
19章 Q学習:グリッドワールド問題を解くQ学習とは!?

はじめに
シリーズ「Python機械学習プログラミング」の紹介
本シリーズは書籍「Python機械学習プログラミング PyTorch & scikit-learn編」(初版第1刷)に関する記事を取り扱います。
この書籍のよいところは、Pythonのコードを動かしたり、アルゴリズムの説明を読み、ときに数式を確認して、包括的に機械学習を学ぶことができることです。
Pythonで機械学習を学びたい方におすすめです!
この記事では、この書籍のことを「テキスト」と呼びます。
記事の内容
この記事は「第19章 複雑な環境での意思決定-強化学習」の「19.4 最初の強化学習アルゴリズムを実装する」で直面する課題の対処とグリッドワールド問題の楽しみ方に取り組みました。
具体的には次の3点を紹介します。
・【課題】OpenAI Gym のバージョン
・【実践】グリッドワールド問題の学習結果
・【娯楽】エージェントの行動をアニメ化
今回はGPU非搭載のパソコンを使いました。
19章のダイジェスト
19章では、強化学習に挑戦します。
強化学習の概念を伝えるのはかなり難しいです。
そこで先人の知恵を拝借して、わかりやすいサイトを紹介します!
興味のある方は是非ご参照ください。
テキストでは、まず、理論的概念を学びます。
マルコフ決定過程、エージェント・報酬、利得・ポリシー・価値関数、ベルマン方程式による動的計画法、モンテカルロ法、TD学習(SARSA/Q学習)を怒濤の数式で。
次に、OpenAI Gymツールキットを利用して、2つの実装を行います。
グリッドワールド問題(注1)をQ学習で解く
(注1)5行x6列のマス目の上でトラップを避けてゴールドを探すゲームCartPole-v1(注2)を深層Q学習(DQN)で解く
(注2)棒が倒れないようにバランスをとるゲーム
いざグリッドワールドへ
1. グリッドワールドの紹介
まずはグリッドワールドの地図をご覧ください。
グリッドワールドは5行×6列のマス目の単純な世界です。

ゲームのルール
紫の四角形■はゲームの主人公です。
強化学習ではこの主人公のことを「エージェント」と呼びます。
エージェントは1ステップで1マスずつ、上下左右に動きます。
ただし、エージェントには世界に置かれた⚫や▲が見えていません。
黄色の三角形▲はゴールド。
エージェントはゴールドを求めて行動します。
ゴールドのマスにたどり着くと+1の報酬を獲得できます。
黒丸⚫はトラップ。
トラップのマスは避けねばなりません。
トラップのマスにたどり着くと-1のマイナス報酬になってしまいます。
エージェントは左下隅の場所(図の■の場所)から行動をスタートします。
ゴールドかトラップのマスにたどり着くと1つのエピソードが終了して、報酬/マイナス報酬が確定します。
今回のQ学習では50エピソードの訓練をします。
2. 【課題】OpenAI Gym のバージョン
OpenAI Gymは強化学習モデルの開発に役立つ専用のツールキットです。
最新バージョンは 0.26.2 。
テキストは バージョン 0.20.0 を使っています。
利用環境のバージョンは 0.26.1 です。
そして、テキストの訳注に衝撃の記載があるのです。
[訳注]DiscreteEnvクラスは gym 0.22.0 で削除されたため、このコードは gym 0.22 以降では動作しない。
gymがバージョン0.22以降の場合、テキストの「リスト19-2」のグリッドワールド環境クラスが動かないため、テキストのコードのままではグリッドワールドを解くことができない、ということなのです。
この他にもバージョン違いで動かないコードがあります。
利用環境 gym 0.26.1 では、次のモジュールが読み込みできないためエラーになります。
・gym.envs.toy_textの discrete
・gym.envs.classic_control の rendering
選択肢1
テキストのコードを最新のgymのバージョンで動くように変更する。
これは調査時間がかなりかかると予想されるので、採用不可です。
選択肢2
condaでgymのバージョンを 0.20 にダウングレードする。
# condaコマンドでバージョンを指定してインストール
conda install -c conda-forge gym==0.20.0
実行結果イメージ
PackagesNotFoundError: The following packages are not available from current channels:
- gym==0.20.0condaのパッケージが conda-forge で見つからず、インストールを諦めました。
選択肢3(最終手段)
pipでgymのバージョンを 0.20 にダウングレードする。
# pipコマンドでバージョンを指定してインストール
pip install gym==0.20.0pipでバージョン 0.20.0 をインストールできました。
ただし、Anaconda環境の 0.26.1 は残したままなので、バージョンの異なるgymが共存(競合)する危うい状態になってしまいました。
この状態は一旦目をつむることにしましょう(気持ちの強化学習)。
3. 【実践】グリッドワールド問題の学習結果
スタートからエンド(ゴールドまたはトラップへの到達)までが1つのエピソードです。
今回のQ学習では50エピソードを実施しました。
機械学習では訓練の回数を「エポック」と呼ぶのに対して、「エピソード」と呼ぶのが強化学習っぽいのです。
コードの実行タイプ
今回は、Jupyter Notebook等の対話ツールを使わない工夫が必要そうです。
OpenAI Gymを使ってグリッドワールド環境を試してみる場合は、コードを対話形式で実行するのではなく、スクリプトエディタかIDEを使うことを強くお勧めする。
おそらく、テキストのサンプルコードで「エージェントの行動の画像を画面表示する」ときに、Jupyter Notebook等では対処が面倒なのだと思います。
最も単純は方法は、テキスト通りにコードを「.py」ファイルに記述して、コマンドプロンプトやシェルで「python ・・・.py」を実行することです。
私はVisual Studio Codeで「.py」ファイルを記述して、ターミナルで実行しました。
Visual Studio Codeのターミナルで実行する方法は、次のサイトで確認できます。
学習の推移
50エピソードの処理時間は 7分程度 です。
次の図は各エピソードの移動回数(# moves)と報酬獲得(Final rewards)の推移です。
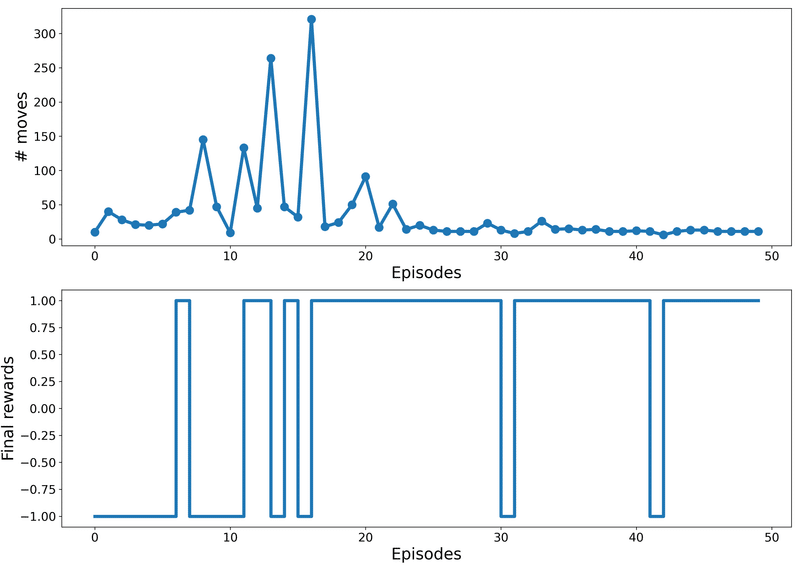
10エピソードあたりから、移動回数が急増して報酬1(ゴールド)を獲得できることが増え始めます。
ゴールドの場所を求めて試行錯誤を繰り返しているようです。
20エピソードを過ぎたあたりから、移動回数が少なくなってほぼ報酬1(ゴールド)を獲得できています。
ゴールドへの道筋を学習できたようです。
後半のエピソードで、ときどきゴールドに行き着かないのは、学習の偏りを防止するためのランダム性を取り入れているからです。
具体的には$${\boldsymbol{\epsilon}}$$-greedyポリシーによって、小さな確率$${\epsilon}$$でランダムに最適ではない行動を選択しています。
4. 【娯楽】エージェントの行動をアニメ化
主人公・エージェントの学習過程を可視化しましょう。
テキストのサンプルコードは、学習処理中にアニメを表示してくれるものの、処理後にはアニメを再生することができません。
そこで、学習中の各ステップの画像を保存して、gifアニメを作成することに取り組みます。
【謝辞 SpecialThanks】
次のサイトのお世話になりました。ありがとうございました!
◆環境を画像に描画する「render」の設定
◆「render」の画像描画コードのサンプル
◆画像ファイルからgifファイルを作成するコードのサンプル
学習中の各ステップの画像を保存する
テキストのサンプルコードに対して、2つ変更を行いました。
①画像保存処理の追加
テキストのサンプルコード「qlearning.py」の「run_qlearning」関数を次のように変更します。
「# 変更:画像保存」の箇所を追加しました。
renderの引数「mode='rgb_array'」を指定すると、画像を保存できます。
# テキストサンプルコード qlearning.py の抜粋
def run_qlearning(agent, env, num_episodes=50):
history = []
for episode in range (num_episodes):
state = env.reset()
env.render(mode='human')
final_reward, n_moves = 0.0, 0
while True:
action = agent.choose_action(state)
next_s, reward, done, _ = env.step(action)
agent._learn(Transition(state, action, reward, next_s, done))
env.render(mode='human', done=done)
# 変更:画像保存
rgb_array = env.render(mode='rgb_array', done=done)
Image.fromarray(rgb_array).save(
savepath + f"image/rgb_array_{episode}_{n_moves}.png")
state = next_s
n_moves += 1
if done:
break
final_reward = reward
history.append((n_moves, final_reward))
print(f'Episode {episode+1}: Reward {final_reward:.2} #Moves {n_moves}')
return history②画像保存フォルダの追加
テキストのサンプルコード「qlearning.py」のQ学習実行部に、画像保存フォルダsavepathを設定するように変更しました。
画像保存フォルダの設定は他の箇所に置いても良いと思います。
このコード変更では、学習履歴プロット画像の保存先、学習履歴データ(history)のcsvファイル保存先で使う「共通フォルダ」にしています。
# テキストサンプルコード qlearning.py の抜粋
if name == 'main':
# 画像保存フォルダの設定
# フォルダ区切りは"/"です。末尾にも"/"を付けます。
savepath = "./保存フォルダ名/"
num_episodes = 50 # 初期値 50
start_time = time.time()
env = GridWorldEnv(num_rows=5, num_cols=6)
agent = Agent(env)
history = run_qlearning(agent, env, num_episodes)
env.close()
print(f'Time: {(time.time() - start_time)/60:.2f} min')
# historyをcsvファイルに出力
with open(savepath + 'q-learning-history.csv', 'w') as f:
print('num_moves', 'final_rewards', sep=',', file=f)
for row in history:
print(*row, sep=',', file=f)
# Q学習の学習曲線の可視化
plot_learning_history(history)テキストのサンプルコード「qlearning.py」を実行して、各コマの画像ファイルを保存しましょう。
ファイル形式はpngです。
じつは、ときどき画像の欠けているステップがあるのですが、気づかないことにしておきましょう・・・。
ゴールド獲得後の次のエピソードの開始ステップが1つ欠けているみたいです・・・。
gifアニメを作成する
保存した画像は1800ファイル以上になります。
50エピソードをこなす中で、エージェントは累計1800回以上のステップで移動したのですね。
今回はアニメ化したいエピソードの画像ファイルを別のフォルダ(例えばanimeフォルダ)にコピーして、gifアニメファイルを作成しました。
gifアニメ化のサンプルコードは次のようになります。
# グリッドワールドの行動コマ画像からgifアニメを作成する
import glob
from PIL import Image
import matplotlib.pyplot as plt
import matplotlib.animation as animation
# 設定1:画像の格納フォルダ名の設定
folderName = './anime/'
# 画像の格納フォルダから画像ファイルのリストを取得
# 設定2:画像のファイル形式の設定(ここでは'png')
picList = glob.glob(folderName + '*.png')
ims = [] # 空のリスト作成
fig = plt.figure() # figオブジェクトの作成
plt.xticks([]); plt.yticks([])
# 画像ファイルをリストimsのに1枚ずつ読み込む処理
for i in range(len(picList)):
tmp = Image.open(picList[i])
ims.append([plt.imshow(tmp)])
# アニメーション作成処理
# 設定3:コマの間隔interval
ani = animation.ArtistAnimation(fig, ims, interval=100, repeat_delay=10000)
# アニメーション保存処理
# 設定4:ファイル名を設定(ここでは'anime.gif')
ani.save(folderName + 'anime.gif')matplotlibのanimation.ArtistAnimationを利用しています。
gifアニメのサンプル ~エージェント成長記録~
主人公・エージェントの成長過程をgifアニメで確認してみましょう。
①エピソード1~2
最初のエピソード1では 7 ステップ目でトラップを踏みました。
エピソード2では粘った末、 37 ステップ目でトラップを踏みました。
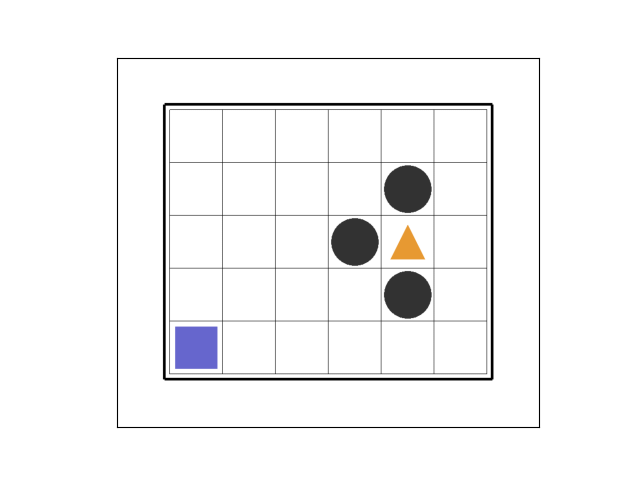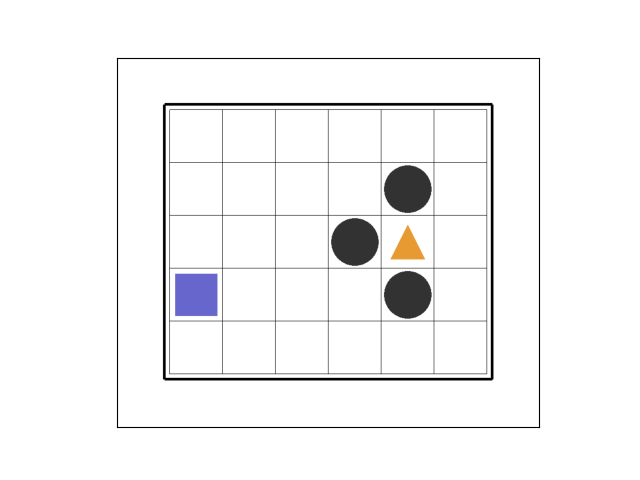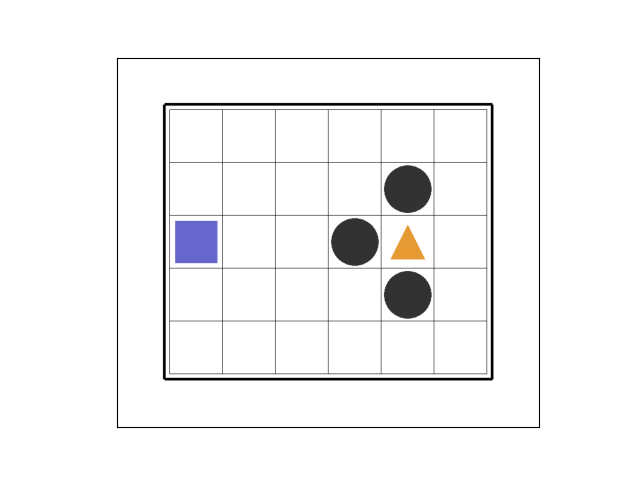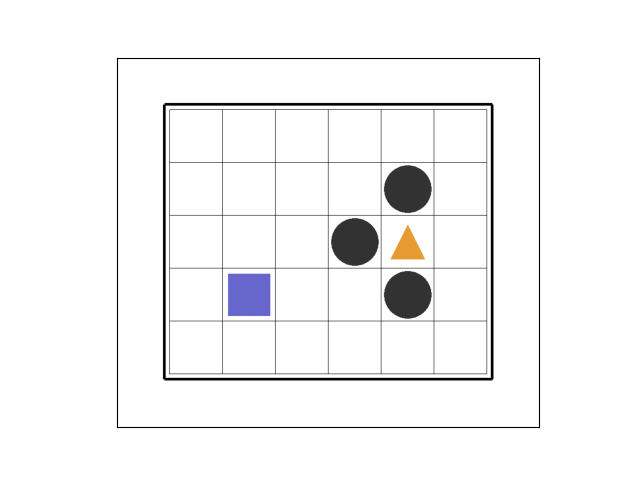
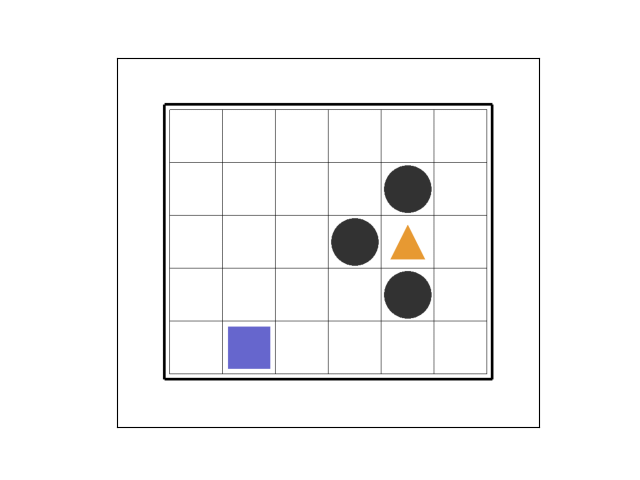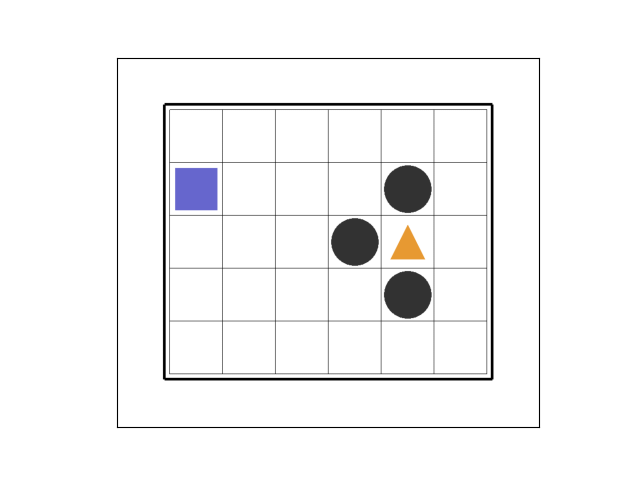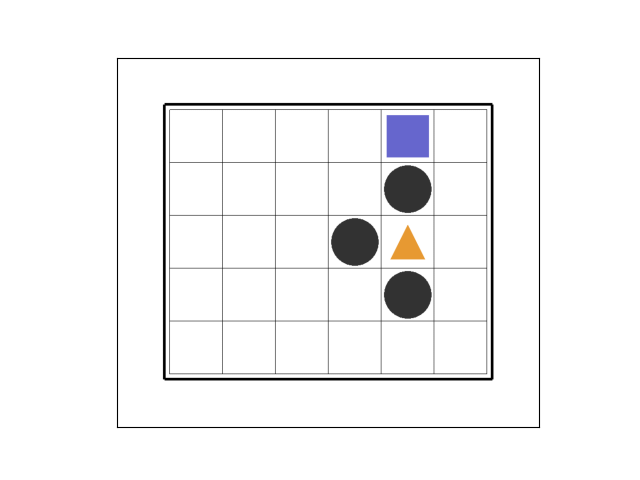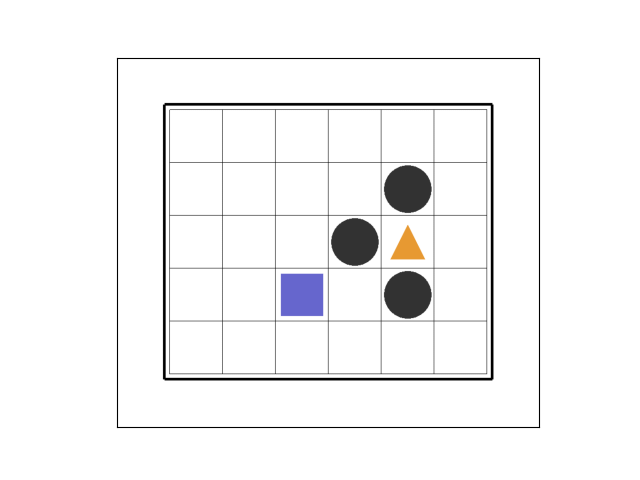
②エピソード12
263 ステップ目でゴールド獲得です。
トラップを避けつつ、ゴールドに至るルートを試行錯誤して、「コンピュータが自ら学習している」ようです。
③エピソード44~50
最後の7つのエピソードでは、短いルートでゴールドをGETできるようになりました。
学習によって、完全にゴールドにたどり着くルートを見つけたようです。
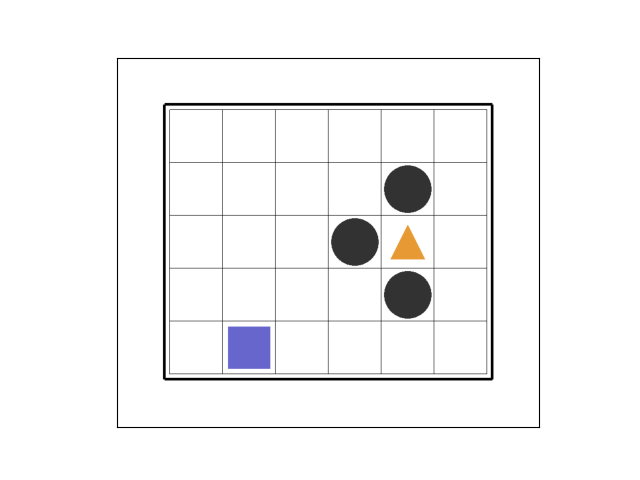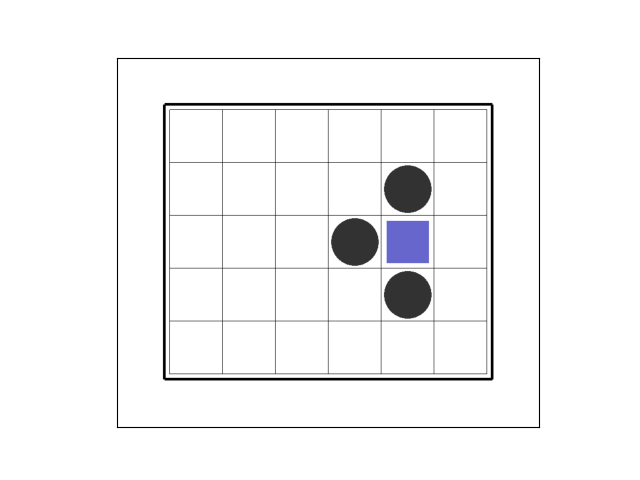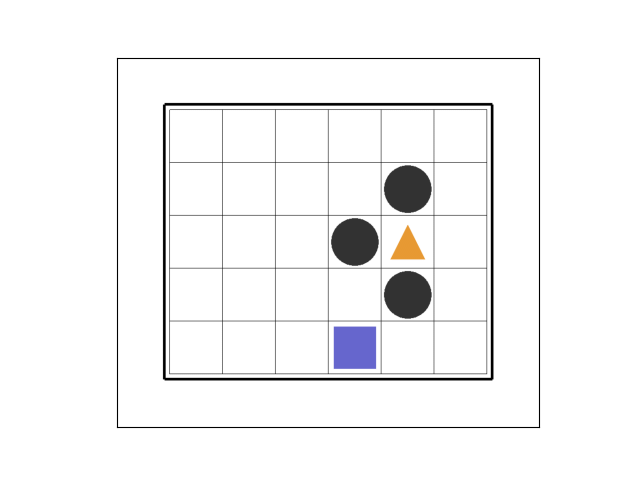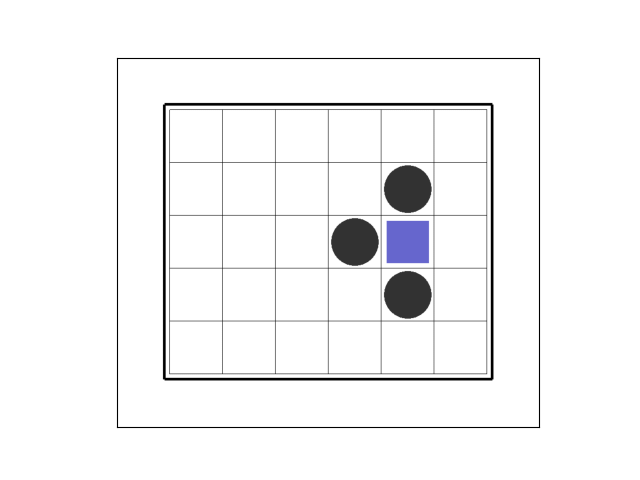
しかし、エージェントの動きをよく見ると、最短ルートではありません。
単なる憶測ですが、割引率(discount_factor)の値を大きくすると最短ルートを学習するかもしれません。
なお、強化学習の世界の割引率は、金融の世界の「1-割引率」です。
まとめ
今回は、OpenAI Gymを利用してグリッドワールド問題を解く「Q学習」に取り組みました。
今まで学んできた機械学習/深層学習と比べて、強化学習の理論には数学的裏付けのある特有のルールがあり、初めてテキストを読んだときにはハードルが高いと尻込みしてしまいました。
一方で、今回のgifアニメのように、学習過程をイメージしやすくする工夫ができます。
ひとまずPythonコードを動かしてみて強化学習に慣れることが大切なのだと思います。
First, don't think, Feel.
Practice makes perfect.
# 今日の一句
print('次回はPython機械学習プログラミングの最終回です!')楽しくPython機械学習プログラミングを学びましょう!
おまけ数式
noteでは数式記法を利用できます。
今回はベルマン方程式を紹介します。
$$
v_{\pi} (s) = \displaystyle \sum_{a \in \hat{A}} \pi (a \mid s)
\sum_{s^{\prime} \in \hat{S}, r \in \hat{R}} p(s^{\prime}, r \mid s, a)
[r+\gamma v_{\pi}(s^{\prime})]
$$
$${v_{\pi} (s)}$$はポリシー$${\pi}$$に従ったときの状態$${s}$$の価値関数です。
$${a}$$は行動、$${r}$$は報酬、$${s^{\prime}}$$は次の状態、$${\gamma}$$は割引率です。
$${\pi(a \mid s)}$$は条件付き確率を表しており、ポリシー$${\pi}$$は状態$${s}$$のときに行動$${a}$$を選択する確率です。
おわりに
AI・機械学習の学習でおすすめの書籍を紹介いたします。
「AI・データサイエンスのための 図解でわかる数学プログラミング」
ビジネスの現場では今後、数学的知識の必要度が高くなると言われています。
この書籍は、図解によって数学的な考え方を直感的に説明し、Pythonのコードを動かしてみて計算を体感することを目的に書かれています。
カバーする領域は、確率統計、機械学習、数理最適化、数値シミュレーション、深層学習です。
この書籍では、最適ルート探索問題、シフトスケーリング問題といった数理最適化と数値シミュレーションのネットワークモデルあたりでグラフ表現を利用しているようです。
ディープラーニング、Python、数学を一体として学習できるチャンスですね!
最後まで読んでくださり、ありがとうございました。
この記事が気に入ったらサポートをしてみませんか?