何アタノマエのこといってんだコイツと思われた事でしょうが.. 手持ちのWindowsはXeon E5-2643 x 2ソケットで動作させてまして、主に家中のPCやmacのバックアップをしたり、VMWareでWindowsを8台くらい動作させてActive Domain のテストなんかをしてます。 CPUのスペックは 3.4GHz の6コアなので合計12コア。 HyperThreadは切ってます。HTのセキュリティバグ対策です。もうインテルから対応パッチでないし。
LM Studio 0.2.17 がマルチモーダルに対応したので試してみました。 環境は M1 mac です。メモリーは最低でも16GByteは欲しいところ。 手順をメモしておきます。 お手軽度はとっても低いです いつものようにLM Studio を立ち上げて絵を放り込めば、という状態にはなっていません。 LM Studio をサーバーモードで起動して、OpenAIの互換APIに対してターミナルのpythonで聞き出す、というなんとも遠回りな方法です。 モデルの準
ChatGPTやGeminiなど大規模AIに学習させて予想だにしない素晴らしい結果がでていますよね でもどうしてそのような結果が出るかがよくわかんない、というのを漫画家の士郎政宗さんが38年以上前にアップルシードという漫画の題材にしていました アップルシードの2巻の途中のコマです ガイアという法を執行し人類に貢献するために作られた巨大AIが、これまた人類をサポートするバイオロイドを駆逐しようとするお話 そのバイオロイドは人間に酷似していて見分けがつきませんが思考
Stable Cascadeなる新しい画像生成がgithubで公開されました 生成速くて綺麗さも上らしいんですがVRAMが20GByte必要なんだとか。RTX4070ti super 狙ってたんですけど16Gbyteだからダメじゃん。 でもってバレンタインの今日はドル円爆安で151円に届きそう。 macなら64GByteもVRAMあるけどPyTorch 遅いしなぁ。cuda特化してるから仕方ないけど。 ここでRTX4090買ってもStable Cascade動作させ
MacでLLMを動作させるのに色々苦労してきましたが、最近ではもっぱらLM Studio を使っています。(執筆時点のバージョンは 0.2.12) 日本でも東工大と産総研が作ってくれた日本語に特化した巨大モデルSwallowがあります。 なんと13B(130億パラメータ)と70B(700億パラメータ)ですよ! もちろん素のモデル状態ではデカすぎ & 計算量多すぎでローカルなんかでは動作できないんですがbit数をドカーンと4bitに落としてもだいたいオッケーな感じで動
単体利用よりも組み合わせか? 「M3 Ultra欲しくなってきた」で最後にチョロっと書いた 0.1秒で描画が終わる 推論型の画像生成 LCMですが、よく考えたら層が少なすぎて ControlNet みたいに途中でチョイチョイチャチャを入れて画像を作り上げていく、という手法は取りづらそう 以下の記事の動画で自分をリアルタイム美少女化 LCMを使って(ほぼ)リアルタイム変換して動画に」で紹介されてるけど、逆にこれは第一層でほぼ全てが完結してしまう懸念。 下書きとして人
今回は日記 私はMBP M1 Max + 64GByteメモリーを使ってます。 LLMとか動作させると、7Bは楽勝、13Bだとチャット数回分くらいかな。 世の中のフリーのAIのモデルはTensorFlowとかTourchを使ってるので Apple Siliconだと互換性を取るために能力の半分以下、メモリーを倍くらい使うっぽいんですよね。 なのでRTXシリーズで言えば VRAM 32GByte弱ってところ。 M3 ダイナミックキャッシング期待 M3 Ma
なんかもうググると、広告目当てなのかくだらない説明が多くて辟易したので自分メモを残します AUTOMATIC1111 1.5.1 を使う分には特段難しいことはないようです。 出る絵が素晴らしいという事もないようです… 今までの環境にgit pull してはいけない! 絶対に何かが壊れて、謎のエラーが沢山でます。いままでの環境とは分け て作りましょう。 mac OSのAPFSは優秀なので同じファイルをコピーしても容量をくいませんので、モデルやVAEはガンガンコピーしま
StableDiffusion + ControlNet Tileを使うとQRコードをベースに画像が作れると聞いて試してみました。 ほとんどの場合うまくいきませんが(笑) あとQRコードを読みとる機械の性能にもよると思います。 iPhone12でギリギリ読めるあたりの絵をご紹介します。 読み取りにはコツがいる 二律背反なんですが絵を重視すると読み取りづらいQRコードになります。 といって読み取りやすいのは汚いんだよぉぉ。 まずは読み取りづらいけど、絵として成
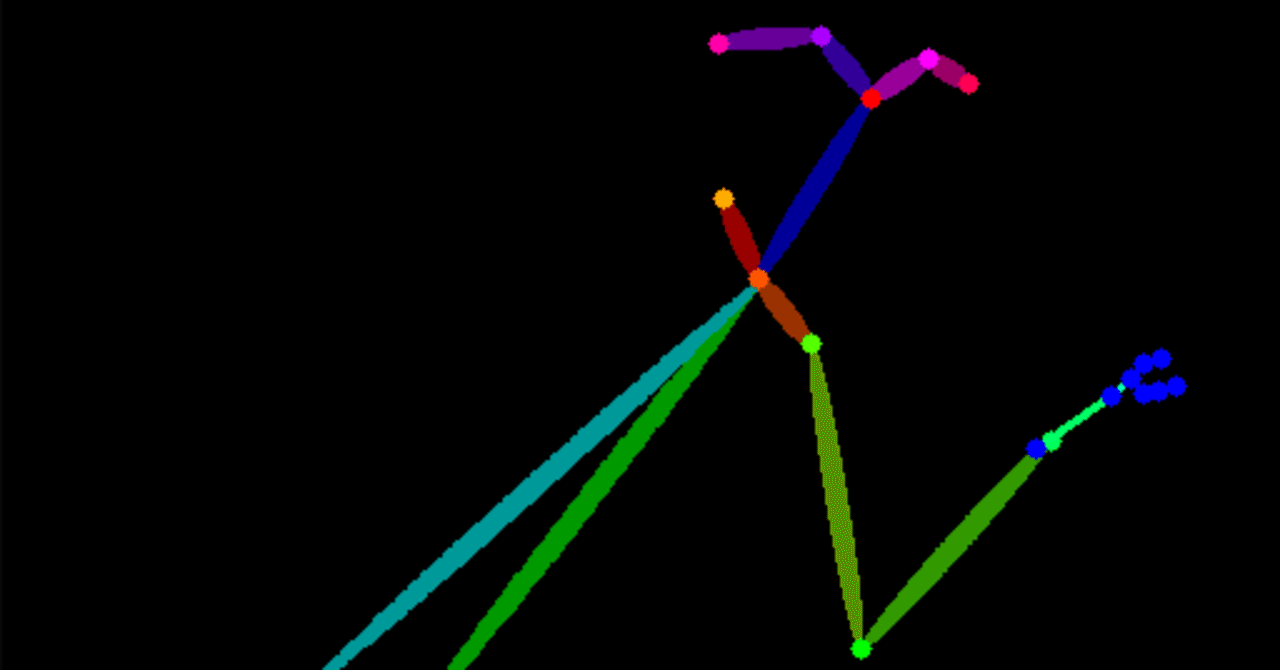
この手の記事はすばらしい絵が生成されて「大成功!」が多いんですが.. 自分は失敗ばかりしているので2度目は許さん、と自戒の念を込めて記録に残します。 元々OpenPoseは CMU-Perceptual-Computing-Lab が開発したもので、人体の可動域を学習させたAIから高速で推測させるプログラムです。その速度はスマホで動画からポーズを推定するほど高速です。 色分けは左右の色を認識するためにつけられています。 ControlNetのポーズは白黒で判定
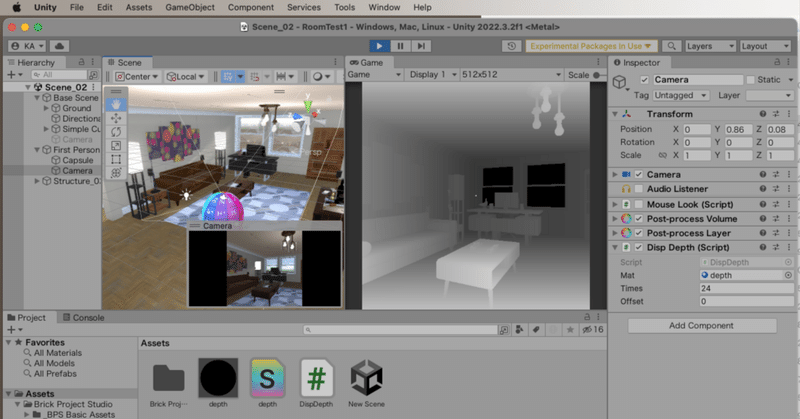
結論から書きますと、時刻で生成するには自分のプロンプト力が足りませんでした(笑 前回からの言い訳 部屋はフォトグラメトリーして3Dで作る方針へ、といったな。あれは嘘だ。 いまだ決定打に至らずだけど、健忘録として書く。何かメモしておくと夜中寝てる時にハッと気づいたりするじゃん? フォトグラメトリーにするには四方八方から撮った写真が必要 1枚の写真から深度を推測するのはControlNet のDepthプリプロセッサーでもできるんだけど、所詮推測なわけで変なところが出
前回の続き 前回はこちら この記事は先週からStableDiffusionってなんじゃらほい、と始めた素人の思い込み100%でできてます。 生成絵は綺麗だけど雑 前回は自分の書いたヘボ絵からtxt2imgとControlNetのMobel → scribbleを使って美しいベッドや家具が配置された画像を生成、さらにその生成画像から同じくControlNetのPreprocessor → LineArt-Standard でヘボ絵を無かったことにしました。 ノベルゲー
StableDiffusionをゲーム制作に使えないもんかなぁ。 まずはテキストノベルゲームで必要なパーツを揃えてみよう、と思い立ち手を動かしてみました。 やる気を出すために形からだよね。最初は主人公の自室背景画像でも作ってみよう。 ゲームエンジンはUnity(宴?)とかティラのスクリプトとかが慣れてるので、そこで使えそうなサイズ感で。640x480。あとから高精細にアップスケールするか?そもそもBGはボカすのでそこまで解像度いらないかも? 準備 まずはiPadとA