
ある夏のFirestoreのこわい話

すでに夏の終わりも近づいてきていますが、いかがお過ごしでしょうか!
どうもお久しぶりの投稿です、ユートニック テックリードの衛藤です。
今回はCloud Firestoreにまつわる怖い話・・・
と言っても結局は自分の実装で初歩的ポカをやっていただけという話なのですが、発覚した経緯も含めて赤裸々に書きたいと思います!
Cloud Firestoreについて
僕の最初の投稿でも触れた通り、ユートニックのバックエンドのDBレイヤーはCloud Firestoreを使っています。
簡単に特徴についてだけ記載しておきます。
Cloud Firestoreの特徴
これまでCloud Firestoreを数年使ってきてましたが、改めてメリットデメリットをまとめるとこんな感じになります。
メリット
リアルタイム同期、スナップショットリスナーによるドキュメントフック処理の簡潔さ
強整合性担保でかつマルチリージョンサポート・柔軟なスケーリング、しかも可用性five-ninesというモンスター級の安定性を実現(←これすごい)
Cloud FunctionsやBigQueryなどの他GCP製品との簡単に連携
弊社では使ってないけど、オフラインサポート、モバイルアプリとの親和性
デメリット
テーブルのjoinができないため、非正規化しないと辛い
DocumentID設計をミスってホットスポットにハマるとパフォーマンス劣化
検索クエリの制限がやや厳しめ(徐々に緩和されつつある)
気がつくとreadが大量に ←今回の話
SQLでもNoSQLでもそれぞれメリデメはあると思うので、実際の用途に適したものを選べば良いかなと思います。
Cloud Firestoreの料金体系
Cloud Firestoreの料金は、ドキュメント読み取り数、書き込み数、削除数、DBストレージ、ネットワーク帯域使用量、で課金されます。
逆に言うとそれだけで、例えば垂直スケーリングによるスペック料金等を気にする必要がないのもフルマネージドならではのメリットかと思います。
料金表にもある通り、ドキュメント読み取りの場合無料枠は1日あたり50,000 readsまで無料、超過分は $0.06/100,000 reads となっています。
今回の話はこのreadがめちゃくちゃ増えて、気がついたら料金が増えていたという話です。
事の発端から修正までの道のり
試しにKey Visualizer見てみようと思ったのが始まり
Firestoreのrelease noteにて、Key Visualizerでインデックスキーのheatmapが見れるよとのアナウンスがあり、そういえばその前にリリースされたドキュメントheatmapの方も、改めてしっかり見たことなかったな・・・というのが始まりです。
Key Visualizerというのは、Firestoreの使用状況、データへのアクセスの集中具合をheatmap的に視覚化し、改善やパフォーマンス問題の特定を行うためのツールです。
Firstoreの特性上、データはDocumentIDに従ってクラスタリングされストアされますが、そのため、辞書的に近いIDや単調増加するようなID設計をしてしまうと、単一クラスターにアクセスが集中してしまい、性能劣化、いわゆるホットスポットを引き起こしてしまいます。(今回の劣化は別件です)
Key Visualizerはそのホットスポットが生じているかどうか、また効果的にFirestoreを使えているか、そのあたりのトラブルシューティングに役立てることが出来ます。
といってもそこまで使いこなせておりませんが…
※ 上記の画像はGoogleの公式ドキュメントにあった画像です。
む、なんかheatmap見てると秒間単位のread数が跳ね上がっている箇所が・・・
そして試しに今の本番プロジェクトで見てみると、秒間単位ですさまじい量のreadが発生しているタイミングがチラホラとありました。
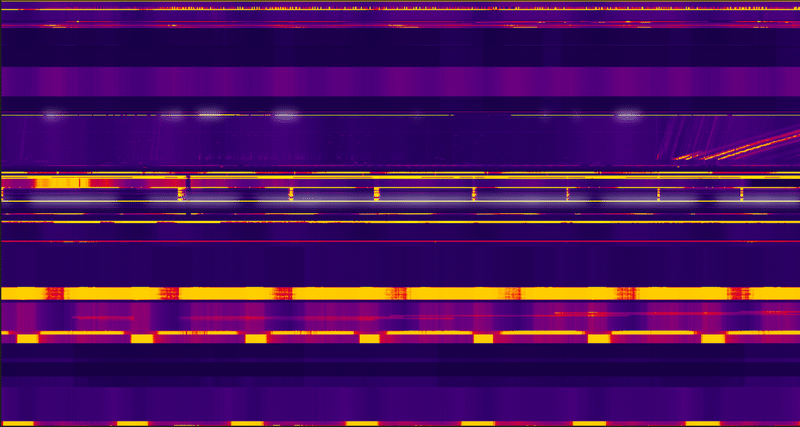
本番環境の分析データは載せられませんが、開発環境のKey Visualizerでも見てみたところ、以下のような表示となっていました。

公式Docのサンプルまで細かくは出ていませんが、画面上の白っぽく明るい部分がアクセス集中している箇所です。
試しに明るいところをクリックすると、開発環境で7.15k req/sec(!?)と出ています。分間だと万単位の読み取りが発生しています。
開発環境はエンジニア数名でのみ触っているもので、ここまでアクセスが発生するのは変です。
本番環境でも、そこまでアクセス過多になる時期でもありません。ユートニックのビジネス特性上、アーティストのイベント開始時などはアクセス集中することがありますが、ここまで多いはずはない・・・怖い・・・
これは絶対なにかあるはず・・・!?
Metrics Exploreでも同様にQueryが非常に多い
念のためMetrics ExploreのFirestore read数も見てみると、確かにreadが跳ね上がってます。(画像は開発環境です)
しかもQueryだけ跳ね上がってるので、明らかに何かしらの実装ミスが予想されます。

試しにアプリで使っているAPIを直実行してグラフが跳ねるか見てみると、たしかにその瞬間跳ね上がるのを確認できました。その時間帯に利用していたのは僕だけなので、ほぼ確定です。
原因の絞り込み
ユートニックでは、GraphQL APIを利用していて、その中でも一番大きなクエリで跳ね上がりが確認出来たため、少しづつクエリを分解し実装を見ていきました。
そしてついに・・・
!!!
// note用に多少コードいじっています
async findLatest() {
const snap = await getFirestore()
.collection('some-collection')
.orderBy('createdAt', 'desc')
.get()
if (snap.empty) return null
return snap.docs[0].data()
}何か書き忘れています・・・お分かりでしょうか・・・
そうです、なんと、あのときの僕はlimitをかけ忘れているではありませんか・・・
本来は、最新の1件のみ取得できれば良いので、1行だけ書き足してこうするべきなのです。
// note用に多少コードいじっています
async findLatest() {
const snap = await getFirestore()
.collection('some-collection')
.orderBy('createdAt', 'desc')
.limit(1) // ← これ!!!!
.get()
if (snap.empty) return null
return snap.docs[0].data()
}collectionに対してlimitかけずに get() してしまうことで、コレクション内のドキュメント(開発環境だと数千レコード)がすべて read されてしまっていたのです。結果は配列の先頭のみ返すので、1件だけで良かったのに、毎回毎回ユーザーがアクセスするたびに数千件を引っ張り出して、最初の1件だけ返していたことが判明しました。
人間どんな過ちを犯すかわからないものです。常に自分を疑っていきましょう。
おまけ
ちなみに余談ですが、最近FirestoreにAggregation Queryというものが登場し、もしドキュメントの数を数えたいだけなら count() を使うとより read 数が削減されます。(インデックスのエントリ1000個ごとに1回のreadとしてカウント)
これならドキュメントをすべてreadしてsizeを見なくても済みます。
// 良い例
async getDocCountVeryGood() {
const snap = await getFirestore()
.collection('some-collection')
.count()
.get()
return snap.data().count
}
// 悪い例
async getDocCountVeryBad() {
const snap = await getFirestore()
.collection('some-collection')
.get()
return snap.size
}修正リリース後の数値関連
以下、修正リリース後のMetrics ExploreでFirestore readを計測した結果です。青い縦ラインがデプロイ時間で、このラインを区切りにかなり落ち着いていることが確認できます。
なお、ピンク色の乱高下しているのがQueryで読み取っている分間 read 数です。
まだ若干跳ねているところはあるので、まだまだチューニングする余地はありそうですが、ひとまずといったところでしょう。

念のためKey VisualizerのBefore/Afterも比較してみます。修正する1日前と当日の同時間帯で確認しました。
画像は開発環境ですが、本番環境でも同様に明らかに明るい部分が減っており、無事readを減らすことが出来ているようです。


本番環境の分析画像は残念ながら載せられませんが、コスト面で約6%、パフォーマンスは20%ほど改善されました!
いかに無駄なクエリを書いてしまっていたかが悔やまれます!
今後も定期的なパフォーマンス問題に取り組んで行きたいところです。
最後まで読んで頂きありがとうございました!ではまた!
この記事が気に入ったらサポートをしてみませんか?