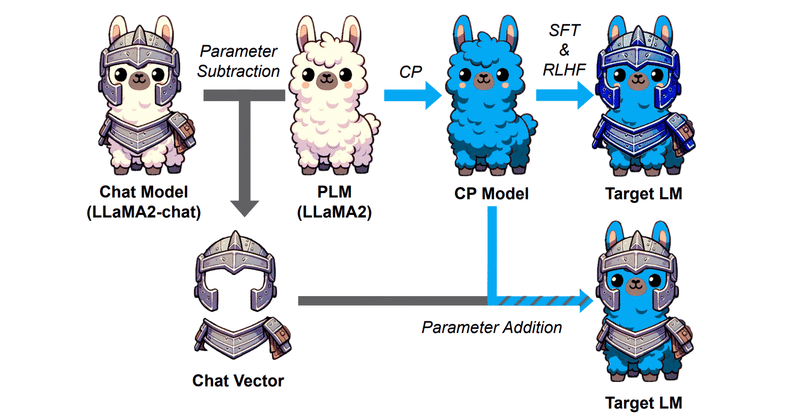
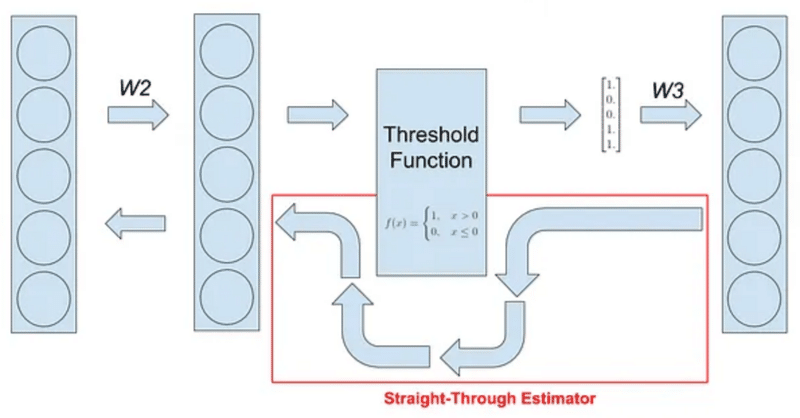
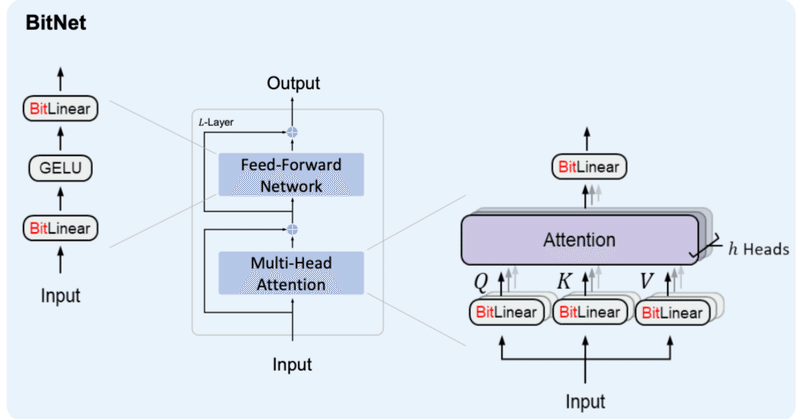
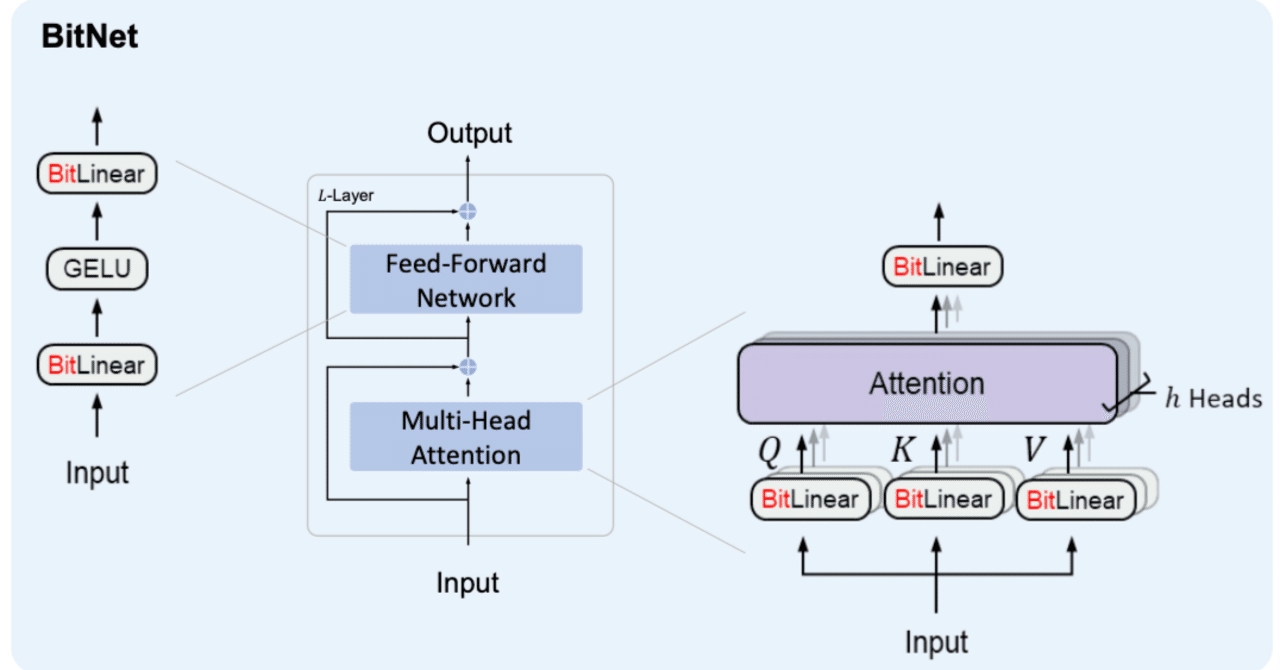
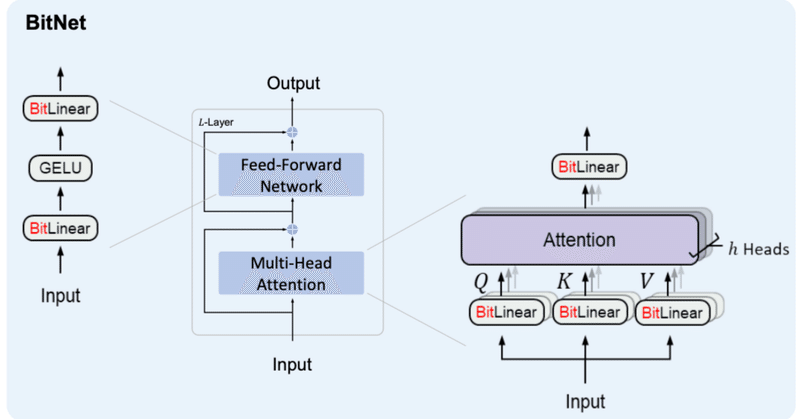
BitNetにおけるSTE(Straight-Through Estimator)の実装
はじめに現在、私は以下のような試みをしています。
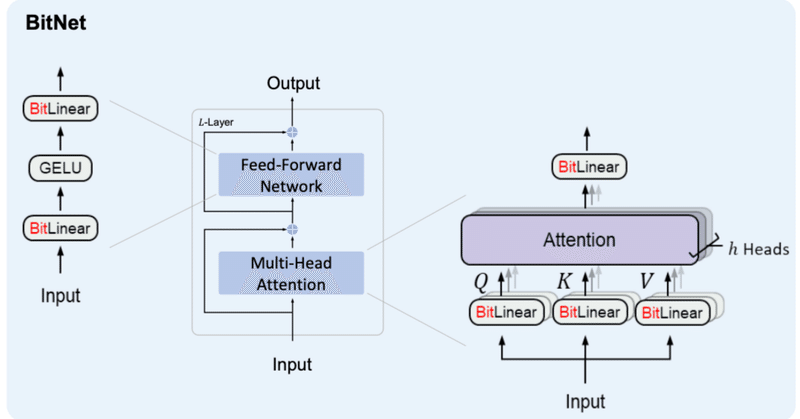
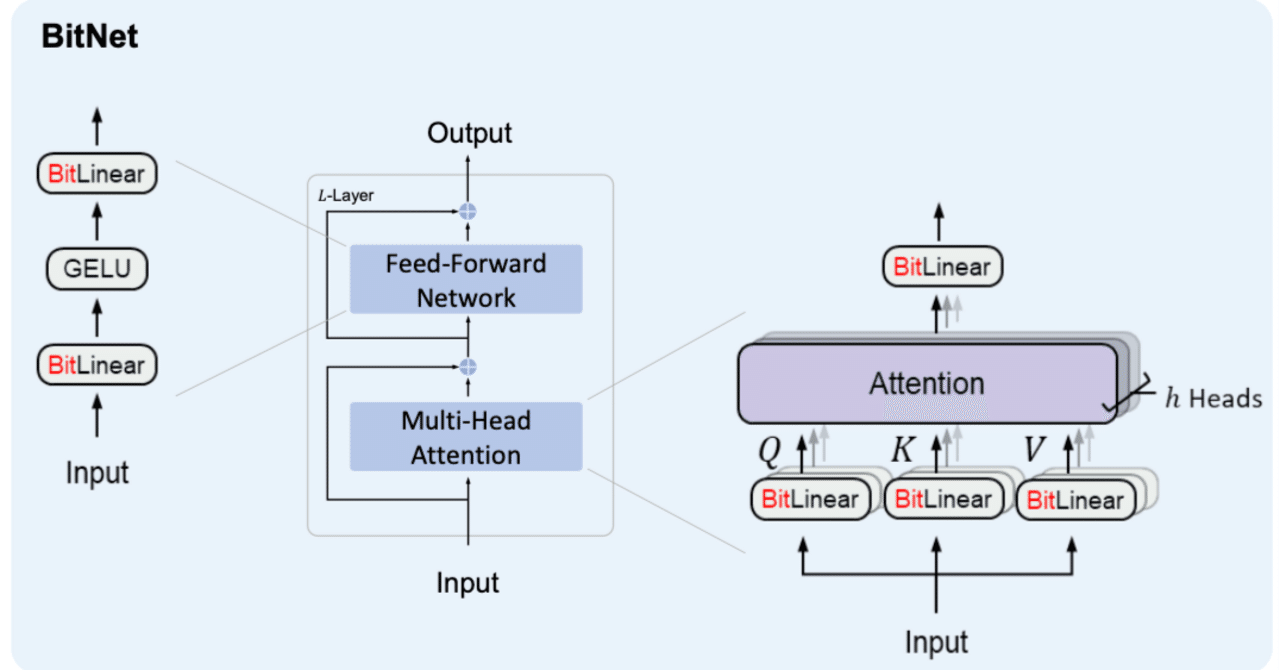
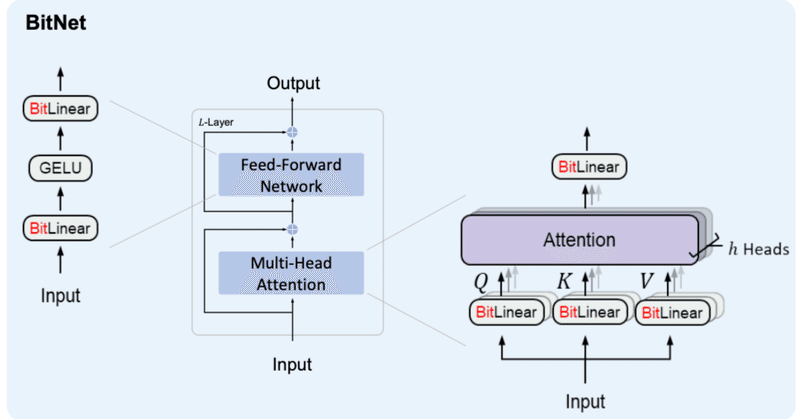
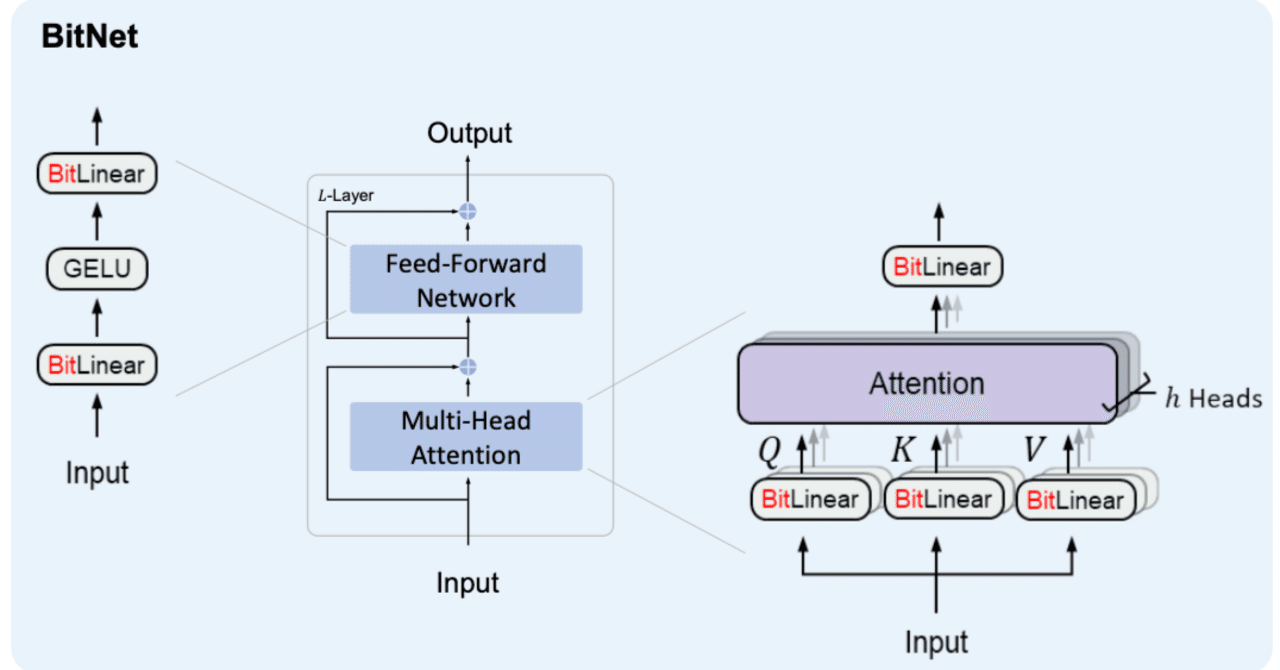
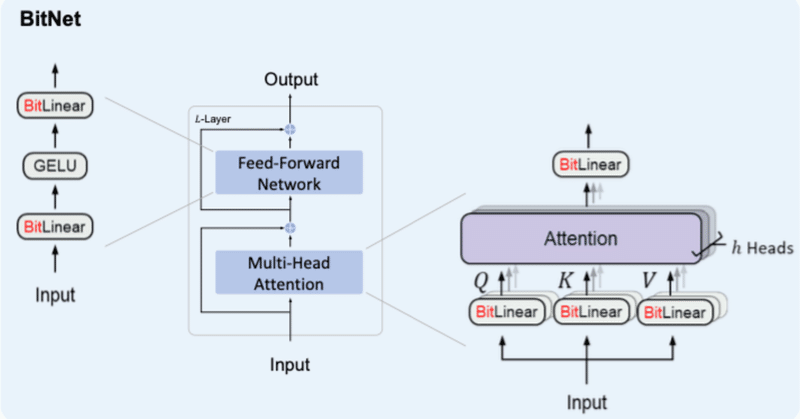
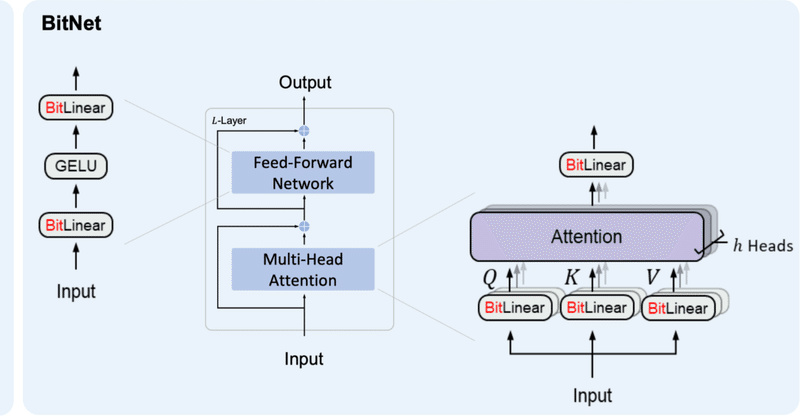
BitNetとは
BitNetとはweightとactivationを量子化する手法の1つで、特にweightを{-1, 0, 1}の3値に量子化するBitNet b158はベースとしているLlama2の性能を上回ることを示し、注目を浴びました。
その実装の中で、量子化(つまりFloat16や32ではなくより離散的な値を扱う様にする処理)を行うとBackward時に微分ができないため学習がうまくできないという問題が発生し