【データ分析】ネットワークグラフのソフトクラスタリング〜LinkCommunity

今回の記事はややニッチなトピックになります。
先日、仕事をする中で「LinkCommunity」というネットワークグラフをクラスタリングする手法の一種について勉強しました。
このクラスタリング手法はRのパッケージ「linkcomm」で提供されており、結果を見るだけであれば簡単にできます。
ただ、流石に仕事で扱う上で仕組みを知らないまま結果について語るわけにもいかないため、補助教材としてネットワーク分析に関する書籍を参照しつつ、提唱者の論文を読んで勉強した次第です。
私は他人へ分かりやすく説明できるようにすることが質の高いインプットに繋がると考えているので、今回も「LinkCommunity」について学んだことを記事に仕立てることでこの考えを実践していきます。
できるだけ前提知識が無くても理解できるように書くことを心がけました。初めてこのトピックに触れる方でも興味を持って読んでいただけますと幸いです。
※ コラムでは数式の出てくるやや発展的な内容を纏めています。
ネットワークグラフのクラスタリングとはどういうことか
ネットワークグラフとは
それではネットワークグラフとは何でしょうか。ネットワークグラフは、点と線で構成される図で、さまざまな要素や情報がどのように関連しているかを視覚的に示すものです。

例えば、SNSの友人関係やウェブページのリンク構造を表すのに使われます。点は人やウェブページといった個々の要素を、線はその要素間の関係や接続を示しています。
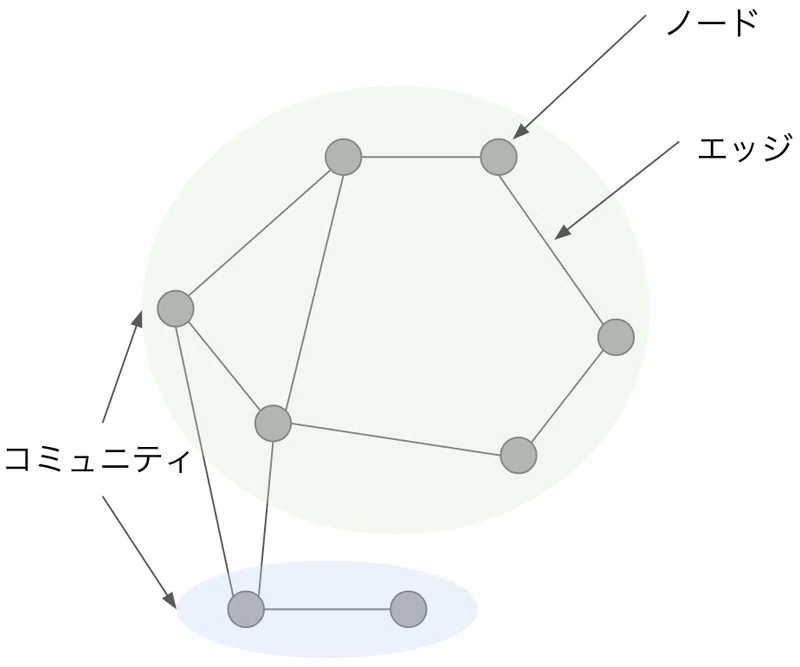
用語の確認:「ノード」「エッジ」「コミュニティ」
ネットワークグラフでは要素を表す「点」のことを「ノード」、要素間の関係を表す「線」のことを「エッジ」と呼びます。
また、ネットワークグラフ上で抽出した「ノード」のクラスタは「コミュニティ」と呼ばれます。
ネットワークグラフの種類
ネットワークグラフにはエッジの向きの有無、エッジの重みの有無によって次のフレームワークのような2×2の4種類が考えられます。

エッジの向きは、ネットワークグラフにおける関係の方向性を示すものです。

例えば、AからBへの送金を表す場合、エッジはAからBへの矢印として描かれます。このような向きを持つグラフを「有向グラフ」と呼び、向きを持たないグラフは「無向グラフ」と呼ばれます。
エッジの重みは、ノード間の関係の強さや重要性を示す数値です。例えば、都市間の道路を表すグラフでは、エッジの重みによって距離や所要時間を表すことができます。
次の重み付きグラフの例では、3都市A、B、Cの間のそれぞれの距離がエッジの重みで表現されています。AとBの距離は2、AとCの距離は8、BとCの距離は1となっており、距離が開いているほどエッジが太くなっています。

クラスタリングとは
そもそもクラスタリングとは何でしょうか。クラスタリングについては、詳しくは以前書かせていただいた記事で解説しています。
ここでは簡潔に、クラスタリングとは、たくさんの物や情報を何個かのグループに分類することを指すとします。
つまりネットワークグラフのクラスタリングとは、ネットワーク上のノードをいくつかのグループへ分類することを意味します。
LinkCommunityとはどのような手法なのか
ソフト×階層クラスタリング
ネットワークグラフにおけるクラスタリング対象はノードです。
「LinkCommunity」は、ネットワークグラフのノードについて、重複(overlap)を許して階層的なクラスタリングを行う手法となっています。
例えば、ある学校のクラス生徒を交友関係に基づいてクラスタリングするケースを考えてみてください。
もちろん普段から特定の一グループでしか遊ばないような生徒も居るでしょうが、複数のグループに所属し、様々な人と遊ぶ交友関係の広い生徒も居るはずです。
こうした交友関係の広い生徒は、同時に複数のグループへクラスタリングされる状況を想定する方が自然ですよね。

どのようにしてソフトクラスタリングを実現しているのか
では「LinkCommunity」はどのようにソフトクラスタリングを考えているのか。
個人的に今回勉強していて一番面白いと思ったのはこの仕組みです。
実は「LinkCommunity」はノードを直接クラスタリングするのではなく、エッジのクラスタリングを介してノードのクラスタリングを行なっています。
どういうことか、次の図をご覧ください。エッジのクラスタリングを考えると、ノードをソフトクラスタリングすることができます。

本来のクラスタリング対象であるノードではなく、その関係性を規定するエッジのクラスタリングを介してノードに迫るアプローチは新しいと思います。現実世界の有り様がそのまま反映された手法のようにも感じました。
エッジのクラスタリング方法
ではどのようにエッジをクラスタリングしているのでしょうか。
クラスタリングを行う場合、何らかの基準でクラスタリング対象の類似度を測定する必要があります。
「LinkCommunity」では、エッジ間の類似度を測定するためにJaccard係数を利用しているようです。Jaccard係数については、次の記事で詳しく解説しています。
例えば、次のネットワークグラフにおけるエッジB-AとエッジG-Aの類似度は、次のように計算されます。

①まず、ノードBと隣接するノードを数えます。今回はノードB自身も含めると、A、B、C、Fの4個のノードが隣接しています。
②同様にノードGと隣接するノードを数えると、A、F、G、Hの4個のノードが隣接しています。
③ノードBとノードGのいずれかに隣接しているノードは、A、B、C、F、G、Hの6個あります。
④ノードBとノードGに共通して隣接しているノードは、AとFの2個です。
⑤ ③に対する④の比がエッジB-AとエッジG-Aの類似度(Jaccard係数)になります。$${\cfrac{2}{6}=\cfrac{1}{3}}$$
「LinkCommunity」では、全てのエッジの組み合わせについて同様にJaccard係数を計算して、階層的にクラスタリングを行っていきます。
階層クラスタリングの手法には群平均法やWard法等色々ありますが、Rパッケージ「linkcomm」ではデフォルトの場合、群平均法が採用されているようです。
ここまで「LinkCommunity」のクラスタリングの概要を、できるだけ数式を使わないように見てきました。ネットワークグラフからのコミュニティ抽出について、雰囲気は掴んでいただけたと思います。
発展編
以下ではより複雑なグラフへ「LinkCommunity」を適用させる際の考え方や、階層クラスタリングにおけるコミュニティ抽出の指標について解説します。
数式は、その解釈をできるだけ言葉で説明するように心がけましたが、説明が難しくなってしまったためコラムとして記載します。
コラム①「重み付きグラフや有向グラフへの適用について」
論文ではエッジ間類似度について、有向グラフや重み付きグラフで考える方法にも触れられていました。
The similarity between links can be easily extended to networks with weighted, directed, or signed links (without self-loops), since the Jaccard index generalizes to the Tanimoto coefficient. Consider a vector $${\textbf{a}_{i} = (\tilde{A_{i1}}, \cdots, \tilde{A_{iN}})}$$ with
$${ \tilde{A_{ij}} = \cfrac{1}{k_{i}}\Sigma_{i’\in n(i)}w_{ii’}\delta_{ij}+w_{ij}}$$
where $${w_{ij}}$$is the weight on edge $${e_{ij}, n(i)=\{j|w_{ij}>0\}}$$ is the set of all neighbors of node $${i, k_{i}=|n(i)|}$$, and $${\delta_{ij}=1}$$ if $${i=j}$$ and zero otherwise. The similarity between egdes $${e_{ik}}$$ and $${e_{jk}}$$, analogous to Eq.(S5) is now:
$${S(e_{ik}, e_{jk})=\cfrac{\textbf{a}_{i}\cdot\textbf{a}_{j}}{|\textbf{a}_{i}|^2+|\textbf{a}_{j}|^2-\textbf{a}_{i}\cdot\textbf{a}_{j}}}$$
ここで登場するタニモト係数(Tanimoto coefficient)はJaccard係数の一般化を考えた拡張になっています。
$${\tilde{A}_{ij}}$$はエッジ$${e_{ij}}$$の重みを表します。従ってベクトル$${\textbf{a}_{i}}$$はノード$${i}$$から他の全てのノードに対するエッジの重みを並べたベクトルになっています。
コラム②「ちょうど良いコミュニティ数を決める基準:分割密度」
エッジ間の類似度に基づき階層的にクラスタリングを行っていくと、次のようなデンドログラムが生成されることになります。

こうしたデンドログラムを好きな高さで(図8の赤点線のように)横に切ると、適当なコミュニティを抽出できるわけですが、どの高さで切るのが「ちょうど良い」のでしょうか。
そもそもこの場合の「ちょうど良さ」とは何なのでしょうか。「ちょうど良さ」を測るための基準として「分割密度」(Partition Density)という基準が提案されています。
次の式は、ネットワークグラフから抽出したコミュニティの分割密度$${D_{c}}$$を表す式です。
$${D_{c}=\cfrac{m_{c}-(n_{c}-1)}{n_{c}(n_{c}-1)/2-(n_{c}-1)}}$$
添字の$${c}$$は「LinkCommunity」によって抽出されたコミュニティ。$${m_{c}}$$、$${n_{c}}$$はそれぞれコミュニティ内のエッジとノードの数を表しています。
分母と分子に共通して出現する$${(n_{c}-1)}$$の項は、ノード数から1を引いた数ですが、これはコミュニティを最小限の連結状態に保つために必要なエッジの数を表します。ノードを一直線に繋ぐために必要なエッジ数と考えると分かりやすいです。
分母の$${n_{c}(n_{c}-1)/2}$$の項は、「コミュニティ内の全てのノード間にエッジが存在する場合の最大エッジ数」を表すため、分母はこれと「コミュニティを最小限の連結状態に保つために必要なエッジ数」の差を表しています。
また、分子の$${m_{c}-(n_{c}-1)}$$は、「実際のエッジ数」と「コミュニティを最小限の連結状態に保つために必要なエッジ数」の差を表すことになります。
これらの比を取ることで、$${D_{c}}$$はコミュニティが最大限連結されている状態にどの程度近い状態に在るのか定量的に表す指標と考えることができます。
コミュニティ毎に計算した分割密度$${D_{c}}$$を平均したものが、ネットワークグラフ全体の分割密度$${D}$$になります。
$${D=\cfrac{2}{M}\Sigma_{c}m_{c}\cfrac{m_{c}-(n_{c}-1)}{(n_{c}-2)(n_{c}-1)}}$$
$${M}$$はネットワークグラフ全体のエッジ数を表します。
図8の右側に青い線で分割密度を表すグラフが表示されていますが、「ちょうど良い」コミュニティに分割されている状態を、分割密度が最大になっている状態として捉えていることが分かります。
ただし、必ずしも分割密度が最大となる時点がちょうど良いコミュニティ分割になっているとは限りません。一つの指標としては妥当ですが、分析の目的に応じたコミュニティ分割を考えることが最も重要です。
この記事が気に入ったらサポートをしてみませんか?