
Midjourney×ChatGPTでストーリーボードを作る方法

こんにちは。UXデザイナーのおかたくです。
今回はMidjourneyとChatGPTを使ってストーリーボードを作る方法をご紹介します。01でアイディアやそのストーリーを生み出す工程については本記事の対象外で、既に考えられた体験の流れの可視化が主となりますので予めご了承ください。
作業環境
ChatGPT
Midjourney(Discordのアプリ版)
作成手順
1. 主人公の準備
まず初めに、ストーリーボードの主人公となるキャラクターを準備します。事前に元となるキャラクターを作成し、それを各シーンで参照するとキャラクターのブレが少ないためおすすめです。
以下の型をベースにプロンプトを作成し、Midjourneyの /imagineコマンドで画像を生成します。人物の見た目だけでなく、様々な角度から数パターン描画されている画像を選びます。

▼ プロンプト例
A Japanese woman in her 20s, short brown hair, photography close up, character sheet, multiple expressions and poses --ar 16:9
次に出力された画像を保存し、切り抜きと背景透過処理をします。これは、各シーンで主人公の画像を参照する際に、余計な情報を反映させないようにするためです。背景透過はMacの場合、「プレビュー > ツール > 背景を削除」を使うのがおすすめです。

複数視点からの背景透過画像が準備できたら、MidjourneyのDiscordに画像をアップロードし、枚数分のリンクをコピーしておきます。これで主人公の準備は完了です。

2. 画像生成プロンプトの準備
ChatGPTにMidjourneyで画像生成するプロンプトを作成してもらいます。プロンプトは型に沿って作成し、シーンごとに修正を加えることで、変える箇所・変えない箇所が明確になります。これにより、画像を並べたときに一連の体験をイメージしやすくなります。
Midjourneyへの画像出力のプロンプトは以下の型に沿って作成します。「ストーリーボードのタイプ」を変えることで同じシーンでもガラッと印象が変わります。

型に沿ったプロンプトをChatGPTに出力してもらうため、型を学ばせます。学ばせると言っても以下のプロンプトをChatGPTに入力するだけです。
MidjourneyというAI画像ジェネレーターで、ストーリーボードのシーンを作成するための英語のプロンプトを書くのを手伝ってほしいです。 プロンプトの構成は、以下の要素のすべて、または一部が含まれます: [ストーリーボードのタイプ] ,[構図] ,[色とエフェクト] ,[キャラクター] ,[行為] ,[場所とモノ], [時間/時代] ,[感情/雰囲気] [Midjourneyパラメータ]。 「新しいプロンプトを開始する」と書くたびに、プロンプトをリセットして、これらの要素について段階的に尋ね(たとえば、「キャラクターについて記述して下さい」と指示する)、要素を追加して現在のプロンプトを表示し、次の要素について尋ねるようにして下さい。 要素を変更するように指示した際はプロンプトを調整して下さい。例えば、現在のプロンプトが 「Photorealistic, close-up, bright colors, a young Japanese man in his 20s, wearing a grey hoodie, sitting and looking at a PC, home desk, modern night, Concentrating --ar 16:9」で、 ストーリーボードのタイプを白黒写真に変更してくださいと指示した場合、プロンプトは 「Black and white photography, close-up, bright colors, a young Japanese man in his 20s, wearing a grey hoodie, sitting and looking at a PC, home desk, modern night, Concentrating --ar 16:9」として下さい。すべてのプロンプトで一貫性を保つために、プロンプトのストーリーボードのタイプ、構図、その他の全てのパラメータは、変更を指示するまで、指定した内容を維持するようにして下さい。 必要なパラメーターについて全て指示が集まったら、最終的なプロンプトをMidjourney用に英語で出力して下さい。ここまで理解ができたら、最初の質問から始めて下さい。
プロンプトを入力すると、型の各項目に対して質問を投げかけてくれるので、最初のシーンの情報を入力します。「スキップ」や一度入力したものの訂正も可能です。全ての項目の質問に答えるとプロンプトが出力されます。

3. 1シーン目の画像を生成
下記例のように「2. 画像生成プロンプトの準備」で出力したプロンプトの冒頭に、「1. 主人公の準備」で準備した複数視点の透過画像のリンクを加えます。
https://s.mj.run/2SmbIN0yJ60 https://s.mj.run/I6VKUPmm2qw https://s.mj.run/LyB3T9rXYuo Photography, wide shot. A young Japanese woman in her 20s, dressed in casual home clothes., sitting on a chair and looking at smartphone at bright ,simple residence. --ar 16:9
プロンプトが準備できたら/imagineコマンドで生成します。プロンプトを修正しながら理想に近づけます。
採用する画像が決まったら、Upscaleボタン(U1:左上,U2:右上,U3:左下,U4:右下)で画像を拡大し、メールマーク(envelope)のリアクションを付けます。これにより、MidjourneyBotから画像のseed値などが送られます。seed値は後ほど使うのでコピーして保管しておきます。
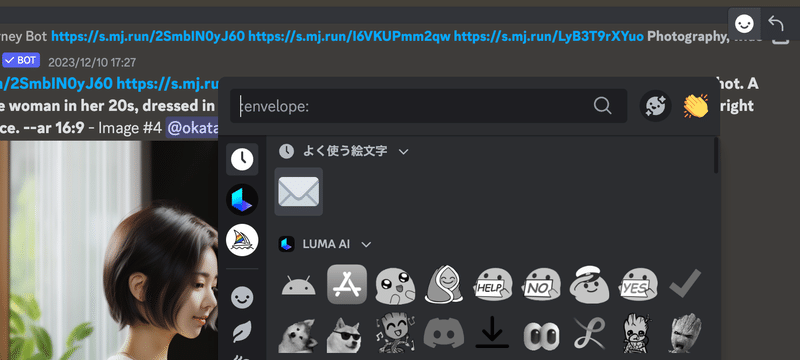
4. 2シーン目以降の画像を生成
続いて2シーン目の画像を生成します。「2. 画像生成プロンプトの準備」でプロンプトを作成したChatGPTで「新しいプロンプトを開始する」と入力し、2シーン目の画像条件を項目に沿って入力していきます。前のシーンとの変更箇所が少ない場合は、続きから修正を指示してプロンプトを生成することもできます。
また、2シーン目以降は前のシーンの人物を参照することで、より一貫性を持たせることができます。1シーン目で採用した画像に対して、切り抜きと背景透過処理をします。

背景透過した画像はDiscordにアップロードし、リンクを取得します。取得したリンクは以下のプロンプトのように冒頭に追加します。また、プロンプトの末尾には「3. 1シーン目の画像を生成」で取得したシード値を追加します。記述の仕方は「--seed シード値」です。
https://s.mj.run/2SmbIN0yJ60 https://s.mj.run/I6VKUPmm2qw https://s.mj.run/LyB3T9rXYuo https://s.mj.run/KtEZuLLgjXY Photography, medium shot. A young Japanese woman in her 20s, dressed in casual attire, receiving a mobile Wi-Fi from a female receptionist at an airport reception desk, looking into the receptionist's eyes. Curious, traveling. --ar 16:9 --seed 380137636
以下が2シーン目の画像です。1シーン目の画像が参照され、髪型や顔立ちに一貫性があるのが分かります。

3シーン目以降も同じ手順です。ChatGPTでプロンプトを変更し、前シーンの画像の透過画像を参照してプロンプトを作っていきます。
https://s.mj.run/2SmbIN0yJ60 https://s.mj.run/I6VKUPmm2qw https://s.mj.run/LyB3T9rXYuo https://s.mj.run/KtEZuLLgjXY https://s.mj.run/fmb0TlsubkQ Photography, medium shot. A young Japanese woman in her 20s, dressed in casual attire, sitting in her seat on an airplane. Excited, traveling. --ar 16:9 --seed 380137636

3シーン目以降は前シーンの画像を参照せずとも一貫性は見えるので、出力画像を見ながら判断するようにします。
https://s.mj.run/2SmbIN0yJ60 https://s.mj.run/I6VKUPmm2qw https://s.mj.run/LyB3T9rXYuo https://s.mj.run/KtEZuLLgjXY https://s.mj.run/fmb0TlsubkQ Photography, medium shot. A young Japanese woman in her 20s, dressed in casual attire, walking while looking around the picturesque streets of Paris, holding a smartphone in her hand. Excited, traveling. --ar 16:9 --seed 380137636

当然人が登場しないシーンでは、前シーンの人画像を参照する必要はありません。ただし、全体の画に一貫性を持たせるため、[ストーリーボードのタイプ]などは理由がない限り変えないようにします。
Photography. Close-up shot. Inside a hotel room, there is a small mobile Wifi device with an illuminated display showing communication information. The scene exudes a calm atmosphere. --ar 16:9

最後のシーンでは返却のポストのようなモノが欲しかったため、先頭に記述しています。肌感ですがプロンプトが長くなる場合、優先したい指示は初めの方に書いた方が反映されやすいです。
Return post for rental devices inside an airport., https://s.mj.run/2SmbIN0yJ60 https://s.mj.run/I6VKUPmm2qw https://s.mj.run/LyB3T9rXYuo https://s.mj.run/KtEZuLLgjXY https://s.mj.run/LfoB3f_eICg Return post for rental devices inside an airport., Photography, medium shot. A young Japanese woman in her 20s, dressed in casual attire, returning a thick, white mobile Wi-Fi device at an airport's return post. Curious, traveling. Morning. --ar 16:9

5. 完成
一連の体験を表現する6枚の画像が出力できました。少々雑ですが、体験の説明を加えて完成したストーリーボードがこちらです 。今回は海外旅行用のレンタルWifiを例としてストーリーボードを作成しました。

まとめ
いかがだったでしょうか。なかなか思い通りにいかないこともあったのではないかと思います。自分も正直苦労しました。ただ、今回ご紹介した生成の仕方をベースに、とにかく画像を生成しまくると徐々に勝手が分かってきたような気がします。皆さんもぜひ色々と試して理想のストーリーボードを作ってみて下さい!
この記事が気に入ったらサポートをしてみませんか?