画像処理のための準備①

今までしばらく自然言語処理を扱ってきましたが、今回から定期的に画像処理の範囲にいこうと思います。
====
実はtransformerの下書きを準備していますが、膨大すぎる量とか自分の理解度的にもう少しかかりそう、っていうのと
どう実装するのかがいまいち不明(pytorch使うのも手段ですが、せっかくtensorflowを集中的に扱ってきたので、tensorflowでBERTまでは行きたいな〜なんてほざいています)
====
なので、(一時的に)話題を変えて画像処理の方に進もうと思います
どのくらいをゴールとしてここで扱おうか悩ましいのですが、CNNとかはもちろんですが、一般的なGANくらいまででしょうか??
しかし、自分がそもそもそこまで画像処理に精通していないので、画像処理のOpenCVの基礎を扱いつつ、並行して機械学習のテーマも扱えたらなと今時点では思っています。
では、今回もよろしくお願いいたします。
・OpenCVに馴染もう
画像処理の基本といえばOpenCVという印象が素人ながらあるくらい有名ですが、ほとんどのことはOpenCVでできるといっても過言ではない気もします。
しかし、pythonじゃなくC++とかの方がより精緻な部分まで扱えたりするそうなので、ガチる人はC++とかも扱ってみてはいかがでしょうか?
ここでは、ほんとの基礎の基礎を(自分の理解を深めるために)扱って行きます。
すでに知ってるよ!って方がほとんどな気もしますので、適当に好きな部分だけ読んでくださいませ。
OpenCVやpillowとか画像処理だけでも複数のものがありますが、一応matplotlibやらnumpy と相性の良いOpenCVを使って行きます。
・画像の読み込み
(OpenCVは一応デフォルトでは入っていないため、先にインストールが必要です。たしかpip installで行けたはず。ぼちぼちDockerとかもここで書きたいですが、余力あれば環境構築をdockerでする回とかも書きますが、一旦は環境構築はできている前提で進めます。)
まずは読み込み出力などの基本操作から。
import cv2
cv2.imread('./data/src/Lena.jpg')
たくさんの数値がarray形式で出力されたかと思います。
そもそも画像は数値データとして当然読み込むわけなので、数値で画像を扱うことに慣れないと行けないのですが、画像処理特有の前提とOpenCVのちょい特有な前提がいくつかあります。
- 画像処理共通の前提
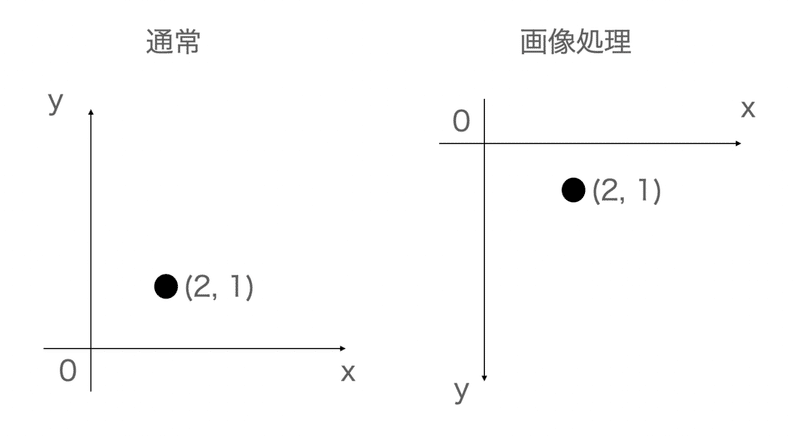
y軸は下方向に伸びている
我々が扱う座標は基本的にx軸は右にいくと大きくなり、y軸は上にいくと大きな数値を取るわけですが、画像処理に関してはx軸に対して反対であり、y軸は下に伸びます。
座標として意識する必要があるケースというのは画像処理(とくに機械学習のような高い階層のテンソルを扱う時)ではかなりレアケースだと思いますが、
pythonで描画ツールの作成であったり何かしら画像の中に文字を埋め込みたい!って時は注意が必要だったりします。
- OpenCV特有の前提
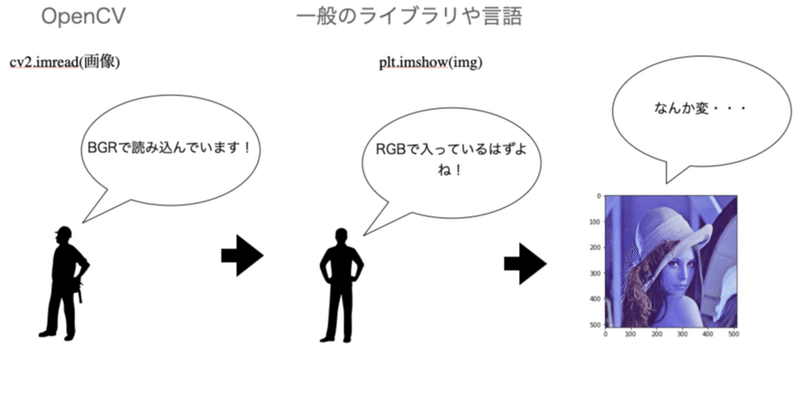
嫌というほどこれから出てくると思いますが、OpenCVでは色の順番がBGR となります。
我々がCSSであったり、その他スタイルを調整する時はRGB, rgbaが一般的ですが、なぜか反転しています。
これは後ほど見て行きます。
話を戻します。
今、出てきたarrayのshapeをとりあえず見てみます。
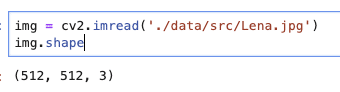
これはheight, width, チャネル数(※)で格納されています。
(※colorのBGRの数、r, g,b の3色の濃さ、輝度値、くらいで最初はいいです)
BGRのそれぞれの数値は0~255(uint8)を取っています。
(ちなみに、これ、いきなりテンソルですw)
・画像の表示
では、実際に画像を見たい時に表示する方法を見て行きます。
といっても実は今回cv2.imshow()とかもあるにはあるのですが、私の環境とopencvの相性が良くない(trackbarとかマウスポインタとかの挙動がおかしいw)ので、plt.imshowの方法をとっています。
plt.imshowはおそらく相関図とかをみるときに使いますが、画像の表示にも使えます。
plt.imshow(img)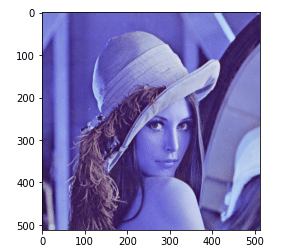
ここで、先程のOpenCV特有の問題が出てきます。
先ほども言ったように本来はRGBの順番で格納されている画像データですが、OpenCVはBGRの順番で読み込んでいます。
plt.imshow()ではRGBの順番で入っていると思い込んでいるので、なんか変ですよねw
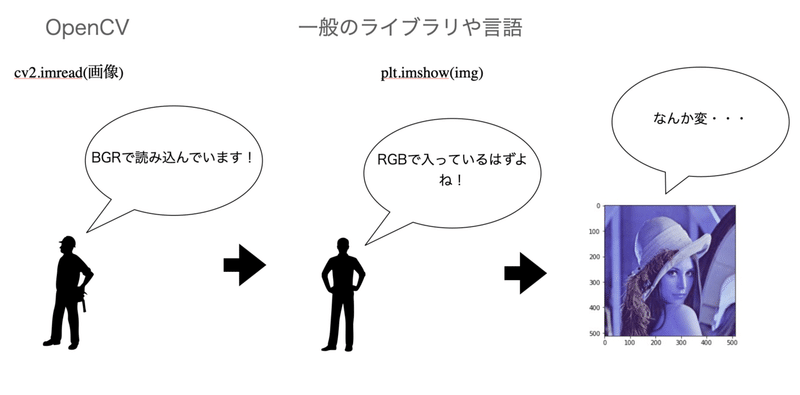
(cv2.imshowの場合通常の色彩で表示されるのですが、cv2.waitKeyとかdestroyWindows?とかを呼ぶ必要があるので、個人的にはpltの方が好きです・)
そのため、これらを正しく表示するにはcvtColor(convert color)で変換する必要があります。
img_cvt = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.imshow(img_cvt)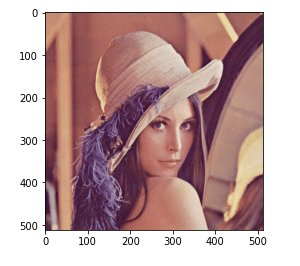
うまく表示されました!
これ以外にも大抵grayスケールで使うこともあるので、見て行きます。

(plt.imshowはデフォルトで色がつくので、ちゃんとgrayにしたい時はcmapでの指定が必要となります。)
- 画像切り取り
画像データがnumpy形式であるということはスライシングにより部分的に取得(つまり切り取り)ができるようになります。
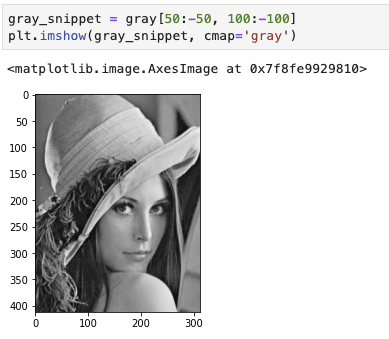
ちなみにこのような動作をcrop(クロップ)とかって言います
・画像の保存
保存にはnumpyなので、numpy.saveとかも使えますが、cv2.imwriteというメソッドがあるので、こちらを使ってみます。
cv2.imwrite('./data/train1/first_save.jpg', gray_snippet)
# 実際にできているか確認
import glob
glob.glob('./data/train1/first_save.jpg')![]()
ちなみに、これ厄介なのは、保存されている色の順番はRGBとなっていますw(つまり、RGBに変換してcv2.imwriteしてしまうと、実際の画像ではBGRとして表現されます。)
cv2での保存は混乱するので、基本的にはnumpyのarray形式での保存をしておくことが推奨されているそうです
・ヒストグラム
画像処理でヒストグラムというイメージが自分はまるでなかったのですが、RGBを数値として扱っているため、ヒストグラムでどの色が多いのか?(のちに行う二値化)などが重要な場面があります。
基本的には画素の大きさを表すものとなります。
実際にヒストグラムを直接的に扱うよりも裏で処理されることの方が多い気もしますが、扱っておきます。

# opencvで扱うため順番はBGRだがすでにcvtColorをしているため、RGBの順番であることを意識!!!
colors = ['green', 'red', 'blue']
for i, color in enumerate(colors):
hist = cv2.calcHist([img_cvt], [i], None, [256], [0, 256])
plt.plot(hist, color=color)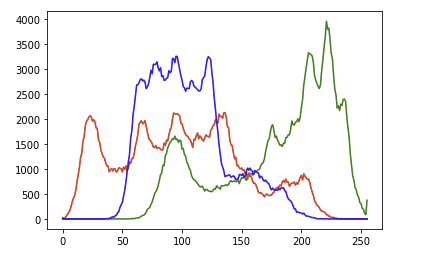
グラフの見方は
横軸: 画素値(0~255),
縦軸: 画素値の出現頻度
なので、赤は画素値の高いポイントが何回も出てきている、つまり全体的に赤が強いということが分かりますね
では、grayスケールでも行います
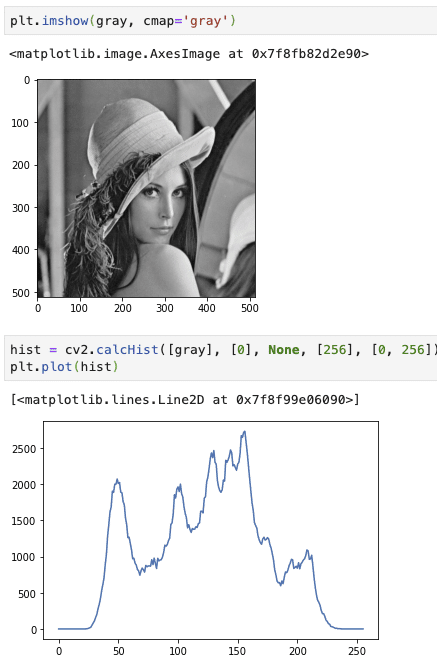
このGrayスケールのヒストグラムは二値化で閾値を決める際に使われます。
- ヒストグラムの均一化
では、この分布を均一にする処理を見て行きます。
opencvのequalizeHistというもので均一化してくれます。
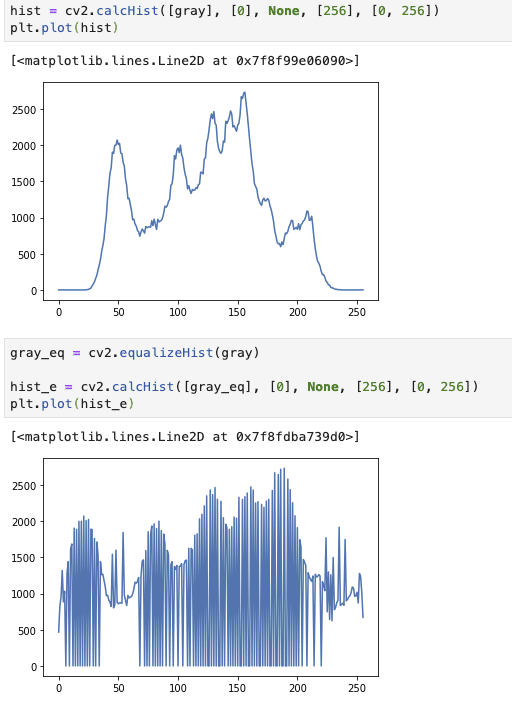
上記より、先ほどまでは両端の画素値の出現頻度が少なかったものの、均一化により数値が上がっていることが見て取れます。
実際に均一化された画像を見てみます。

見比べると、均一化されている方がくっきりとした印象のある写真になっているかと思います。
均一化されるということは画素値の非常に高い部分、低い部分の数値が上がるため、くっきりとした画像になりやすいわけですね!
- γ変換
こんなの初めましてだったんですが、基礎っぽいので扱います
γ変換は端的にいえば画像の明るさを変換する方法になります。
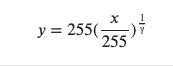
式も非常にシンプルですが、一応いろんなγで上記の関数をプロットすると以下。
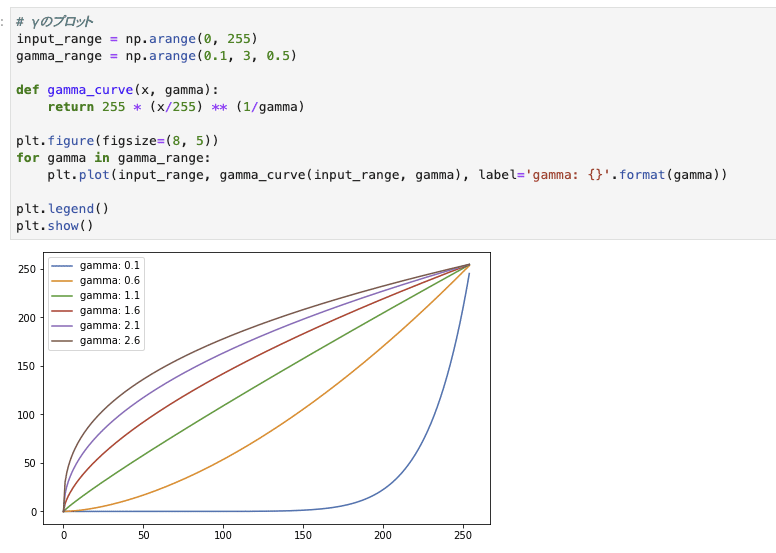
γが大きくなると画像が明るくなる
(数学的にいえば、x/255 ≦ 1でそれをγ乗根に入れるため)
では、画像を扱ってみてどうなるか見てみます。
自分はブルーベリーの画像を使いますが、普通にお好きな画像で試すのも面白いです。

γ変換すると
gamma = 1.5
gamma_cvt = np.zeros((256, 1), dtype=np.uint8)
for i in range(256):
gamma_cvt[i][0] = 255 * (float(i)/255) ** (1/gamma)
img_gamma = cv2.LUT(img, gamma_cvt)
img_gamma_cvt = cv2.cvtColor(img_gamma, cv2.COLOR_BGR2RGB)
plt.imshow(img_gamma_cvt) 
このLUT(look up table)は諧調変換(f: R -> R)の関数f(今回はγ関数)で変換された配列(1次元)を入れることでimgを変換してくれる関数となります。
γ変換の他にもネガポジ反転(y = 255 - x)とかもあります

腐ったでは到底済まされないようなブドウが誕生していますw
・二値化
- 代表的な画像の二値化
コードから見てみます。
reatval, dst = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)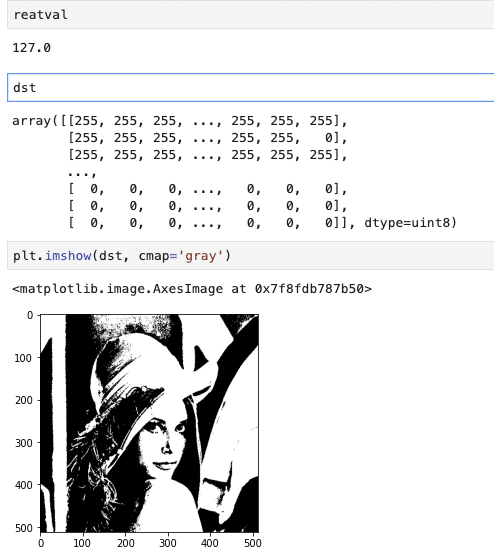
thresholdType = cv2.THRESH_BINARYにしているので
cv2.thresholdにより、閾値以上(今回は127)の値を超えている数値は全て指定した数値(今回は255)にして、のこりは全て0で返すようにします。
ちなみに今回は127としていますが、実際に画像を一枚一枚みていって的確なthresholdを見つけるなんてのは現実的ではないので、色々なアプローチが研究されています。
- 大津の二値化
これは輝度値のヒストグラムから閾値を自動で決定してくれるものです。
裏の処理としてLDA(Linear Discriminant Analysis)が使われていますが、簡単にいえば二つの山からなるヒストグラムを線形モデルでスパッと二つにわけれそうな場所を決めよう!ってやつです。
特に今時点でこれを知らないと進めないわけでもないと思うので、興味ある方は以下を。
具体的に大津の二値化が使えるような時を見てみます。
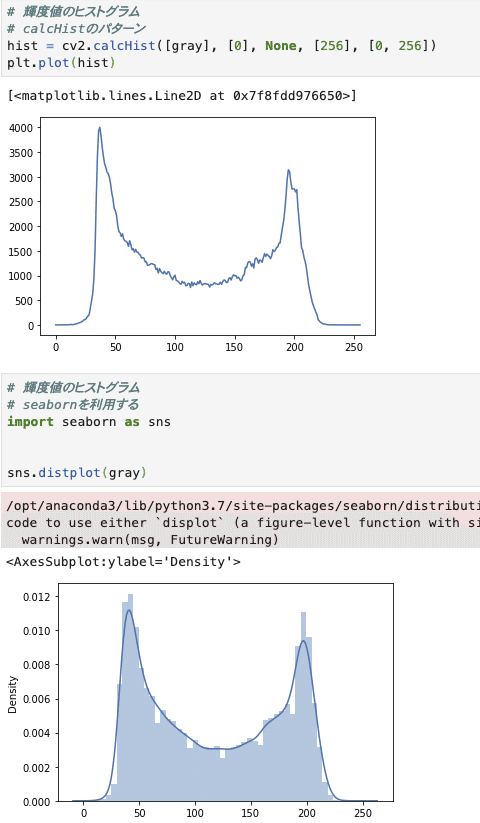
このヒストグラムのように、双峰性があるようなヒストグラムに有効な処理となります。
では、大津の二値化をしてみます。
ret, dist = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY+cv2.THRESH_OTSU)この辺はかなりテンプレート的な部分なので、特にポイントなどはあまりないです
実際にretを見ていくと同時にどうわけられているのかグラフでも確認します
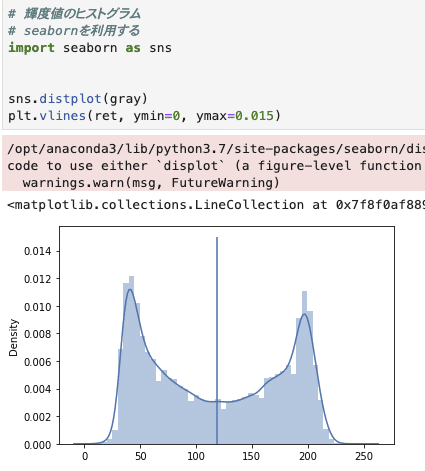
実際に閾値が自動で決まっていることが分かりました。
では、どう変わっているのか画像で直接確認してみます。
かなりはっきりと白黒に分かれた感じかなと思います
- Adaptive Tresholding
今までは全体を二値化してきました(global threshold)。
しかし、部分的な二値化したいときにこのAdaptive Tresholdingを使うことになります。
これをすることにより、文字だけはっきりさせたいとか、背景だけ暗くしたいみたいことができます
では、見て行きます。
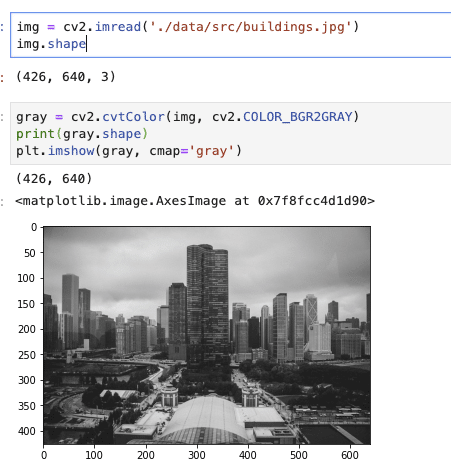
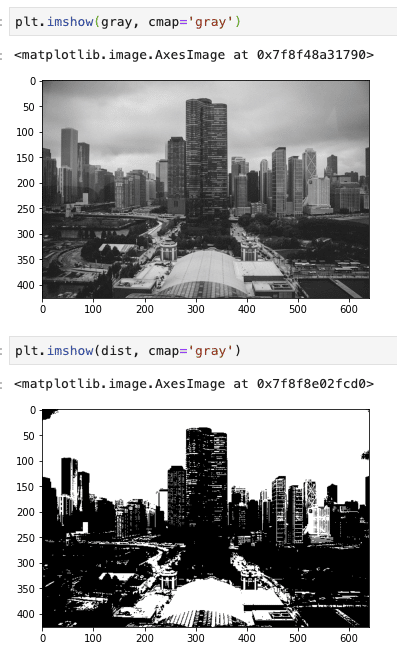
まず扱う画像から。
img = cv2.imread('text_pic.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
plt.imshow(gray, cmap='gray')
ではAdaptiveを実行!
dst = cv2.adaptiveThreshold(gray, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 15, 4)
plt.imshow(dst, cmap='gray')
くっきりとテキストだけが見えてきました
ちょっとパラメータをいじってみます。
adaptiveThreshold(src, maxValue, adaptiveMethod, thresholdType, blockSize, C)
パラメータを少しだけ解説すると、
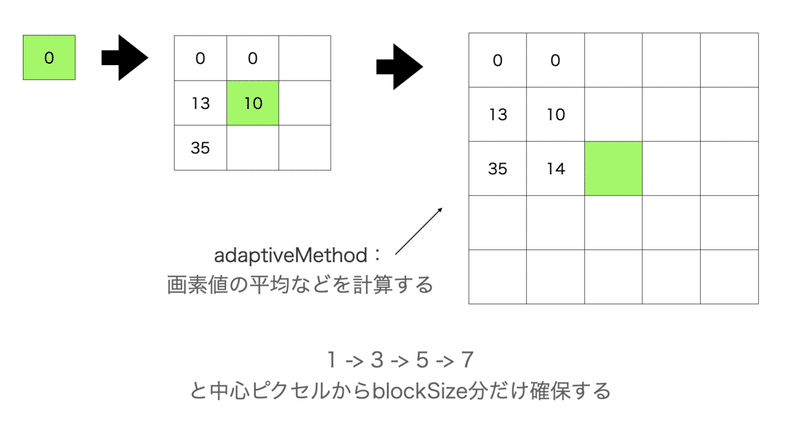
adaptiveMethodで閾値の計算方法を定義します。
今回は近傍画素値の平均値を閾値としています。
近傍画素値とは中心ピクセルから決められたblockSizeだけ広げていく状況を意味します。
図示した方がわかりやすいですので、以下。
まずはCから。
このCは、計算した閾値からCを引いた値を最終的な閾値にするため、閾値の調整が行われます。

=4 くらいであればよりCの数値を上げればよりくっきりするようになりました
次にblocksizeを変えてみました。
import itertools
fig, axes = plt.subplots(2, 2, figsize=(12, 12))
blocksize_list = [3, 11, 15, 21]
axes_axis = itertools.product([0, 1], [0, 1])
range_ax = zip(blocksize_list, axes_axis)
for i, ax in range_ax:
# Cの値を変化させてみる
dst= cv2.adaptiveThreshold(gray, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, i, 4)
axes[ax[0], ax[1]].imshow(dst, cmap='gray')
axes[ax[0], ax[1]].set_title(f'blocksize = {i}')
blocksizeに関しては11くらいの方がやや鮮明かな〜くらいですが、そこまで劇的な差はない印象ですね。
・一旦終わり
早くtransformerを扱いたいのですが、重いので気分転換に画像処理が続くかもですw
どうせ機械学習の部分も扱うつもりなので、初めてだった方は一緒に練習していきましょう〜
この記事が気に入ったらサポートをしてみませんか?