
AIは「知識を得ている」わけではない

先日、NHKのニュース番組でChatGPTが取り上げられていましたが、その中でこんなやりとりがありました。
「ChatGPTに『ニュース9はどんな番組?』と聞くと、朝の情報番組と答えました。このようにまだまだ精度については問題があります」
恐らく情報系でAIの仕組みを知っている人からすると「そりゃそうだろう」と思うのですが、世間一般のAIに対する認識とは大きな隔たりがあるように思えます。誤解を恐れずに言うと、世間一般でのAIは「知識を得たプログラム」であると理解されているのに対して、実際のAIは「仕組みを学習したプログラム」であることに原因があるのではないかと思います。
※仕組みも知識の一部だとは思うのですが、ここは分かりやすく「知識=辞書に載せるような意味理解」としておきます
※ChatGPT等の論文を読み込んだわけではないので下記の内容は古いかも知れませんがご了承ください
AIは仕組みを学習する
ChatGPTに限らず、AI技術は一般的に「学習」という過程を経てから「推論」を行います。このため、学習しているのだからAIは知識を得ていると思われがちですが、ほとんどの場合はそうではありません。「学習」が意味しているのは世間一般で考えているような「知識」を得ているわけではないのです。
例えば人物を検出するAIは、学習の過程で多くの人物データ(教師データ)を使います。それらの人物データを「学習」することで人物を検出できるようになります。しっかり学習ができていれば、教師データに無い人物であっても人物として検出できるようになります。これは、元のデータから「人物とは頭があり両手があり両足があるようなもの」という「仕組み」を学習しているためです。顔検出や物体検出を使ったことがある人はこの「仕組み」を学習していることを体感しているのではないでしょうか。
対話型AIはどのように学習するでしょうか。もの凄く簡単に説明すると、「富士山は日本で一番高い山です」という文章の一部を欠落させて「富士山は日本で一番〇〇〇です」という文章にし、AIに入力します。最初はAIの出力はランダムで「富士山は日本で一番あああです」のように答えますが、正解は「高い山」なので間違いであることをAIに伝えます。AIは内部パラメータを変えて別の答えを出力しますが、その回答に対して「惜しい」「さっきより悪い」といったフィードバックを行うことで、そのうち「富士山は日本で一番高い山です」と答えられるようになります。
学習データが一つだけだと何を聞いても「高い山」としか答えないAIができるだけです。複雑な回答をしてほしければ様々な文章を用意して学習させていきます。日本の山岳について全てのデータと、「信濃川は日本で一番長い川です」などの河川に関する文章も同様に学習させてみていいでしょう。やがて山や川について答えてくれるAIが出来上がったとします。
さて、出来上がったこのAIは日本の山と川についての教師データを内部に持っているわけではありません。先ほどの人物を検出するAIが大量の人物画像を保持していないのと同じです。つまり、山岳に関する知識を得たのでは無く、ただ「文字の羅列に対する回答の仕組み」を学習したに過ぎません。
例えばこのAIに「富士棒山は日本で一番〇〇〇です」と聞くと、恐らく「高い山」と答えるでしょう。富士山ではないですが、文字列が富士山に近いので確率的に「高い山」であると答えるのです。
これはChatGPTでも同様です。試しに富士棒山について聞いてみましょう。

あまりにもそれっぽくてドキッとしましたが、調べてみてもそんな山はありません(本当にあったらごめんなさい)。ChatGPTは「富士棒山」という名前から「恐らくこういう山である確率が高い」と判断してこのような文章を出力しています。実際には富士棒山は無いので、知識を問う回答に対する精度としては0点ですが、回答を作るという仕組みとしての精度は非常に高いと言えるでしょう。
冒頭の「ニュース9」についてはどうでしょうか。今は同じことをChatGPTに聞いても正解しか答えてくれないので確認できていませんが、恐らく「ニュース9」という文字列から「朝の9時のニュース番組」と判断したのでしょう。何も知らない人が聞いた反応という意味では正しい気がします。
AIは知識を答えるように振る舞う
それでは対話型AIは常に嘘つきなのか、というとそうではありません。例えば普通に富士山のことについて聞けば答えてくれますし、それなりにマイナーな情報であっても正確に答えてくれます。まるで知識を持っているかのようですし、人間からそう見えるのであれば「知識を持っている」と言えるかもしれませんが、その原因は以下の二つがあります。
教師データに含まれている
1つ目は質問の内容が教師データに含まれている場合です。著名な内容なら教師データに含まれていてもおかしくありませんし、誰かが回答の「いいね」を押したことで新しく学習している可能性もあります。この場合、教師データに不正確な情報が含まれているとAIは不正確な回答をします。また、例えば教師データに「富士山は山です」「北岳は山です」のように山の情報ばかりを与えていると「信濃川って何ですか?」と聞いても「山です」と答えるでしょう。教師データに偏りがあるとAIの回答にも偏りが生じます。
具体的な懸念を挙げると、例えば「政権与党が素晴らしい」という情報ばかりを教師データとして与えてしまえば、「政権与党をどう思うか」という問いに対して「素晴らしい」と答えてしまいます。分かりやすいバイアスであれば気付けますが、気付けないレベルのバイアスがかかっていると予期せず不幸な事態を招くかも知れません。いわゆるステルスマーケティングのような問題が水面下で起きるでしょう。
インターネットから検索してくる
2つ目は入力された内容をインターネットからリアルタイムに検索してくるような手法が用いられている場合です。恐らくですが内容の出典元を示すようなAIエンジンは似たようなことをしていると思います。これは新しい手法でもなんでもなく、昔から「対話型AIは学習したことしか回答できない」という課題に対する解決策として考えられていました。Amazon のAlexaに何かを聞くとネット検索した結果を教えてくれるように、よく用いられている方法とも言えます。さて、ではこの場合は正確な情報が返ってくるでしょうか?そうとは限りません。インターネットの検索結果が正しいとは限らないからです。そもそも何をもって正確な情報と言うのかが難しいのですが、例えばWikipediaであっても正確では無いですし、その他の情報サイトも確率的に正確性が高いだけであってバイアスがかかっている可能性は否定できません。また、出てきた情報を要約する段階で偽情報となってしまう場合もあるでしょう。
AIの知識をあてにしない
要するに、現段階ではAIに直接知識を聞いてはいけないのです。特に、どのような教師データで学習したか分からないAIに対して知識を求め、その結果を何かに利用するようなことは絶対にやめた方が良いでしょう。「来年、テスラの株価は上がると思いますか?」といった回答の結果を使って投資しても全く保証がないのです。
例えば昔の2chで下記のようなやりとりがありました。
819 学生さんは名前がない:2008/05/01(木) 16:40:48 O
このスレで聞くのも恐縮なんですが、吉野家ってどういう注文システムなんですかお?( ^ω^)
松屋みたいに食券なんですかお?( ^ω^)
食べくらべしてみたいんだお( ^ω^)
821 学生さんは名前がない:2008/05/01(木) 16:44:15 0
>>819
お新香とサラダは食べ放題だお( ^ω^)
勝手に取って食べまくるといいお( ^ω^)
885 学生さんは名前がない:2008/05/01(木) 20:48:15 0
>>821
てめえ、一生恨んでやる
あやうく 警察沙汰だ
ChatGPTに何かを聞いてその結果で行動するというのは、まさにこのコピペと同じ行動です。
もちろん、当時の2chや今の5ch、Twitterでも正しい情報がありますが、そうでないものは無数とあります。そのぐらいの情報精度だと認識した方が良いでしょう。
もちろん、分かった上で使うのはこの限りではありません。左翼系の新聞なのか、右翼系の新聞なのかを理解した上で情報収集することと何ら変わりありません。
また、直接的にAIへ質問を投稿するのは難しいと思いますが、あくまでAIをシステムとして使うのであれば使い方次第になります。例えば、「明日の天気を教えて」と聞いても教えてくれませんが、下記のように聞くことはできます。
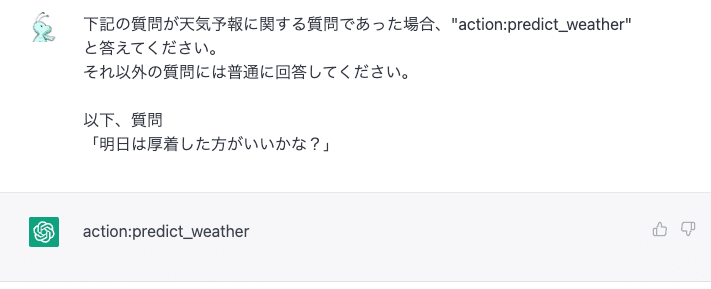
このような質問を行い、AIが「action:predict_weather」と返してくれば天気予報APIを使って天気予報を取得し、正確な天気予報を伝えてあげればよいのです。この例のように質問内容に「天気」「晴れ」「雨」といった内容が含まれていなくても、ChatGPTはちゃんと天気予報に関する質問であることを把握してくれています。これを普通のプログラムで作ろうとするのは非常に大変かつ低精度になりがちです。ユーザーからの質問がどのような質問であるかを分類したりするだけでも、対話型AIは十分に便利です。
また、このような使い方は教師データに偏りがあったとしても問題ありません。教師データに偏りがあったとしても、発話内容が天気予報であるかどうかを判断する仕組みそのものには変わりがないのです。また、天気予報に関する質問であることを見抜けなかったとしても、間違えた情報を教えるのでは無いので致命的に悪い結果とはなりにくいといえます。加えて、このような条件を複数付ければある程度の会話内容をシステム側のコントロール配下に置くことができます。対話型AIを利用する場合、使う側がコントロールできる範囲内で利用することが重要になるでしょう。
さて、上記のような質問であれば、前提条件に取得した天気予報を載せて回答を作らせても良いでしょう。

良い感じで答えてくれます。
まとめ
AIは「知識」を得ているのでは無く、「仕組み」を得ています。
そのため、知識を聞いても間違えた答えを平気で返してきますし、教師データに依存した回答になってしまいます。また、そもそもインターネット上に正しい知識があるわけではないので、正しい知識をAIに求めるには使い方に工夫が必要です。
例えば製品マニュアルを学習させておいて、それに関する質問に答えさせる、といった使い方があります。この場合でもマニュアルに記載がないことを回答されては困るので、学習させる情報に何らかのタグを付けておいて、それ以外は回答しない、といった使い方を検討する必要があります。
まだまだ成長途中の対話型AIですが、可能性は非常に大きな物を持っているので妙な使い方をした結果の悪影響等で変な規制がかからないことを切に願うばかりです。
この記事が気に入ったらサポートをしてみませんか?