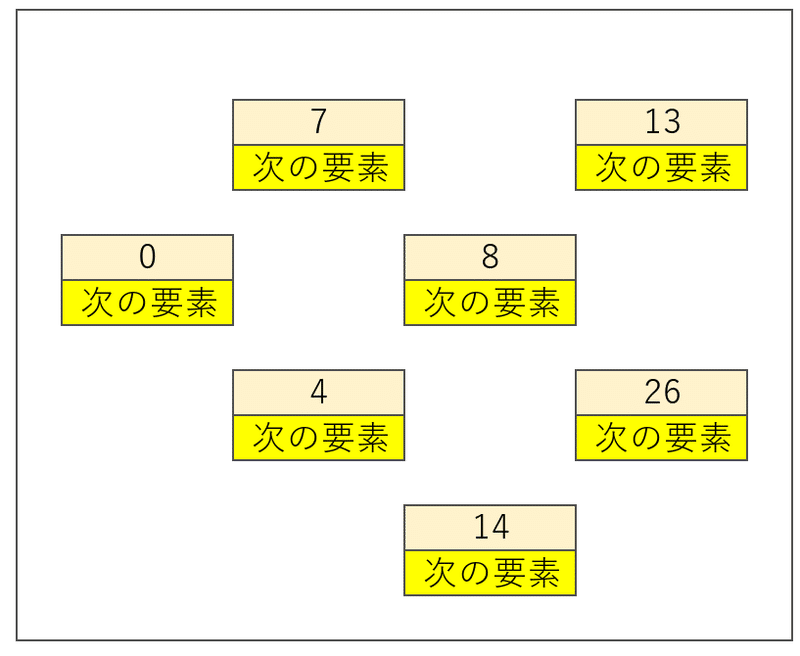
バラバラにした要素に「次の要素」を指し示す情報を追加する。
しかるのちに、「次の要素」で各要素をつないでいくのである。
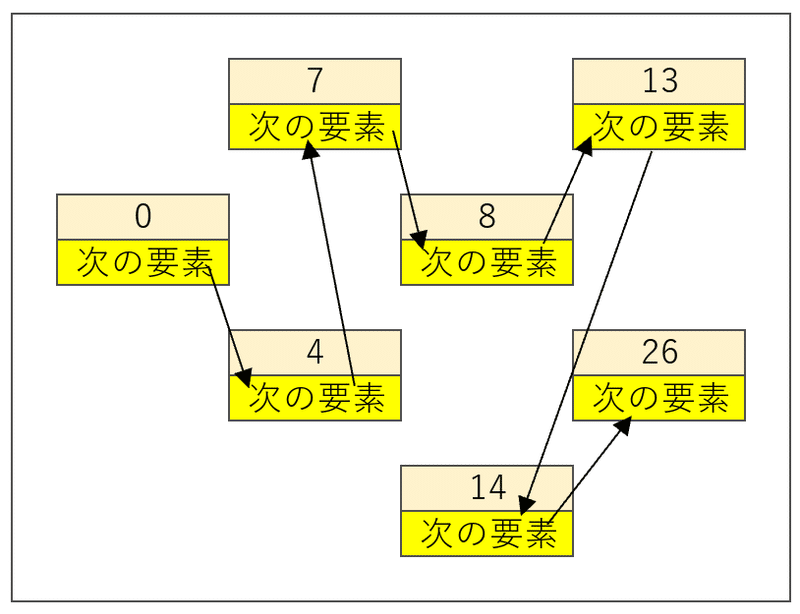
大変長らくお待たせした。ようやくここで登場するのが、そう、ポインタなのである。「次の要素」を指定するために「次の要素のポインタ」を使うのである。「ポインタ」とはアドレスのことであるので、「次の要素のポインタ」とはすなわち「次の要素のアドレス」のことを意味する。
データはメモリのどこかに格納されて
メモリは必ずアドレスを持ち
それらのアドレスは必ず排他的である
排他的であるとは、
各要素のアドレスは必ず違う値である
ということだ。アドレスを指定して「このアドレスはデータAとデータBのどちらを指すのだろうか」などと悩むようなことは一切ない。アドレスが決まれば必ずデータを特定できる。なんとも、連結リストを構築するのにうってつけの値ではないか。
こうしておけば、要素の挿入削除も簡単である。
先ほどと同じように、「2」を「0」の後ろに追加してみる。こんな風になる。
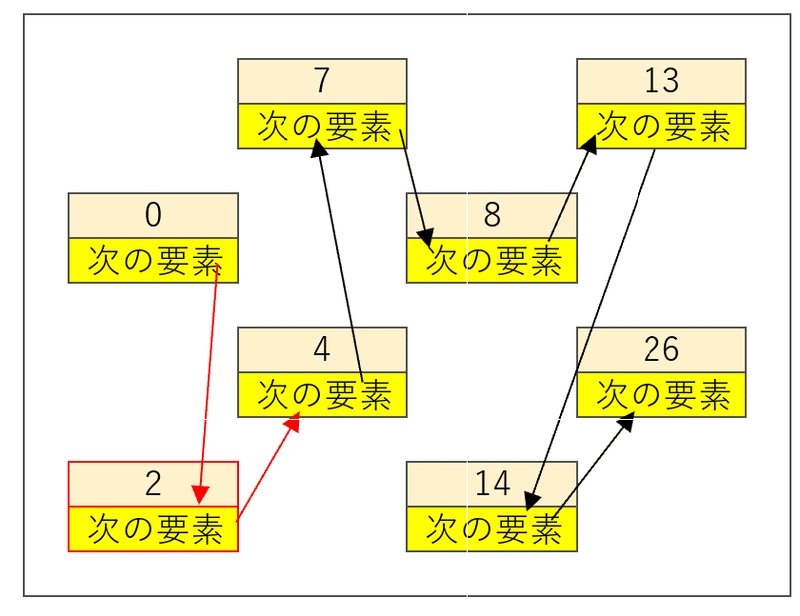
簡単である。
4 ~ 26 を全部ずらすというようなどんくさいことをせずにすむ。この例でいくと、0 の次の要素と、2 の次の要素をちょいと書き換えるだけだ。100万個のデータを扱っているとすると、配列が100万個のデータ移動を余儀なくされるのに対して、連結リストの場合は2値を書き換えるだけでよい。
しかし。
くどいようだが、どんなデータ構造でも苦手分野はある。
連結リストの最も苦手とするもの。それは、データのランダムアクセスである。そう、配列の得意中の得意だったランダムアクセスが実に苦手なのである。10個のデータがあったとして、あるデータが何番目に位置しているのか、それがわかりにくいのだ。そりゃ当然だ。並べ替えを簡単にしたのだから、順序は常に入れ替わる。連結リストの何番目に位置するのかを知るためには、連結リストの先頭から数を数えながらたどっていくしかない。100万個のデータの99万9990番目だったりすると最悪である。99万9990回数えなければならない。プログラムは数行ですむかもしれないが、実行には数秒、あるいは数10秒かかるかもしれない。高速で並べ替えを実現するためには、高速のランダムアクセスを犠牲にせざるを得ない。
さて。
ポインタを利用した連結リストのプログラムというのは次のようになる。
#include <stdlib.h>
typedef struct node {
int data;
struct node* next;
} Node;
//#####################################
// 新しい要素を生成する
Node* node_new(int data)
{
Node* _node_new = (Node*)malloc(sizeof(Node));
_node_new->data = data;
_node_new->next = NULL;
return _node_new;
}
//#####################################
// 2つの要素をリンクする
Node* node_link(Node* _node1, Node* _node2)
{
if (_node1 == NULL) {
return _node2;
}
if (_node2 == NULL) {
return _node1;
}
_node2->next = _node1->next;
_node1->next = _node2;
return _node1;
}
//#####################################
void print_list(const Node* _node);
void test_node_append();
//#####################################
void print_list(const Node* _node)
{
const Node* p;
for (p = _node; p != NULL; p = p->next) {
printf("%d ", p->data);
}
}
//#####################################
void test_node_append()
{
Node* _node_new = NULL;
Node* _top = NULL;
Node* _bottom = NULL;
_node_new = node_new(1);
_top = _node_new;
_bottom = _node_new;
_node_new = node_new(2);
node_link(_bottom, _node_new);
_bottom = _node_new;
_node_new = node_new(3);
node_link(_bottom, _node_new);
_bottom = _node_new;
_node_new = node_new(4);
node_link(_bottom, _node_new);
_bottom = _node_new;
printf("print_list = ");
print_list(_top);
printf("\n");
printf("\n");
}
int main()
{
test_node_append();
return 0;
}連結リストの操作については、「new」と「link」という、極々基本的な関数のみとした。実際の連結リストは、もちろんもっと多岐な関数が用意される。「new」があれば「delete」もあろうし、「link」があれば「unlink」もあるだろう。あまり機能過多にするとリストのなんたるかがわかりにくくなるので、最小限の「連結する」という機能に限定している。
更にまた、こちらの方が重要であるが、汎用ライブラリとして提供する場合としては極めて原子的である。こんなレベルを公開していてはポインタが丸見えであり、ポインタをプログラマから遠ざけたいという切なる願望は思いをとげない。なので、ライブラリとして提供する場合においては、もう一段抽象化したレベルを用意してそちらを提供すべきである。それが「汎用」であるならば、「した方がよい」ではなく「すべき」である。
「抽象化」とは、データの構造を見えないようにする作業である。ライブラリを使う側からすると「リスト」という形式のデータ構造がほしいのであって、それが「配列」で実現されているのか、はたまた「連結リスト」で実現されているのかはどうでもよい。理想的なライブラリは、アプリケーションを変更せずとも、「配列」を「連結リスト」へ、あるいは「連結リスト」を「配列」へ変更することが可能である。それを可能とするならばそのライブラリは優れたライブラリであって、設計者は極めて優れたプログラマと言える。長年プログラマをやっているが、それほどに優れたプログラムにはめったにお目にかからない(私自身も含めて)。
最後に、フォローさんのC言語教室で楽しませていただいた連結リストに関する過去記事を紹介する。フォローさんの記事へもたどれるので是非!
この記事が気に入ったらサポートをしてみませんか?