ゼロから始める株式分析:J-Quants APIを用いた日本株寄り引けロングショート戦略分析
こんにちは、botter_01です。
はじめに
このチュートリアルでは,株式分析の初心者を対象にPythonとJ-Quants APIを用いて,株式市場のデータ分析を行います。
初心者でも理解しやすいように、基本的なデータの取得方法から、特徴量の計算、機械学習モデルの構築、そしてモデルの評価までを、ステップバイステップで解説していきます。
チュートリアルを実行することで,テストデータで約53%の正答率となった機械学習モデルを構築することができます。
具体的には,日本株のうちTOPIX500採用銘柄を投資対象として,寄り引けロングショート(LS)戦略の分析します。
寄り引けLS戦略を採用した理由は,次のとおりです。
ロングポジションもショートポジションも持つので市場の値動きに左右されにくい点
日中の寄り付きでポジションを持ち,引けで手仕舞うため,他の市場(特に米国株式市場)動向に影響を受けにくい点
ポジションを持ち越さないため,取引手数料が低減できる点
ライブラリのインポート
まず初めに必要なライブラリをインポートします。
これ以降のコードはgoogle colabでの実行を想定しています。
ローカル環境で実行する場合は適切に修正してください。
import pandas as pd
import numpy as np
import joblib
from tqdm.auto import tqdm
import matplotlib.pyplot as plt
from datetime import datetime, timedelta
import os
import lightgbm as lgb
import warnings
from sklearn.preprocessing import KBinsDiscretizer
warnings.filterwarnings('ignore')
from google.colab import drive
drive.mount('/content/drive')
! pip install jquants-api-client shap
import jquantsapi
import shap
データ保存先のパス及びデータ期間の設定
google driveをマウントし,保存先のディレクトリを作成します。
また,J-Quants APIにより読み込むデータの保存先を指定します。
dir_path = '/content/drive/MyDrive/jquants-trial'
# 指定されたパスが存在しない場合にのみディレクトリを作成する
if not os.path.exists(dir_path):
os.mkdir(dir_path)
filepath_stock_price = os.path.join(dir_path, 'stock_price_load.gz')
filepath_stock_list = os.path.join(dir_path, 'stock_list_load.gz')
J-Quants APIから取得するデータの期間を指定します。
このチュートリアル内ではライトプランを想定し,過去5年間のデータを取得することとしています。
なお,無料プランの場合は2年間(2週間ラグあり)を取得できます。
# J-Quants API から取得するデータの期間。ライトプランを想定し,5年間のデータ取得としています。
# 無料プランの場合は2年間(2週間ラグあり)取得できます。
HISTORICAL_DATA_YEARS = 5
start_dt = datetime.now().replace(hour=0, minute=0, second=0, microsecond=0) - timedelta(days=(HISTORICAL_DATA_YEARS*365))
end_dt = datetime.now().replace(hour=0, minute=0, second=0, microsecond=0)
start_dt_yyyymmdd = start_dt.strftime("%Y%m%d")
end_dt_yyyymmdd = end_dt.strftime("%Y%m%d")
print( f'{start_dt_yyyymmdd}から{end_dt_yyyymmdd}までの記録を使用します。' )J-Quants APIを用いた価格データの読込み
J-Quants APIのpythonクライアントライブラリを使用して,
上場銘柄一覧を読み込み,TOPIX500採用銘柄のtickerを取得します。
本チュートリアルにおいては,ユニバースをTOPIX500に限定します。
これは,空売りを想定していたり,銘柄の流動性を担保するためです。
# J-Quants APIクライアントの初期化
cli = jquantsapi.Client()
if os.path.exists(filepath_stock_list):
# ファイルが存在する場合、読み込む
stock_list_load = pd.read_csv(filepath_stock_list, compression='gzip')
else:
# ファイルが存在しない場合、新たに作成する
stock_list_load = cli.get_listed_info()
stock_list_load.to_csv(filepath_stock_list, compression='gzip', index=False)
# 株価情報のobject型をdatetime64[ns]型に変換
stock_list_load["Date"] = pd.to_datetime(stock_list_load["Date"])
# 普通株 (5桁で末尾が0) の銘柄コードを4桁にします
stock_list_load["Code"] = stock_list_load["Code"].astype(str)
stock_list_load.loc[(stock_list_load["Code"].str.len() == 5) & (stock_list_load["Code"].str[-1] == "0"), "Code"] = stock_list_load.loc[(stock_list_load["Code"].str.len() == 5) & (stock_list_load["Code"].str[-1] == "0"), "Code"].str[:-1]
stock_list_load["Code"] = stock_list_load["Code"].astype(int)
# TOPIX500のtickerのみを取得する
categories = ['TOPIX Mid400', 'TOPIX Large70', 'TOPIX Core30']
tickers = stock_list_load[stock_list_load['ScaleCategory'].isin(categories)]['Code'].unique()
tickers = tickers.astype(str)続いて,株価四本値(ohlcv)を取得します。
if os.path.exists(filepath_stock_price):
# ファイルが存在する場合、読み込む
stock_price_load = pd.read_csv(filepath_stock_price, compression='gzip')
else:
# ファイルが存在しない場合、新たに作成する。初回は10分以上かかると思います。
stock_price_load = cli.get_price_range(start_dt=start_dt, end_dt=end_dt)
stock_price_load.to_csv(filepath_stock_price, compression='gzip', index=False)
# "Code"列を文字列型に変換
stock_price_load["Code"] = stock_price_load["Code"].astype(str)
# 普通株 (5桁で末尾が0) の銘柄コードを4桁にします
stock_price_load.loc[(stock_price_load["Code"].str.len() == 5) & (stock_price_load["Code"].str[-1] == "0"), "Code"] = stock_price_load.loc[(stock_price_load["Code"].str.len() == 5) & (stock_price_load["Code"].str[-1] == "0"), "Code"].str[:-1]
stock_price_load先ほど取得したtickerを用いて,銘柄をTOPIX500に限定します。
df_ohlcv = stock_price_load[stock_price_load['Code'].isin(tickers)]
df_ohlcv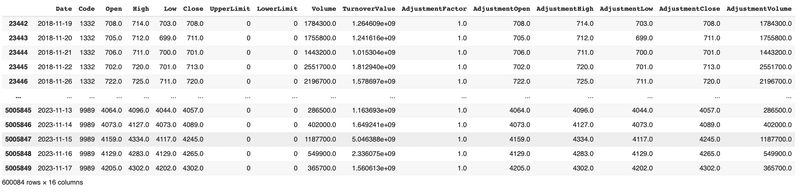
特徴量と目的変数の計算
特徴量と目的変数(target)を計算します。
本チュートリアルでは基本的な特徴量として,以下のものを計算します。
1日,5日,25日リターン(1日リターンのみはラグを計算)
5日,25日移動平均乖離率
5日,25日ボラティリティ
一般的に機械学習モデルにおいては,学習データとテストデータで特徴量の分布が似ていること(定常性)が求められます。
したがって,価格系列(株価)そのものを特徴量として使用するのではなく,その階差系列(リターン)を定常とみなして分析を行うことが一般的です。
参考:株式分析チュートリアル 2.7.2. 定常性を意識した特徴量設計
また,目的変数は冒頭で説明したように寄り付きでポジションを構築し,引けでクローズするため, Close / Open - 1.0 という式で計算しています。
def calc_features(df_ohlcv):
# Creating a new DataFrame to store the features
df_feats = df_ohlcv[['Date','Code','Close']]
df_feats['ror1'] = df_ohlcv['Close'].pct_change(1).fillna(0)
df_feats['ror5'] = df_ohlcv['Close'].pct_change(4).shift(1).fillna(0)
df_feats['ror25'] = df_ohlcv['Close'].pct_change(20).shift(5).fillna(0)
df_feats['MA5_gap'] = (df_ohlcv['Close'].rolling(5).mean() / df_ohlcv['Close'] - 1.0).fillna(0)
df_feats['MA25_gap'] = (df_ohlcv['Close'].rolling(25).mean() / df_ohlcv['Close'] - 1.0).fillna(0)
df_feats['volatility5'] = np.log(df_ohlcv['Close']).diff().rolling(5).std().fillna(0)
df_feats['volatility25'] = np.log(df_ohlcv['Close']).diff().rolling(25).std().fillna(0)
df_feats['ror1_lag1'] = df_feats['ror1'].shift().fillna(0)
df_feats['target'] = (df_ohlcv['Close'] / df_ohlcv['Open'] - 1.0).shift(-1)
return df_feats
tqdm.pandas()
# 銘柄ごとに特徴量の計算
df_feats = df_ohlcv.groupby('Code').progress_apply(calc_features)
df_feats
このチュートリアルを改善していく方策として,特徴量を追加することが考えられます。下記にその例を記載します。
記載する特徴量のほとんどはJ-QuantsAPIにより計算可能です。
主要なファクター:バリュー,クオリティ,サイズ,ベータ(PBR,ROE,時価総額,ベータ等)
その銘柄が属するセクター/業種を特徴量に与える
セクター/業種/市場全体のリターン
オルタナティブ特徴量
モデルの学習と評価
取得した5年間のデータを訓練データとテストデータに分割します。 今回は簡単のために5年間のデータのうち前半の3年間を訓練データ,後半の2年間をテストデータとしています。
TRAIN_DATA_YEARS = 3
TEST_DATA_YEARS = 2
# TRAIN_DATA_YEARS + TEST_DATA_YEARS <= HISTORICAL_DATA_YEARS となるようにしてください
train_start_dt = datetime.now().replace(hour=0, minute=0, second=0, microsecond=0) - timedelta(days=(HISTORICAL_DATA_YEARS*365))
train_end_dt = train_start_dt + timedelta(days=(TRAIN_DATA_YEARS*365))
test_start_dt = train_end_dt + timedelta(days=1)
test_end_dt = test_start_dt + timedelta(days=(TEST_DATA_YEARS*365))
train_start_dt_yyyymmdd = train_start_dt.strftime("%Y-%m-%d")
train_end_dt_yyyymmdd = train_end_dt.strftime("%Y-%m-%d")
test_start_dt_yyyymmdd = test_start_dt.strftime("%Y-%m-%d")
test_end_dt_yyyymmdd = test_end_dt.strftime("%Y-%m-%d")
print( f'訓練データ : {train_start_dt_yyyymmdd}から{train_end_dt_yyyymmdd}までの記録を使用します。' )
print( f'テストデータ: {test_start_dt_yyyymmdd}から{test_end_dt_yyyymmdd}までの記録を使用します。' )(補足)訓練データとテストデータとは
訓練データ:訓練データはモデルが学習するために使用されます。このデータを使ってモデルはパターンを見つけ出し,予測を行うためのルールや関数を学びます。
テストデータ:テストデータはモデルの性能を評価するために使われます。このデータは学習には使用されず,モデルが新しい,見たことのないデータに対してどれだけうまく予測できるかをテストするために使われます。
改良の余地として,データ分割においてcross-validation(CV)やpurged CV, CPCV等を使う例があります。
続いて特徴量と目的変数(target)を定義し,
X_train, y_train, X_test, y_test を作成します。
# 特徴量として使用するカラム
features = [
'ror1',
'ror5',
'ror25',
'MA5_gap',
'MA25_gap',
'volatility5',
'volatility25',
'ror1_lag1',
]
# ターゲット変数として使用するカラム
target = 'target'
# 2018年から2021年の3年間をデータを訓練データ、2022年から2024年の2年間のデータをテストデータにします。
df_train = df_feats[(df_feats['Date'] >= '2018-01-01') & (df_feats['Date'] < '2022-01-01')]
df_test = df_feats[(df_feats['Date'] >= '2022-01-01') & (df_feats['Date'] < '2024-01-01')]
# 学習データとテストデータの特徴量とターゲットを定義
X_train = df_train[features].fillna(0)
y_train = df_train[target].fillna(0)
X_test = df_test[features].fillna(0)
y_test = df_test[target].fillna(0)さらに今回は,特徴量を五分位にビニングします。
その理由として,金融時系列データは過分散であることが指摘されており,このようなデータを学習すると過学習を起こし,モデルのロバスト性が失われる可能性が高まるからです。
(以下,関係する記事・ツイート)
ファイナンスデータの分位化(binning)について理想的な正規分布を仮定したモンテカルロシミュレーションで効果を確認しました。分散が大きくなるにつれて顕著に効果が出ます。フィナンシャルデータは過分散なので恩恵は大きいはず。binnningを活用しましょう。
— UKI (@blog_uki) July 10, 2020
現場からは以上です。 pic.twitter.com/1QQalYhjFM
# KBinsDiscretizerを初期化し、5分位の等分布でビニングを行う
discretizer = KBinsDiscretizer(n_bins=5, encode='ordinal', strategy='quantile')
# 訓練データにフィットし、変換する
discretizer.fit(X_train)
X_train_binned = discretizer.transform(X_train)
# テストデータにも同じ変換を適用
X_test_binned = discretizer.transform(X_test)
# NumPy配列からPandasデータフレームへ変換し、列名を設定
X_train = pd.DataFrame(X_train_binned, index=X_train.index, columns=[f"{feat}_binned" for feat in features])
X_test = pd.DataFrame(X_test_binned, index=X_test.index, columns=[f"{feat}_binned" for feat in features])
(2023/12/10追記)
本記事の初期版は,binningの部分でリークしておりました。ご指摘いただいたyoshisoさんありがとうございます!上記のコードは修正済みのものです。
こんにちは、リーク警察ですがqcutがリークしています。
— よしそ (@yoshiso44) December 8, 2023
学習モデルにはkaggle等でよく用いられる決定木系のアルゴリズムであるLightGBMを使用します。
他にRidge回帰などの線形モデルやNNモデル,その組み合わせ(アンサンブル)を用いることが考えられます。
# LightGBMモデルの学習
model = lgb.LGBMRegressor(random_state=42, verbose=-1, max_depth=4)
model.fit(X_train, y_train)
# 訓練データでの予測値
df_train['y_pred'] = model.predict(X_train)
# テストデータでの予測値
df_test['y_pred'] = model.predict(X_test)
訓練データとテストデータの性能を評価します。
評価指標としては,以下を使用しています。
予測値(y_pred)と正解値(target)の相関係数
相関係数のシャープレシオ
日毎の正答率
なお,run_analytics関数のコードは下記Colab Notebook内のコードを参考にしています。
# 訓練データ,テストデータのスコアを計測。テストデータに対し,訓練データが過学習していないか確認する。(例:訓練データの正答率が70%越え等は非現実的)
def score(df, target_name='target', pred_name='y_pred'):
'''Takes df and calculates spearm correlation from pre-defined cols'''
# method="first" breaks ties based on order in array
return np.corrcoef(
df[target_name].fillna(0),
df[pred_name].rank(pct=True, method="first")
)[0,1]
def run_analytics(era_scores):
print(f"Mean Correlation: {era_scores.mean():.4f}")
print(f"Median Correlation: {era_scores.median():.4f}")
print(f"Standard Deviation: {era_scores.std():.4f}")
print('\n')
print(f"Mean Pseudo-Sharpe: {era_scores.mean()/era_scores.std():.4f}")
print(f"Median Pseudo-Sharpe: {era_scores.median()/era_scores.std():.4f}")
print('\n')
print(f'Hit Rate (% positive eras): {era_scores.apply(lambda x: np.sign(x)).value_counts()[1]/len(era_scores):.2%}')
era_scores.rolling(10).mean().plot(kind='line', title='Rolling Per Era Correlation Mean', figsize=(15,4))
plt.axhline(y=0.0, color="r", linestyle="--"); plt.show()
era_scores.cumsum().plot(title='Cumulative Sum of Era Scores', figsize=(15,4))
plt.axhline(y=0.0, color="r", linestyle="--"); plt.show()
print('--- Train Score ---')
train_scores = df_train.groupby('Date').apply(score)
run_analytics(train_scores)
print('\n')
print('--- Test Score ---')
test_scores = df_test.groupby('Date').apply(score)
run_analytics(test_scores)
print('\n')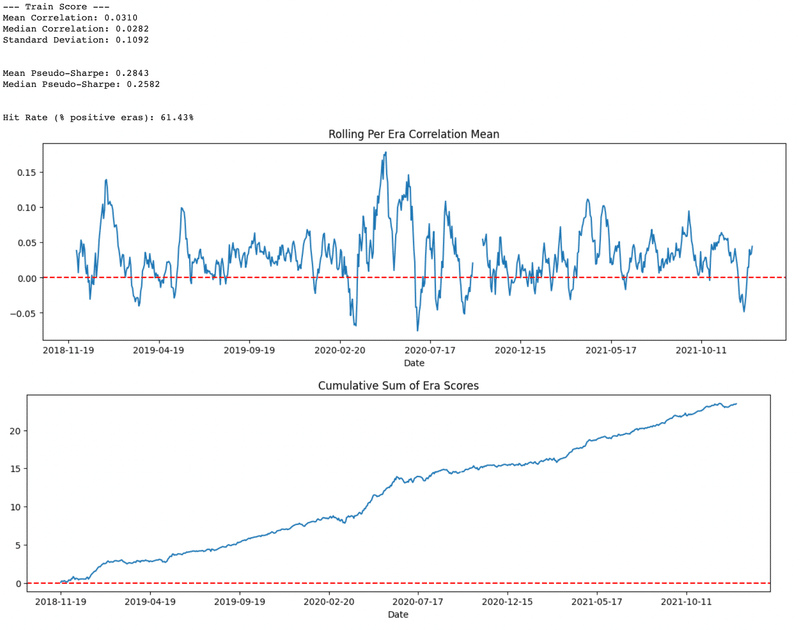

筆者がコードを実行した時点では,テストデータに対して正答率約53%の性能が出ました。
単純なモデルにしては十分な性能だと思われます。
特徴量重要度の分析
最後に,モデルは特徴量をどのように使用したか,SHAPというライブラリを用いて予測結果を分析します。
機械学習モデルは単純な線形モデルとは異なり,モデルの予測結果の解釈が難しいです。このSHAPライブラリを用いることで,特徴量の重要度を解釈することができます。
# SHAPの計算
explainer = shap.Explainer(model)
shap_values = explainer(X_test)
# 特徴量の重要度の可視化
shap.summary_plot(shap_values, X_test)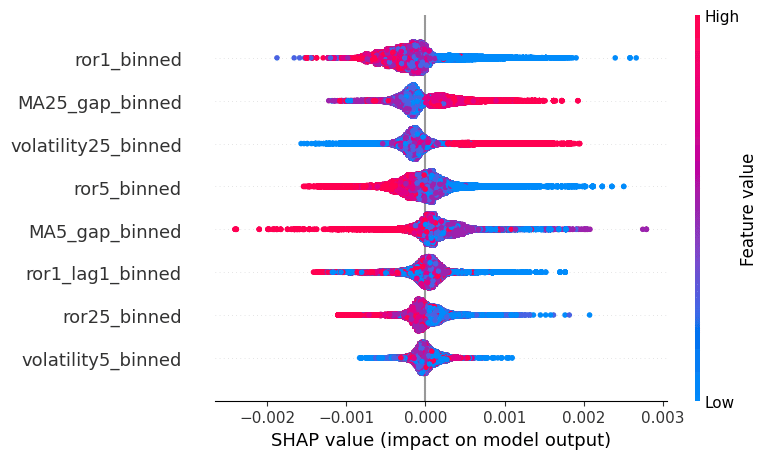
ここで,SHAPのsummary_plotでは上にある重要度が高い特徴量であると解釈されます。
すなわち,ror1_binned(前日リターンの五分位)が最も重要な特徴量であることがわかります。
ror1_binnedのFeature valueを見ると,この値が小さいほどSHAP valueが大きいので,前日リターンが小さいほど,モデルが正の出力を出すことになります。
すなわちリバーサル効果をモデルが捉えていることが示唆されます。
次に重要なのがMA25_gap_binned(25日移動平均乖離率の五分位)で,Feature valueが大きい場合,SHAP値も大きくなっており,これはモメンタム効果をモデルが捉えた結果であると思われます。
このような特徴量重要度の分析を手がかりに,特徴量を選択していくことでモデルの精度向上を目指します(オーバーフィットには注意)。
まとめ
本チュートリアルでは,J-Quants APIを用いて日本株の寄り引け戦略の分析を行いました。
モデルには単純な特徴量を与えましたが,モメンタム効果やリバーサル効果と思われるものを学習し,テストデータに対して勝率53%程度の結果を得ることができました。
ご意見,ご指摘,質問事項等ございましたらコメントまたは筆者のXアカウントまでご連絡ください。
https://twitter.com/botter_01
この記事が気に入ったらサポートをしてみませんか?