既存日本語ベンチマークについての調査結果

LLMの日本語性能を確認するためのベンチマークとして、
・現状使われているもの
・使えそうなもの
について調べてみました。
1. 課題感
近年、ChatGPTを筆頭としたLLMの成功・活躍から、多くのLLMが発表されています。英語のモデルに遅れてではありますが、そうした流れを受けて日本語に強いモデルも出てきてはいます。
英語モデルは多様な観点でその能力を測るベンチマークが多く整備されています。その種類は、英語テキストからPythonの生成能力を測るHumanEvalや、事実に基づいた発言ができるかどうかを測るTruthfulQAなど多岐にわたります。
しかし、日本語モデルにはまだまだJGLUEによる日本語の理解能力のみがベンチマークとして用いられることが多いと感じており、この辺りを今後整備していけたらと個人的に思っています。
2. ベンチマーク
(1) JGLUE
日本語の生成AI用ベンチマークとして最も用いられているベンチマークだと思います。
文章分類タスクとして、MARC-ja / JCoLA
文ペア分類タスクとして、JSTS / JNLI
質問応答タスクとして、JSQuAD / JCommonsenseQA
があります。
このうち特に、MARC-ja / JNLI / JSQuAD / JCommonsenseQAがStability-AIさんのlm-evaluation-harnessを用いて実行できるようになっており、ベンチマークとして用いられることが多いです。
MARC-jaは、以下のように日本語のテキストからPositiveかNegativeか推測するというタスクになります。

JNLIは、以下のように2つの日本語のテキストから、その関係が
・含意(entailment)
・矛盾(contradiction)
・中立(neutral)
のどれに当たるかを推測します。

JSQuADは、質問応答です。数文からなる日本語テキストを入力として質問に答えるタスクです。

JCommonsenseQAも質問応答のタスクです。こちらではJAQuADとは異なり入力はなく、常識を用いて質問に回答する能力が求められます。

これらは、英語のベンチマークGLUEを元に作られました。しかし、単純な機械翻訳ではなく、作り方を参照してクラウドソーシングによって作られたようです。
(2) JSNLI
京都大学によって整備されたベンチマークのようです。
タスクとしてはNLIタスクです。JGLUEに含まれるJNLIと同様、与えられた2つの日本語テキストの関係が、
・含意(entailment)
・矛盾(contradiction)
・中立(neutral)
のどれに当たるかを推論します。



JGLUEが人手で新しく作られているのに対し、こちらはSNLIという英語のベンチマークを機械翻訳して作ったようです。
(3) AI王 公式配布データセット
質問応答タスクのためのデータセットです。JGLUEにおけるJSQuADとは異なり、入力がないタイプの質問応答です。また、JGLUEにおけるJCommonsenseQAが選択問題であるのに対して、こちらは選択肢が与えられません。純粋な知識の引き出しの多さを測る指標にできそうです。

データセットの種類によってライセンスが異なるようなので扱う際は注意が必要なようです。
(4) Rakuda Benchmark
こちらは他のベンチマークと少し趣きの異なる手法で日本語能力を調べるベンチマーク手法です。
これは、GPT-4を元に作った40のテストデータを用いて、より良い回答を作成するモデルを総当たりで比べていき、その勝率から対象となる複数のモデルのランキングを求めるという評価手法になります。
評価者はGPT-3.5もしくはGPT-4を使っています。
歴史: 幕末に西洋と接触した結果、日本で生じた社会変革について説明してください。
社会: 日本の労働市場の女性活躍推進に関する政策とその結果について説明してください。
政治: 日本の議院内閣制度を説明し、そのメリットとデメリットを詳述してください。
地理: 熊野古道は、日本のどの地方に位置し、主に何のために使われていましたか。
総当たりでモデルの出力結果を比較していく必要があるため、このベンチマークにはなかなかのAPI利用料が発生しそうです。
model_1 | model_2 | winner
------------------------------
gpt-3 | open-calm | 1
rinna-3.6b | gpt-3 | 2
rinna-3.6b | open-calm | 2
..
個人的には、評価者が現状固定できないGPTであることやあくまで他のモデルとの比較であることからあまり好きではないですが、試み自体は面白いと感じます。
(5) その他(XTREME / MGSM)
その他に、多言語用のベンチマークテストとして一部に日本語を含むベンチマークがあります。これらは日本語能力を測るベンチマークとして使えると考えます。私が把握している中では、
・XTREME:多言語における9つの言語処理タスク能力を計測
・MGSM:数学的推論能力を計測(GSM8Kの多言語版)
があります。
[XTREME]
以下のように大きく分けると以下の4種のタスクとなるようです。
・文章分類(Sentence Classification)
・文章構造の推論(Structured Prediction)
・文章検索(Sentence Retrieval)
・質問応答(Question Answering)
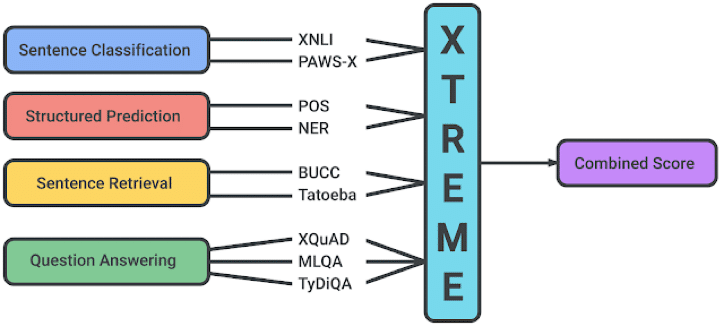
しかし、Hugging Faceにあるデータセットをみたところ、日本語は9つ中4つしか見つかりませんでした。(見逃していたらすみません。)




なので、XTREMEの本来の目的に沿った能力の測定全量はできないかもしれません。しかし、JGLUEのJNLIやJSNLIなどと似たように文章の関係を推測するPAWS-X.jaや、日英対訳のためのtatoeba.jpnなどは個別に使えるのではと思います。
[MGSM]
GPT4含め多くの論文で測定されている数学的な能力を測定するためのベンチマークとしてGSM8Kというベンチマークがあります。MGSMはその多言語版ベンチマークとなります。GSM8Kはおよそ8.5kのデータセットですが、MGSMは各言語258のデータを含みます。これに日本語のものもありました。
中身は以下のように、小学生向けの文章題のようなものです。

ここまで示した通り、日本語のベンチマークで数学的能力を測定するベンチマークは(私が知る限りは)ないのでこれはすぐに使って良いものなのではと思いました。Hugging Faceにあります。
3. 日本語ベンチマーク整備に向けて
今後は、
英語ではどのようなベンチマークが使われているか調査(論文やリーダーボード)
それぞれのベンチマークの特徴・試験している能力などの調査
などを行っていき、既存日本語ベンチマークと比較して必要そうな英語ベンチマークの日本語化などを進めていきたいなと思っています。
引き続き調査した内容などをNoteに書いていけたらなと思っています。
かなり大変そうなのでお手伝いや助言をいただける方がいましたら、コメントやX(旧Twitter)などでお声がけいただけたらと思います。
4. 参照
この記事が気に入ったらサポートをしてみませんか?