
ざっくり理解するFine-tuning【ファインチューニング】【ChatGPT】

Fine-tuningとは?
「Fine-tuning」とは、文字通り「微調整」という意味を持ちますが、AIの世界では特定の意味を持つ重要なプロセスを指します。AIモデルは、元々大量のデータを学習して作られます。この初期学習を「事前学習」と言います。しかし、この事前学習だけでは、特定のタスクや用途に完全に適応することは難しいことが多いです。そこで、Fine-tuningというステップが登場します。
GPTモデルのカスタマイズ
GPTモデルは、OpenAIが開発した大規模なAIモデルの一つで、特に自然言語処理のタスクに優れています。このモデルは、インターネット上のテキストデータを数多く学習しています。しかし、特定の業界や分野の知識を持たせたい場合、または特定のスタイルやトーンで文章を生成させたい場合、Fine-tuningを行うことで、そのような特性を持ったモデルを作成することができます。
主な利点
Fine-tuningの利点は数多くあります。まず、特定のタスクや用途に特化したモデルを作成できること。これにより、一般的なモデルよりも高い精度や効果性を持ったモデルを得ることができます。また、Fine-tuningを行うことで、モデルが持っている不要な情報を取り除き、必要な情報のみを強化することができます。これにより、モデルの反応速度や効率が向上することも期待できます。
どのモデルをFine-tuningできるのか?
AIの世界にはさまざまなモデルが存在しますが、すべてのモデルがFine-tuningに適しているわけではありません。特に、Fine-tuningが推奨されるのは、大規模なモデルや高い汎用性を持つモデルです。
対応するモデルの一覧
Fine-tuningが可能なモデルとしては、gpt-3.5-turboやbabbage-002、davinci-002などが挙げられます。これらのモデルは、それぞれ異なる特性や能力を持っており、用途や目的に応じて選択することが大切です。例えば、gpt-3.5-turboは、高速な反応と高品質な結果を求める場合に特に適しています。一方、davinci-002は、より複雑なタスクや高度な分析を求める場合に有効です。
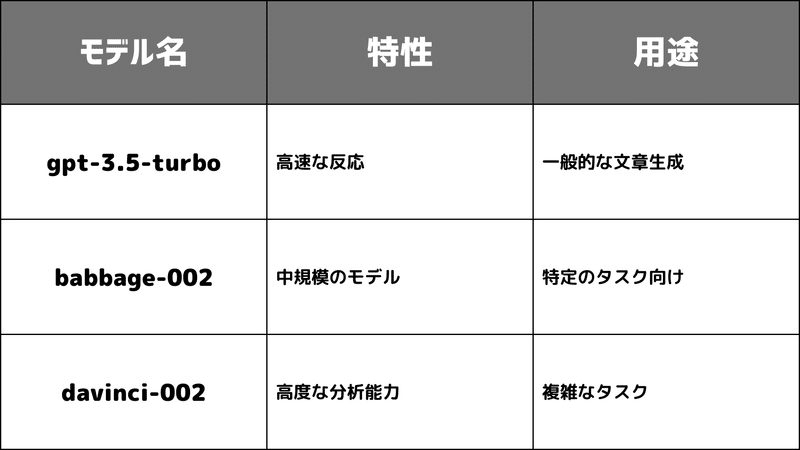
これらのモデルは、それぞれ異なる特性や能力を持っており、用途や目的に応じて選択することが大切です。
Fine-tuningのタイミング
なぜFine-tuningが必要なのか?
「Fine-tuning」とは、AIを特定の仕事に合わせて調整することを指します。例えば、あるAIは日常会話が得意でも、医学の専門用語には弱いかもしれません。そんな時、医学の知識を持たせるためにFine-tuningを行います。これにより、AIは特定の分野でも役立つようになります。
しかし、このFine-tuningは、GPTモデルを特定のタスクやアプリケーションに特化させるための手法として開発されました。このプロセスを通じて、モデルはプロンプトに多くの例を含めることなく、より高品質な結果を得ることができます。Fine-tuningの結果、トークンの使用量が削減され、リクエストのレイテンシ(リクエストの返答への時間)も低減されることが期待されます。
Fine-tuningの推奨されるシチュエーション
AIを使って何かをしたいけど、うまくいかないときがあります。そんな時、AIにちょっとした「追加学習」をさせることで、より役立つ結果を得られることがあります。この「追加学習」のことを「Fine-tuning」と呼びます。しかし、Fine-tuningは少し手間がかかるので、本当に必要な場面で行うことがおすすめです。
データセットの準備
データセットのフォーマット
AIに追加学習をさせるためには、学習データが必要です。このデータは、特定の形式で用意する必要があります。簡単に言うと、AIとの会話のような形でデータを作成します。例えば、「質問」と「答え」のセットをたくさん集めるイメージです。このデータセットは、OpenAIのChat completions APIのフォーマットに従って準備する必要があります。
トークンの制限とコスト
AIが一度に扱える情報の量には限りがあります。これを「トークン」という単位で考えます。追加学習をする際、一度に使えるトークンの数には上限があるので、注意が必要です。また、追加学習にはコストがかかることもありますので、事前に確認しておくと良いでしょう。
Fine-tuningの効果の分析
Fine-tuningを行った後、その成果をどのように確認するかは、AI活用の成功にとって非常に重要なステップです。正確に効果を分析することで、今後の方針や改善点を明確にすることができます。
モデルの評価方法
モデルの性能を評価する方法はいくつかあります。最も一般的なのは、テストデータセットを使用しての評価です。このデータセットは、モデルがまだ見たことがない新しいデータで、モデルの予測精度や反応速度をチェックするために使用されます。また、実際の業務での適用例やユーザーフィードバックをもとに、モデルの実用性を評価することも重要です。
データの質と量の調整
Fine-tuningの結果が期待通りでない場合、原因としてデータの質や量が考えられます。データの質が低い、例えば誤った情報や偏ったデータが多い場合、モデルの性能もそれに影響されます。このような場合、データのクリーニングや再収集が必要となることがあります。また、データの量が不足している場合、新たにデータを追加してFine-tuningを行うことで、モデルの性能を向上させることが期待できます。
よくある質問 (FAQ)
Fine-tuningに関するプロセスは複雑であり、多くの疑問や不明点が生じることがあります。以下は、よく受ける質問とその回答をまとめたものです。
Q: Fine-tuningのコストはどれくらいかかりますか?
A: Fine-tuningのコストは、使用するデータの量やモデルの種類、そして計算リソースによって大きく異なります。詳しくはこちらをご参照ください。Q: Fine-tuningの結果が思ったようにならない場合、どのような対処をすれば良いですか?
A: まず、使用したデータの質や量を再確認することが大切です。データに問題がない場合、モデルの設定やパラメータを調整して再度Fine-tuningを試みることが考えられます。Q: Fine-tuningに使用するデータは、どのように収集すれば良いですか?
A: Fine-tuningに使用するデータは、目的に応じて適切に収集する必要があります。公開されているデータセットを利用することもできますが、独自のデータを収集する場合は、専門家の意見やガイドラインを参考にすると良いでしょう。
お読みいただきありがとうございました!
ChatGPTをビジネス活用できるようになる「ChatGPT実践ガイド」も配信しています。ぜひ覗いてみてください!
サポートも大歓迎です🙆♂️✨ こらからもいい記事を書いていこうと思います🥰