
意味のあるA/Bテストを実行するための設計についての考え方

ランディングページ (LP) の改善運用を担当することがあるけど、正直、統計とか有意差とかよくわからないよという人に向けて、A/Bテストで必要なサンプルサイズの設計方法の考え方についてやわらかく説明したいと思います。
#1. はじめに
・ A/Bテストとは、異なる複数のページを均等に表示させて、一定期間の集計データをもとに「どのパターンがもっとも効果が高いのか」を判定するためのテストです(※1)。CVアップなどサービスの改善を目的に実施されることが多いと思います。
・ ここでは、"テストを実施したものの有意差が出なかったため、何もインサイトを発見できなかった" という事態の観測を避けたい思いから、A/Bテストを行う際の、仮説の作り方と、必要なサンプルサイズの設計方法の考え方についてやわらかく説明します。
なお、超入門編として、"正直統計とか有意差とかよくわからないよ"という人向けのやわらかい説明となりますので、初学者としてしっかり学ばれたい方は、サンプルサイズの決め方 (統計ライブラリー)や統計学入門 (基礎統計学Ⅰ)を読まれることをお勧めします。
※1 基本的に、ターゲットは均質で、流入させる条件が同じ状態で検証を行うことが前提となります。今回は、同時期/同期間に行う異なるページの検証を想定します。
* * *
#2. 仮説を立てよう
仮説検証とは、調査を通じて、その仮説の真偽を確かめることです。
A/Bテストでは、「既存のデザインよりも、新しいデザインの方がより新規ユーザーを獲得できる」というようなものが仮説となります。
現場の仮説検証は、大きく、① 現状分析、② 仮設設定、③ 仮説検証、の3つのプロセスの繰り返しの中で行われるものと解釈できるので、それぞれ説明したいと思います。
① 現状分析
まず、施策やサービスについて、現状のコンディションを確認し、深掘り分析をします。例えば、チャネル別のユーザー数とCV、リンク別のCT等を分析すれば、最も打ち手を講じるべきポイントが見えてくることかと思います。打ち手を講じるべきポイントが既存のLPだ(しかも伸び代があるのである)と定めたならば、次は仮説を設定します。
② 仮説設定
仮説設定では、①の現状分析で確認した事実を基に、「もっとこうすれば数字が上がる」だろうというような、確からしそうな仮の答え(仮説)を設定します。分析結果から、「AデザインのLPのCVが芳しくない(想定よりも低い)」という事実を把握したとした場合には、例えば、「BデザインのLPは、AデザインのLPよりもCVが高い(※2)」というような仮説を立てることができます。
※2 実際に、テストを実施する場合には、事前にサンプルサイズを設計する必要がありますので、より具体的に、どれくらいCVが高くなるのか、過去の類似実績から見込みを出し、仮説を設定することになります。このあたりは後ほど説明することにします。
③ 仮説検証
仮説を設定したら、仮説の真偽を確かめるために、A/Bテストを実施して、その結果を分析・検証します。仮説が正しければ更なる改善に向けて新たな仮説を設定するか、この課題の他に優先度の高い課題に取り組むこととなると思いますし、仮説が正しくなければ、その仮説を修正して、再度調査を実施して、その結果を分析・検証する、という繰り返しが基本となるでしょう。
(´・ω・`).oO(個人的には、①のところで、現状分析から課題を整理し、打ち手を打つポイントを決め、仮説を設定する部分がとても重要だと思っています......。)
* * *
#3. サンプルサイズを設計しよう
A/Bテストを実施する前に、検出したい差分(効果量)からサンプルサイズ(≠サンプル数)を算出します。
サンプルサイズの設計には「有意水準」「検出力(※3)」「効果量」の値が必要です。「有意水準」は0.05もしくは0.01が用いられることが多く、「検出力」は通常0.8に設定されます。これはサイエンス界の常識的なお話なので、そういうものだと思って、「有意水準」の方は0.05とすれば良いと思っておくと良いかと思います。よって、実務では、実際にこのテストに合わせて算出する必要があるのは「効果量」のみと考えて良いでしょう。
「効果量」は「検出したい差の程度」のことで、A/Bテストの効果を見るための指標ですので、LPのA/Bテストでは、CVがそれに該当すると考えると良いと思います。
※3 検出力は、ふわっと説明すると、後述する帰無仮説を正しく棄却する確率で、効果量が大きいほど大きくなり、サンプルサイズが大きいほど(分布のばらつきが小さくなるため) 大きくなる関係にあります。
「効果量」は、過去の実績データ等から見込みを出します。同じ「検出力」を得る場合、「効果量」が大きい場合にはサンプルサイズは小さくてよく、一方で、「効果量」が小さい場合にはサンプルサイズは大きくする必要がありますので、確からしい「効果量」の見込みがあると嬉しいのですが、過去の実績データに見込みとして相応しいものがない場合もあると思います。その場合には、実績をためるためにも、出来るだけ正確に細かく効果を見たいとなると思いますので、売上などの数字が下がるリスクを十分に考慮しつつ、出来るだけ多くのサンプルサイズを確保すると良いでしょう。
さて、仮説検証を行うために、仮説検定にてA/Bテストを実施することを考えましょう。今、KPIを「購入する/購入しない (1,0で表現できる)」とできるCVRであるとすると、A/BテストのA(コントロール)とB(テストケース)を
・A:CVR 2%のAデザインのLP
・B:CVR 5%を期待するBデザインのLP
とすることができそうです。
「BはAよりもCVRが3%高い」という仮説を検証する(※4)ためには、A/Bテストを実施し、その結果が判断できるに値する(有意差の出る)サンプルサイズを算出することが重要です。
※4 この時使用される検定手法は、χ2検定、二項検定、t検定というものが主なものとなりますが、Web系のデータについては、A/Bテストにかけられるデータのサンプルサイズが十分に大きいことを暗に仮定していることになるので、これらのうちどの検定手法を用いてもほぼ同じ結果(有意か否か)を返すことが期待され、現場でのA/Bテスト結果の判断においてはほぼ問題ないと一旦考える事にしたいと思います。(検定方法によって、使うのに適したケースがそれぞれあり、それについては、気になる事象をいくつか観測しているので、また別の機会にこのnoteのように呟きたいと思います。)
サンプルサイズを算出するためには、統計的理解に基づいて、一般的にα(有意水準)やβ(1-β:検出力)とされる確率や分布を設定して、ExcelやらRやらPythonやらを用いてサンプルサイズを計算するのですが、ここではより現場向きに、A/Bテストを推進する立場の方が、有意差がちゃんと出るA/Bテストを実施できることを目的に、下記のような便利ツールを用いた場合について記載したいと思います。

Study Group Design は 、基本的には"Two independent study groups"にします。2つのターゲットユーザーが同等規模で独立に(他に影響されずに)振る舞うというようなことを意味します。
Primary Endpointは、「購入する/購入しない (1,0で表現できる)」で考えるので、 "Dichotomous"とします。
Statistical Parametersは、Anticipated Incidenceについて、Group1のところに、コントロールの平均CVRを、Group2のところに、テストケースに期待するCVRを入れます。Enrollment ratioのところはサンプル数の比率のことを表しているので、基本的には1(ターゲット数が同等)で大丈夫です。
Type I/II Error Rateについて、Alpha(α)は、一般的に5% (0.05) とすることが多く、Power (検出力) は一般的に80% (0.8) とすることが多いので、まずはそのように設定しておくと良いと思います。
最後に、「Calculate」を押せば、サンプルサイズを算出することができます。
Alpha(α)について簡単に補足しておきたいと思います。
有意水準は一般的にαで表され、「差がないということが真実なのにも関わらず、差があると結論づけてしまう」確率のことを指します。有意水準が5%であるということは、「5%以下の確率で生じる事象は、100回に5回以下しか起こらない事象である。この極めて珍しいことが起こったということは、何らかの意味があることである(=有意である)。」と解釈できます。
〜「仮説で確かめたかったことと逆じゃない?」と思ったら〜
仮説検証と仮説検定は異なるのです...。仮説検定で、帰無仮説というものを棄却することで、仮説の検証が行われます。今、証明したい仮説は、「BはAよりもCVRが高い」でした。このとき、帰無仮説は、「BとAにはCVRの差異を決定づけるほどの明らかな差がない」となります。この帰無仮説が
「滅多に生じないことである」と言うことができれば(帰無仮説を棄却)、帰無仮説が誤りであった可能性が極めて高い、つまり、
証明したい仮説が正しい可能性が極めて高い、つまり、
BはAよりも効果がある可能性が極めて高い、
と言うことができるのです。
* αやβについて分かりやすい図が、Data Science Study Protocols for Investigating Lifetime and Degradation of PV Technology Systemsにあったので、参考に以下に転載しておきます。
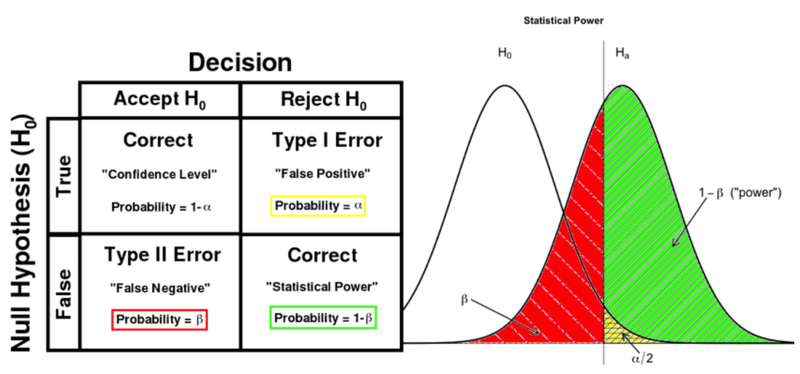
* * *
# 4. なぜテスト前のサンプルサイズ設計が必要か
さて、なぜテスト前にサンプルサイズを決めなければならないのか、考えてみることにします。
上述しましたが、サンプルサイズが大きくなれば大きくなるほど、推定の精度はどんどん上がっていきます(平均の推定量の母分散が小さくなるので、推定量は真の値に近い値を取る確率が高くなります)。しかし、実際には、仮説検定で使うサンプルサイズは大きすぎない方が良いです。サンプルサイズをいくらでも大きくできるのであれば、どんな仮説検定でも棄却できてしまう(有意差が出てどちらが良いか分かった!と言えてしまう)からです。
サンプルサイズを事前に決めておらず有意差が出た場合、
「① 各パターンの結果(群間)の差が大きかったために有意差が出た(※5)場合」
「② サンプルサイズが大きかったために有意差が出た場合」
の2つの可能性が考えられてしまいます。
私たちが確かめたいのは、「① 各パターンの結果(群間)の差が大きかったために有意差が出た場合」です。サンプルサイズを事前に決めないと、各パターンの結果に差がほとんどないのに、サンプルサイズが大きかったために有意差が出てしまう場合(②の場合)が生じるのです。
※5 p値が小さい場合を指します。(p値の小ささの基準が有意水準αです)
この問題を現場に当てはめてみると、あまり良い例ではありませんが、「AとBには大した差がないのに、Bのテストケースよりも、Aのコントロールケースの方がCVRが高い結果だったと誤った判断がされ、Aが全面的に採用された。しかし、定性的なUX検証結果では、Bの方が圧倒的に好結果で品質の良いものであった......」というようなことが考えられます。
また、サンプルサイズが大きすぎる場合には、小数点以下単位の小さい差異まで有意差を見ることができます(統計的に有意になりやすい)が、その期間の数字 (e.g. 売上) が下がってしまうリスクがあります。
逆に、サンプルサイズが小さすぎる場合には、得られた結果がサンプルサイズの小ささに起因するものか、テストそのものに起因するものなのかが分からなくなってしまいます。サンプルサイズが小さすぎると、本来は差が検出できるはずなのに、その差が検出できずテスト自体に意味がなくなってしまい貴重な時間を無駄にしてしまうかもしれません。
ですので、テストは、適切なサンプルサイズに対して行う必要があり、そのテストが与える数字の責任者と連携して都度判断していくことが必要だと思います。
* * *
# 5. 実務上、押さえておきたいポイント
最後に、実務でA/Bテストを実施するときに気をつけたいポイントを2つメモしておきたいと思います。
## テスト期間の試算
A/Bテスト実施前に、どのくらいの期間テストを実施すべきか試算してみると良いと思います。impsは一定の期間でこれくらい確保できそうだというのが、過去の実績から大凡試算できるはずです。それに基づいて、いつ頃までにテスト結果が出るか見当をつけることで、無駄なテスト日数を重ねることなく、効率的に改善を行えるはずです。
想定した期間が終了する前に、一般公開されているツールを使って簡易的に状況を確認するのも大事でしょう。ここではイギリスの超有名マーケターNEILPATELが提供しているツールを例に紹介しておきます。
また、本来ならば避けたい自体ですが、想定の期間を過ぎても有意差がつかなかった場合に備えて、テストを強制終了する期間の決めを事前にすり合わせておくことも、改善スピードの観点からは重要でしょう。
## 等質なターゲット
A/Bテスト実施の際には、例えばLPの表示を、Aデザイン(既存ページ)とBデザインで、ランダムに半分ずつ振り分けることが通常だと思いますが、技術上可能であれば、等質・均質になるように振り分けを実施できるとベターです。例えば、既存ページでの既存CVユーザー/CVしなかったユーザーが含まれると、既存ページの評価に有利/不利に働いてしまうからです。
* * *
# 6. さいごに
本記事では、A/Bテストにおける仮説設定の方法、およびサンプルサイズ設計の方法についての考え方を、ふわっとやわらかく説明しました。
なお、本投稿は、現在IT企業で働いている筆者が、A/Bテストを実施するも有意差が出ないために結論を出すことができない、つまり、有意義なテストとならなかった、さらに言えば、何のインサイトも得られない無駄な時間を過ごしてしまった、となってしまう事態を多く観測し、また、あまりに多くの人が開き直っていることを残念に感じたことをきっかけに、統計的な深い理解がなくとも、有意義なテストを実施できるよう、できるだけ簡単な言葉で説明メモを記載したものです。世の中には分かりやすいサイトや書籍がたくさんあるのですが、みんなそれらを読んで理解しようとするわけではないですし、"数式を使わないで説明してほしい" と会社のお兄さんとお姉さんに教えて頂いたことが契機となっています。
最近、他にも、"t検定で有意差が出なかったから、母比率検定でやって有意差を出しました (?) "、"(t検定の)ツールで有意差が出なかったので、ベイズ?のツールで確かめたら有意差が出ました (?) " な事態をよく観測して気になっているので、また追記事できたらと思っています。
最後に、筆者は学生の時に統計を少し学び現在は自己学習をしている身で、統計の専門家ではありません。出来るだけ誤りのないよう調べながらこの記事を作成しましたが、私の未熟さにより誤りがありましたら教えて頂けますと幸いです。
参考書籍・参考サイト
この記事が気に入ったらサポートをしてみませんか?