
tensorflowを基礎の基礎から (自然言語処理 番外編Ⅱ)

前回の続きです。
tensorflowのデータセットの扱い方から、今回はkerasの最初くらいまで行くと思います。
では、今回もよろしくお願いいたします。
・tensorflow基礎~データセットの扱い方・結合~
DataFrameみたく、Tensorの結合をする時を学びます。
今回は特徴量データとそれぞれに対応するラベルを簡易的に用意して扱ってみます。
tf.random.set_seed(1)
t_x = tf.random.uniform([4, 3], dtype=tf.float32)
t_y = tf.range(4)前回同様、xはshape = (4,3)で一様分布にしたがってランダムに要素を抽出します。
これらのx, yをマージするにはtensorflowのzip関数もしくはfrom_tensor_slicesで二つの変数を格納するかの2通りで作成できます
-- zip
ds_x = tf.data.Dataset.from_tensor_slices(t_x)
ds_y = tf.data.Dataset.from_tensor_slices(t_y)
print(t_x)
ds_joint = tf.data.Dataset.zip((ds_x, ds_y))
for ex in ds_joint:
print(f'x: {ex[0].numpy()}, y: {ex[1].numpy()}')
-- from_tensor_slices
ds_joint = tf.data.Dataset.from_tensor_slices((t_x, t_y))
for ex in ds_joint:
print(f'x: {ex[0].numpy()}, y: {ex[1].numpy()}')
いずれも同じものが生成されました。
zip関数はpythonの組み込み関数であるzipと同じ挙動であるため、使いやすいと感じるかもしれませんが、基本はどちらでもいいと思います
- 関数を要素に適用
では、Tensorの要素に関数を設定する時を見て行きます。
pandas.DataFrameと同様にmap関数というものがありますので、それを使います。
ds_trans = ds_joint.map(lambda x, y: (x*2 - 1.0, y))
for ex in ds_trans:
print(f'x: {ex[0].numpy()}, y: {ex[1].numpy()}')
自作の関数を適用することもできます。
(公式チュートリアルのサンプルを引用し、少し改良)
dataset = tf.data.Dataset.range(3)
# `map_func` returns two `tf.Tensor` objects.
def g(x):
return tf.constant(37.0), tf.constant(["Foo", "Bar", "Baz"])
result = dataset.map(g)
for item in result:
for elem in item:
print(elem.numpy())
print('-'*10)
ちなみに、DataSetすべてに関数を適用したい場合はapply関数もありますが、ここでは飛ばします。
- データのシャッフル
こちらもpandasのようにshuffle関数があります。
tf.random.set_seed(1)
ds = ds_joint.shuffle(buffer_size=len(t_x))
print(len(t_x))
for ex in ds:
print(f'x: {ex[0].numpy()}, y: {ex[1].numpy()}')
buffer_sizeによりシャッフルする要素の個数を決めます。
今回はlen(t_x)により、全てのサンプルをシャッフルするようにしましたが、試しにbuffer_size=2にすると以下。
tf.random.set_seed(1)
ds = ds_joint.shuffle(buffer_size=2)
for ex in ds:
print(f'x: {ex[0].numpy()}, y: {ex[1].numpy()}')
真ん中の二つのみシャッフルされ、最初と最後は固定されています。
小さいデータセットの場合は、len関数で全要素をシャッフルすると安心だと思います。
- バッチとリピート
データセットをバッチ(データセットを分割して小さなデータセットにしたもの)に分割するのはbatch関数でできます。
前回もbatch は扱いましたが、今回はrepeat関数で同じ要素を繰り返し生成してからバッチにしたり、バッチした後に繰り返してからrepeatするなど、挙動の違いも確認しながら見て行きます。
まずはシンプルにbatchだけを見てみます。
ds = ds_joint.batch(batch_size=3)
print(ds)
print(iter(ds))
print('-'*10)
batch_x, batch_y = next(iter(ds))
print(f'Batch-x:\n {batch_x.numpy()}')
print('-'*10)
print(f'Batch-y:\n {batch_y.numpy()}')
ちなみにiter関数が面倒な人は以下でも一応取り出せます。
ds = ds_joint.batch(batch_size=3)
for items in ds:
for elem in items:
print(elem.numpy())
print('-'*10)
iterator関数とかgeneratorとかに関してはがっつり解説はしませんが、簡単に言えばnext()関数が使えるものをiteratorと言います(ピンとこなくておけですw)
今回drop_remainderはデフォルトでFalseなのでバッチサイズ3に満たなくても要素は残ります。
では、ここからrepeat関数を並行して使ってみます。
ds = ds_joint.batch(3).repeat(2)
for ex in ds:
print(f'x: {ex[0].shape}, y: {ex[1].numpy()}')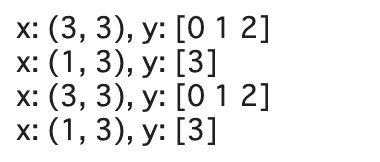
batchで今回元々要素が4つあったds_jointを3, 1 (=4 -3)に分割したものを2つにして(繰り返して)います。
では、次にbatchとrepeatの適用順を反対にします。
ds = ds_joint.repeat(2).batch(3)
print(ds_joint.repeat(2))
for ex in ds:
print(f'x: {ex[0].shape}, y: {ex[1].numpy()}')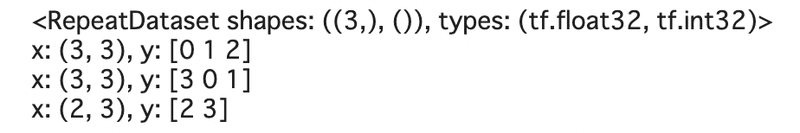
一応yの要素で確認できますが、一応ds_joint.repeatの段階を確認します。
[item for item in ds_joint.repeat(2)]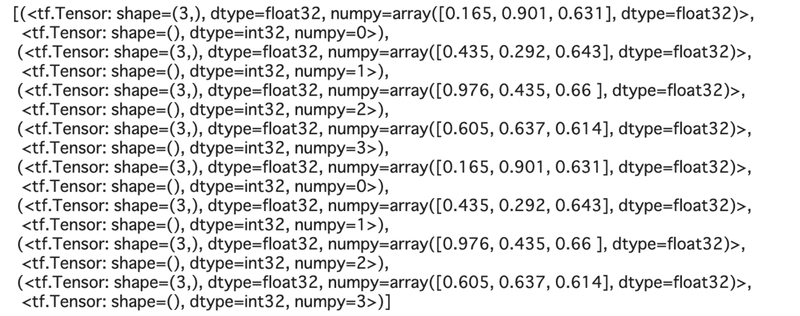
視覚的にみたほうが早いので図でみます。
(ちょっと面倒なので)yのみ注目して考えます。

つまり、適用順によって出てくる出力が全く変わってきます。
.batch().repeat()なら最初にbatch処理して、その後repeat(左図)
.repeat().batch()はその逆(右図)
- バッチ・シャッフル・リピートの組み合わせ
上記の図でほとんどイメージはついたと思うのですが、一応shuffle関数も混ぜてみて考えましょう。
tf.random.set_seed(1)
ds = ds_joint.shuffle(4).batch(2).repeat(3)
for ex in ds:
print(f'x: {ex[0].shape}, y: {ex[1].numpy()}')
shuffle関数はエポック(訓練データの訓練回数)ごとにshuffleが施されるため、その後のbatch->shuffleでもうまくshuffleされていることがわかります。
tf.random.set_seed(1)
ds = ds_joint.shuffle(4).repeat(3).batch(2)
for ex in ds:
print(f'x: {ex[0].shape}, y: {ex[1].numpy()}')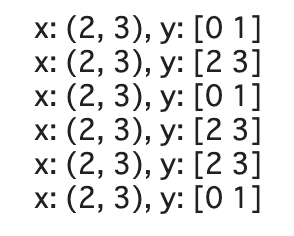
先にbatchをするとバッチの要素がシャッフルされてしまうため、要素の中身自体がシャッフルされることがなくなります。
では、shuffleを最後に持ってきて、repeat->batch->shuffleで行ってみます。
tf.random.set_seed(1)
ds = ds_joint.repeat(3).batch(2).shuffle(4)
for ex in ds:
print(f'x: {ex[0].shape}, y: {ex[1].numpy()}')
こちらもリピートしたものを要素2になるようにバッチを生成し、それをbuffer_size=4でランダムしています。
shuffleの前後を比較してみるとわかりやすいかもですね
tf.random.set_seed(1)
ds_rb = ds_joint.repeat(3).batch(2)
for ex in ds_rb:
print(f'x: {ex[0].shape}, y: {ex[1].numpy()}')
print('-'*10)
ds = ds_joint.repeat(3).batch(2).shuffle(12)
for ex in ds:
print(f'x: {ex[0].shape}, y: {ex[1].numpy()}')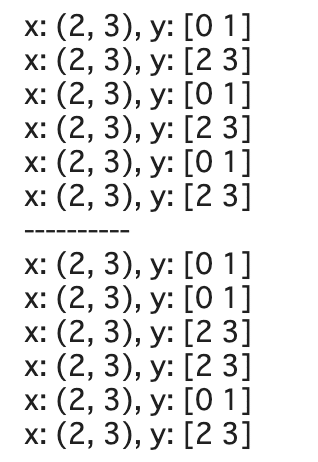
まぁ、いろいろ遊んでみても面白いかもです。
・kerasの基礎〜軽くイントロ〜
tensorflowの文法的なパートはこの辺にして、一つの山場のkerasを扱って行きます。
(余談ですが、自分がkerasを知った時はkerasのパッケージで、import kerasとかで書いてました。ちょっと間が空いてからコードを実行したら、たちまちエラーになってて、調べたらtensorflowの中に統合されていました。。。なので、kerasを扱う教材に関しては、最新のものを買った方がいいと思っている人です)
Neural Networkといえばkeras!みたいな感じがあるくらい人気であり、実際に少ないコードですぐに実行できるのがメリットです。
しかし、kerasの記事とかみると、まぁtensorflowの基礎とか機械学習の基礎は知ってる前提で話されていて、とっかかりにくいという印象が(私は)あったりします。
しかし、前回と今回でtensorflownの軽い文法は踏まえた上で、かつ、このコードで何をしているのかをできる限り説明していく(つもり)ですので、一緒に学んでいきましょう。
・kerasの基礎
単純な線形回帰からアプローチしていこうと思います。
まず、馴染みあるnumpy で用いるデータの作成をしてみます。
X_train = np.arange(10).reshape((10, 1))
y_train = np.array([1.0, 1.3, 3.1, 2.0, 5.0, 6.3, 6.6, 7.4, 8.0, 9.0])
plt.plot(X_train, y_train, 'o', markersize=10)
plt.xlabel('x')
plt.ylabel('y')
plt.show()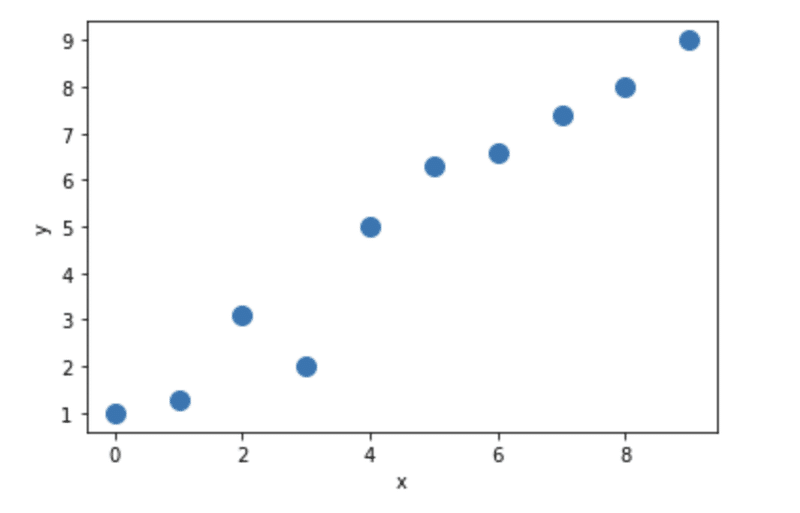
次に、標準化(平均を引き、標準偏差で割る)を手動で行い、得られたデータをTensorに変換します。
X_train_norm = (X_train - np.mean(X_train)) / np.std(X_train)
ds_train_orig = tf.data.Dataset.from_tensor_slices((tf.cast(X_train_norm, dtype=tf.float32), (tf.cast(y_train, dtype=tf.float32))))(おさらい)tf.cast(value, dtype)でvalueを指定した型に変換します。
では、準備ができたところで、今回は一旦標準で実装されているものを使うのではなく、自作である程度の部分を作って行きます。
まずはkeras.modelを親クラスとしたMymodelを作成します。
class MyModel(tf.keras.Model):
def __init__(self):
super().__init__()
self.w = tf.Variable(0.0, name='weight')
self.b = tf.Variable(0.0, name='bias')
def call(self, x):
return self.w * x + self.bクラスの解説は一旦割愛しますが、keras.Modelを急に使われても・・って感じなので、調べました。
__init__(初期化)の中に、自分で定義したい層や新たな変数を作成したい時のお作法として、MyModelを作成するような印象を受けたのですが、
基本的にはモデルの訓練や評価にKerasのツールを利用できるようになるもの、くらいでもいいと思いますし、ドキュメントを見たほうが丁寧ですw
また、Variableで最初の初期値を設定している、くらいで今は進めます。
==以下、(正しくない)例え話しますw==
親クラスを継承したのがMyModelで、その親がkeras.Modelであるので、Kerasのこれから使うfitやcompileなどが使えるようになるわけですが、
クラスの継承がピンとこない方(そしてNARUTO世代)は、
サスケとイタチが戦い、死闘の末にイタチがサスケに最後おでこを指で突いて終わるのですが、その時スサノオをサスケに継承しました。あれですw
鬼滅で言えば、火の呼吸を炭治郎が受け継いだ、あれです。
==しょうもない例え話おわり==
今回は、MyModelにパラメータとして重みwとバイアスbを加え、callメソッドで引数であるxに重みをかけてbiasを足したものを返す関数を作成しました。
このモデルを使って、訓練やら予測やら評価やら行います。
その前に、keras.Modelに実装されているsummaryメソッドを見てみます
まずはコードから。
model = MyModel()
model.build(input_shape=(None, 1))
model.summary()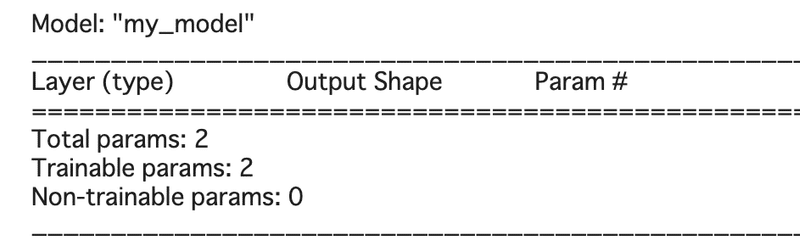
まずMyModelでインスタンス化して、次に入力される形状をbuildメソッドで指定する必要があります。(summary()を使用する場合は必須だが、使わない場合は他の方法もある)
iinput_shape = (バッチサイズ, 入力データの次元)で定義しますが、バッチサイズは最初から決まっていることはないので、Noneにすることで任意の数を受け入れます。
今回MyModelで指定するパラメータは1次元xのであるため、input_shape=(None, 1)になります。
さて、次にコスト関数(今回はMSE)を定義し、バリバリ学習させてみます。
通常はsklearnのようにfitメソッドやcompileメソッドがあるのですが、ゆっくりと。
===
損失関数とかコスト関数とか、この辺からありとあらゆる「〜関数」が溢れ散らかしていますが、以下のURLがめちゃわかりやすかったです
===
学習開始にあたり、損失関数と学習するための関数を手動的に実装します。
ちょっと、いろいろなkerasのメソッドが出てきますが、まずはコードから。
def loss_fn(y_true, y_pred):
return tf.reduce_mean(tf.square(y_true - y_pred))
def train(model, inputs, outputs, learning_rate):
with tf.GradientTape() as tape:
current_loss = loss_fn(model(inputs), outputs)
dW, db = tape.gradient(current_loss, [model.w, model.b])
model.w.assign_sub(learning_rate * dW)
model.b.assign_sub(learning_rate * db)loss_fnに関しては正解データと予測データをパラメータとし、その差を二乗して平均とっているだけです。
train関数に関して。
まずtf.GradientTapeから行きます。(かなり長い説明と補足をしているので、すでに知っている方は飛ばしてください)
・tf.GradientTape
勾配テープという得体の知れないものなんですが、そのためにはちょっと範囲を広げた説明をします。
NeurakNetの最適化において、コスト関数の最適化には勾配降下法のようなアプローチで適切な重みやバイアスを見つける必要があります。
そこで、勾配(各変数で偏微分したものたち)たちを計算することが必要になるわけですが、いくつか準備が必要になります
(こういうのを地道に説明しているから、自分の投稿が毎回1万文字とかになるということを、今書きながら気づきましたw)
理論的な話になるため、体調が悪くなる体質な方は読み飛ばしてくださいませ。
まず、自動微分という考え方が必要になります。
(これ、どうにかして平易な言葉で説明しようとは思っているのですが、かなり数学になりそうです。)
端的に言えば、連鎖律(chain rule)の適用で勾配を蓄積するというような感じです。
図と合わせてもう少し噛み砕きます
(正確性よりイメージの方を持ってもらいたいので、厳密性にはやや欠けると思います。)
今までf(x)という関数があり、それをxで微分する、ということは学んできたかと思いますし、p(x, y)という2変数などでx or yで偏微分するということも学んできたと思います。
しかし、f(g(x)) のように、fという関数はgという関数から出力される値を引数に取るようなパターンもあります。
このfをxで微分したい時に、fは引数にgを取るため、xで直接微分することはできません。そこで連鎖律が必要となります。
ざっとイメージを簡潔にすれば以下。

ちなみに、トップダウンとボトムアップという2種類の自動微分があるのですが、特に気にせず進めます。(Tensorflowはトップダウンのはず)
「Tensorflowは出力を出すために、このGradientTape内で行われる演算全てをテープに記録して、テープと記録された演算に対して自動微分を行い記録された計算の勾配を計算します。」
これ、最初自分には「はぁ?何言ってんの?」ってなりました。。
しかし、ちょっといろんなサイト見てみると、単純に記録していると考えればよくて、例えて言うなれば、簡易的ストリーミング(ダウンロードじゃなくて一回記録だけするみたいな?)とか、ログのような感覚とか、めちゃくちゃ頭のいい書記、みたいな??w
ちなみに以下のサイトがざっと見た中でわかりやすかったです。
ちょっとだけ簡単な例をみます。
w = tf.Variable(1.0)
b = tf.Variable(0.5)
x = tf.convert_to_tensor([1.4])
y = tf.convert_to_tensor([2.1])
with tf.GradientTape() as tape:
# 以下の内容を記録
z = tf.add(tf.multiply(w, x), b)
loss = tf.reduce_sum(tf.square(y - z))
# ここまで。
# つまり、z = w*x + b を計算後、(y - z)の2乗し、総和を取得したlossを記録している
dloss_dw = tape.gradient(loss, w)
tf.print('dL/dw: ', dloss_dw)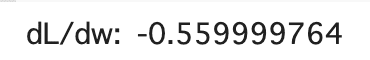
二乗損失のloss = (y - z)**2を定義して、それを微分することを想定しています。
初期値w, b, x, yからlossの計算をtape内で記録して、tape.gradient(loss, w)でtapeに記録されたlossをwで微分しています。
一応、本当に微分されたものが正しい値なのかを手動で見てみます
(loss = (y - z)**2 -> (y - (w * x + b) **2 ) ->(微分) 2x (wx+b - y) を計算)
tf.print(2*x * (x * w + b - y))
- (さらに踏み込みたい方向け)
先ほどまでのw, bとかは訓練可能なパラメータだったのですが、訓練可能ではない時(今回ならx, y)は.watchメソッドを付け加える必要があります。
先程の例を使って今度はxで偏微分したい時を考えてみます。
まずはwatchなしで、るんるん♪と微分してみます。
# watchなし
with tf.GradientTape() as tape:
z = tf.add(tf.multiply(w, x), b)
loss = tf.reduce_sum(tf.square(y - z))
dloss_dx = tape.gradient(loss, x)
tf.print('dL/dw: ', dloss_dx)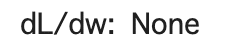
(print時にdwになってますが、無視で)
記録ができていないため、xでの微分ができずNoneが返ってきました。
では、watchをつけてみます。
# watchあり
with tf.GradientTape() as tape:
tape.watch(x)
z = tf.add(tf.multiply(w, x), b)
loss = tf.reduce_sum(tf.square(y - z))
dloss_dx = tape.gradient(loss, x)
tf.print('dL/dx: ', dloss_dx)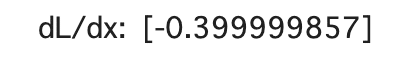
実際にtapeに記録されているため、xをとってきて微分されています。
- 複数の勾配計算をしたいとき
上記は全て一つの偏微分をして終了しましたが、w, xの両方で偏微分したい時に以下のような記述をしてみます。
# watchあり
with tf.GradientTape() as tape:
tape.watch(x)
z = tf.add(tf.multiply(w, x), b)
loss = tf.reduce_sum(tf.square(y - z))
dloss_dw = tape.gradient(loss, w)
tf.print('dL/dw: ', dloss_dw)
dloss_dx = tape.gradient(loss, x)
tf.print('dL/dx: ', dloss_dx)しかし、これではErrorが出ます。

printでwの偏微分はできていますが、xの偏微分ができていません。
これはGradientTapeは一つの勾配計算しか保持できないことにあります。
つまり、gradient実行後にテープが白紙になります。
このとき、GradientTapeの引数にpersistent(永久とか永続みたいな意味)=Trueとすると、複数の勾配計算ができるようになります。
# watchあり
with tf.GradientTape(persistent=True) as tape:
tape.watch(x)
z = tf.add(tf.multiply(w, x), b)
loss = tf.reduce_sum(tf.square(y - z))
dloss_dw = tape.gradient(loss, w)
tf.print('dL/dw: ', dloss_dw)
dloss_dx = tape.gradient(loss, x)
tf.print('dL/dx: ', dloss_dx)
dloss_db = tape.gradient(loss, b)
tf.print('dL/db: ', dloss_db)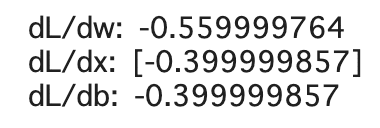
persistent=Trueにするとメモリに情報が保存されたまま残ってしまうので、基本的にはFalseにしておきましょう。
ちなみに、自分はこのGradientTapeが初めましてだったので、どういう時に使うのかの使い所はやや曖昧です。
また出てきた時に書いてみます。
・assign_sub
次にassign_subについて。
tensorflow.assign(割り当て。上書きと思ってもおけ)で値を割り当てるメソッドとtensorflow.subで要素の差を計算するメソッドを同時に行うものがassign_subとなります
assignの簡単な例だけ見ておきます。
a = tf.Variable([1.0, 2.0])
a.assign([4.0, 9.0])
tf.print(a)![]()
値が変わっていることを確認できました。
では、assign_subの例を。
a = tf.Variable([1.0, 2.0])
a.assign([4.0, 9.0])
a.assign_sub([4, 9])
tf.print(a)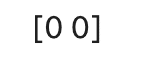
assignでa = [4, 9]にして、assign_subで入力された値を差し引いた値に割り当てています。
今回のtrain関数では
model.w.assign_sub(learning_rate * dW)
となっているため、計算されたwをdWというlossをwで偏微分したものに学習率をかけたものを引き算して再度wに格納されています。
なんでこんなことしてんの?ってなる方もいるかも知れませんが、これは勾配降下法の理論を使っています
それぞれのパラメータ更新は
w := w - η * gradient(loss, w)
b := b - η * gradient(loss, b)
で定義されていることに起因しています。
(GradientTapeに関して意味不明なくらい書いたので、)もう一度train関数を見てみると、ちょっとは読み解けたのではないでしょうか?
def train(model, inputs, outputs, learning_rate):
with tf.GradientTape() as tape:
current_loss = loss_fn(model(inputs), outputs)
dW, db = tape.gradient(current_loss, [model.w, model.b])
model.w.assign_sub(learning_rate * dW)
model.b.assign_sub(learning_rate * db)GradientTapeで、入力されたmodelにinputsを入れた値とoutputsの損失(平均二乗誤差)をcurrent_lossという変数として「記録」
その損失をmodelの中にあるw, bで偏微分したものをそれぞれdW, dbとします。
それらを学習率とかけてすでに設定されたw, bから引いて、重みとバイアスを更新する関数となります。
(伝わりましたかね??)
・関数を実行していく
では、準備した関数を使って実際に訓練します。
とりあえずざっとコード書いてから、説明して行きましょう。
- 訓練するための準備
tf.random.set_seed(1)
num_epoch = 200
log_steps = 100
learning_rate = 0.001
batch_size = 1
steps_per_epoch = int(np.ceil(len(y_train) / batch_size))
ds_train = ds_train_orig.shuffle(buffer_size=len(y_train))
ds_train = ds_train.repeat(count=None)
ds_train = ds_train.batch(1)
Ws, bs = [], []- 訓練開始
for i, batch in enumerate(ds_train):
if i >= steps_per_epoch * num_epoch:
break
Ws.append(model.w.numpy())
bs.append(model.b.numpy())
bx, by = batch
loss_val = loss_fn(model(bx), by)
train(model, bx, by, learning_rate=learning_rate)
if i % log_steps == 0:
print(f'Epoch {int(i/steps_per_epoch)} Step {i} Loss {loss_val:.6f}')
では、順に見ていきます。
ds_train_origは標準化したXとyをマージしたTensorで
それをshuffle -> repeat -> batchの順で最終的にバッチサイズ1のデータに分割しています。
注意点として今回repeat(count=None)とすることで無限にリピートがされています。
そのため、for文でsteps_per_epoch * num_epoch回目(今回は10 * 200)以上の試行は中止しています。
それぞれbx, byでxの値とyの値からloss_fnにより、model(bx)(-> w*bx * b)とbyの平均2乗誤差を準備しておきます
それをtrainでw, bを勾配降下法で更新して行きます。
そして、10エポック(データの訓練回数)ごとに損失関数を見ています。
この訓練データとテストデータを見て、どのように重みが更新されていくのかプロットしてみて行きます。
X_test = np.linspace(0, 9, num=100).reshape(-1, 1)
X_test_norm = (X_test - np.mean(X_train)) / np.std(X_train)
y_pred = model(tf.cast(X_test_norm, dtype=tf.float32))
fig = plt.figure(figsize=(13, 5))
ax = fig.add_subplot(1, 2, 1)
plt.plot(X_train_norm, y_train, 'o', markersize=10, label='Training examples')
plt.plot(X_test_norm, y_pred, '--', lw=3, label='Linear Reg.')
plt.legend(fontsize=15)
ax.set_xlabel('x', size=15)
ax.set_ylabel('y', size=15)
ax.tick_params(axis='both', which='major', labelsize=15)
ax = fig.add_subplot(1, 2, 2)
plt.plot(Ws, lw=3, label='Weight w')
plt.plot(bs, lw=3, label='Bias b')
plt.legend(fontsize=15)
ax.set_xlabel('Iteration', size=15)
ax.set_ylabel('Value', size=15)
ax.tick_params(axis='both', which='major', labelsize=15)
plt.show()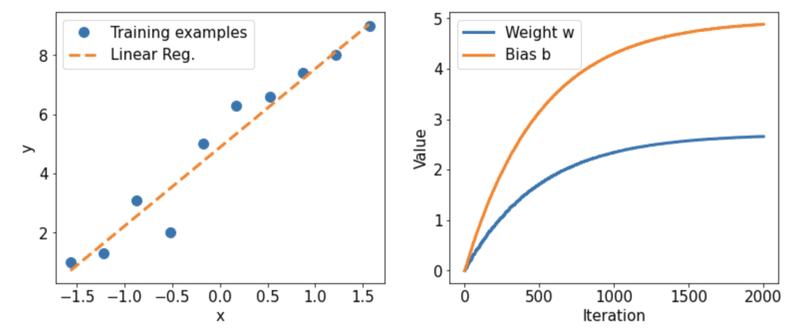
y_predでは普通の線形回帰としてw * x + bをプロットしています。
w, bに関してはイテレーションごとにどのようにw, bが更新されているかをプロットしています。
実際はこのような手続きよりもcompile やfitメソッドを用います(長くなっているので、次回。。)
・一旦終わり
今回はkerasというより、kerasに入るための準備みたいな位置付けになりました。
tensorflowを改めて学ぶと膨大に時間が溶けてしまうので、本当に早くRNN再開したいものの、ここをすっ飛ばすとコピペマンになりそうでもあり、ちゃんと時間かけて行きます。。
==余談==
kaggleで自然言語処理のデータを扱ったのですが、評価指標としてCoherenceというものや、そもそもgensimにLDAメソッドがあることを知り、また学ばないといけないことが増えました。。理解してからまた書ければと思います。
あと、次回以降、不定期でpythonの別のライブラリとか他の知識とかも書いていけたらと思います。
(私が)多角的かつ基礎を忘れないように。。
======
この記事が気に入ったらサポートをしてみませんか?