すぐに仕事で活かせるAI講座 第三部 その2

ここで勘のいい人ならわかると思います。
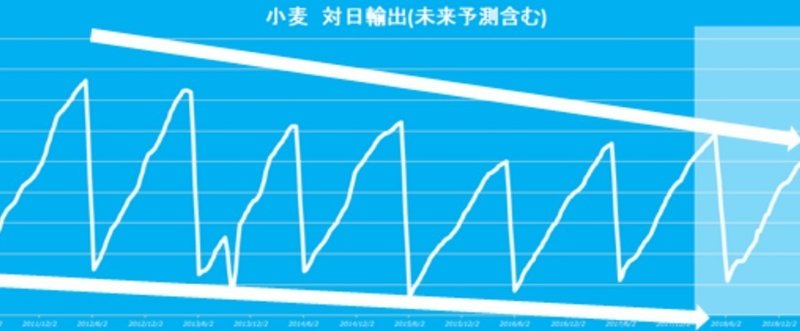
2011年をピークに、明らかに減っています。
「シンゾー、今年もさらに減らすのか!」とまあ、トランプ大統領でも怒るのは無理ない(笑)
(アメリカにも圧力団体というのは当然あって、小麦を扱う農業団体は、アメリカでも大変強力な圧力団体の一つなのです)
次は、予測モデルを描く
データをひとかたまりとしてみると、6月が最小値(スタート地点としましょう)で、毎月輸出量が一定に、つまり直線的に上昇していき、翌年の5月がピーク地点(ゴール地点としましょう)となり6月に向けて直線的に下向しそう、とだいたい言えます。
これが、データを簡易に扱うためのストーリー、いわゆる"モデル" というものです。完璧に正確でなくてもかまいません。(データ サイエンティストの説明では、上記の直線がモデルとなります)
現実的には、"ノイズ" つまりこの直線に上下した値が ばらばら="分散" して存在している ことになります。
仕事では、基本になる理想的な関係(=直線)が存在すると想定して、その直線周りに、ノイズや不確実性を含むバラバラ、分散した実際のデータがある、と考えてください。
"基本になる理想的な関係からどの程度、バラバラ、つまり分散したデータがあるか" を、データ サイエンティストは、これを"回帰" といっています。
また、基本になる理想的な関係が直線であるため、データ サイエンティストは、これを"線形回帰"といっています。基本的には、まずこの2つだけでも覚えてください。
予測モデルを使用して未来を予測してみる
データをひとかたまりとしてみると、だいたい以下のことが言える、と思います(これが予測モデル)。
1.全体:6月が最小値(スタート地点)で、毎月輸出量が直線的に上昇していき、翌年の5月1週目がピーク地点(ゴール地点)となり6月に向けて急速に減る
2.最小値(スタート地点):、毎年凸凹ありながらも、相対的には2011年を最高値として減っている(平均するとー2.8%程度)
3.ピーク地点(ゴール地点):毎年凸凹ありながらも、相対的には2011年を最高値として減っている(平均するとー5.2%程度)
4.全体:毎年凸凹ありながらも、相対的には2011年を最高値として減っている(平均するとー2.4%程度)
上記の条件を入手したデータに当てはめると、“だいたい”上記の図のようになります。
よろしければサポートよろしくお願いします。いただいたサポートは、日中韓とアメリカのリアルタイム感情分析を進めるために使わせていただきます