
kaggle初心者の2ステップ目【ieee】



こいつを読んでディープラーニングを完全に理解した私ですが、やはり実践の場に出ると何も役に立ちません。アンサンブルってどうやるんだ???データ拡張ってこれで合ってるのか???もはやReLU関数がどうこうではありません。
恐るべしkaggle...
人のカーネルを参考にして提出するところまではu++先生の記事を読んでやってみました。
ただしせっかちな私は拾い読み。当然画像認識制度を向上させるなんてどうやったら良いかわかりません。そんな中、駆け足で鉄コンペに飛び込んでしまったのです。
ただ鉄コンペは提出物に難しさを感じて、初心者の2ステップ目としては難しく感じました。画像の中のどの箇所が検知するべき箇所なのかを表現しなくてはいけないのです。

初心者としてはアウトプットが0、1であってくれると嬉しき。。。タイタニックみたいに。

そんなとき、ieeeに出会いました。予測結果がレコードに対してスカラー値で済みます。なんか予測している実感が湧きます。初心者には。
また表形式のデータから予測するのは、タイタニックそのものではないですか。(タイタニックはkaggleのチュートリアルの代表です)
どのデータを特徴として選択するかによって精度を向上させられます。
これはやりやすい。そう思った私はこちらにieeeに乗り換えました。

そして私が参考にしたカーネルはこちらでした。
使用するデータやlight gbmのパラメータは、なぜそうしているか別途理解する必要がありますが(中には書かれていなかったが他のカーネルに色々書かれていたりする)、かなりシンプルなカーネルだと思います。
データに直接触れていて、パラメータチューニングや特徴量選択の余地があってかなり1次情報に近い感じだと思っています。

ieee舐めてしました。アヤメの花の学習をsklearnで終えたカンゼンニリカイシタボーイの私は見事打ち砕かれます。
時系列データを整形し、意味のあるデータ同士を組み合わせて新しいデータを生成し抜粋します。データに対する理解を深めるための努力を惜しまずに可視化・データの背景の勉強をできるものが正しいデータを選ぶことができます。
私は時間も少なかったのと、汎用的に使える技術を学んでおきたくOptunaとfeature toolsを使うことにしました。
ですが、最後に勝利するにはデータの意味と背景を知っておくことはマストです。
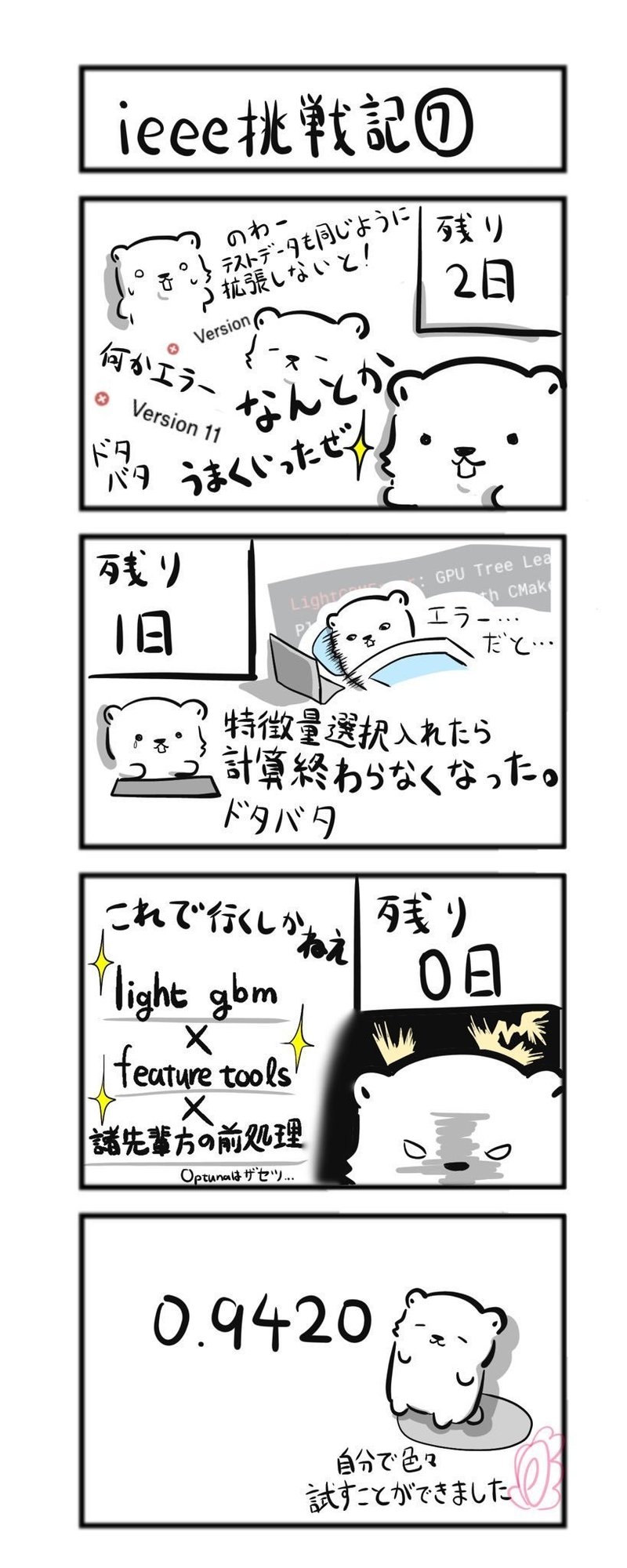
で、結局残りの日数も少なく、Optunaは使いこなせませんでした。
しかしFeaturetoolsは試すことができました。実際に特徴量を増やして特徴量に何もしない時の0.9384から0.9420にスコアを向上させることができました。
休日や仕事後のドタバタの中、まあまあ携わることができたのでとてもよかったです。
これからはフットボールコンペに取り組もうと思っていますが、その前に例の本をポチりました。
これでまたじっくりと勉強しながら挑戦を続けようと思います。
初心者記事をここまでお読みいただき本当にありがとうございました。
今後もわかりやすく描いていきます。そしてレベルアップも続けてより有益な記事になるようにがんばりますので、よろしくお願いいたします。
この記事が気に入ったらサポートをしてみませんか?