Pandas でよく忘れてしまう事柄(随時追加)

Pythonを使ったデータ解析をする際によく忘れてgoogle検索しがちなものを下記に書き留めておく(随時追加予定)
Excelファイルのimport(read_excel)
'xlrd'をインストールすると下記方法でxlsxファイルをデータフレームとして読み込み可能
pd.read_excel('filename.xlsx')Excelファイルのexport(to_excel)
下記でデータフレーム(df) をファイル(output_file.xlsx)に書き出
(index = False でインデックスを除外)
df.to_excel('output_file.xlsx', index = False)ファイル名に日付/時間(アジア圏)を挿入
from datetime import datetime
from pytz import timezone
date_now = datetime.now(timezone('Asia/Tokyo')).strftime("%Y%m%d_%H%M")
print(date_now)
日付と時間(YYMMDD_HHMM)が出力されるはず。
dataframe (df) を'filename_yymmdd_HHMM.xlsx'という名前に出力する:
df.to_excel('filename_' + date_now +'.xlsx') --end--(06/03/2019)
データ概要を見る
行・列の数df.shape
df.shapeデータの概要df.info()
df.info()(数値)データの統計量(count, mean, std, etc)
df.describe()(文字)データの統計量(df.describe())
count:データの数,unique:重複を除いたデータ数,top:最も多いデータ,freq:topのデータが含まれる数などを常時
df.describe(include='O') # 0(ゼロ)じゃなくてO(オー)(数値・文字)データの統計
df.describe(include='all')
df.describe(include='all')カラム・インデックスと特定の名前を変更(rename)
column名'a'を'colA'に変更
df.rename(columns={'A': 'Col_1'})index名'a'を'ROWa'に変更
df.rename(index={'a': 'ROWa'}カラム名取得・一括変更(df.columns)
df.columns一括変更 (4列のデータフレームのそれぞれを'a', 'b', 'c', 'd'に変更する)
df.columns = ['a','b','c','d']--end--(06/04/2019)
列情報の取得(unique(),nunique(),value_counts())
列'a'が含む変数の種類を調べる:unique()
df['a'].unique()列'a'が含む変数の種類数を調べる:nunique()
df['a'].nunique()列'a'に含まれるそれぞれの変数がいくつあるかを調べる: value_counts()
df['a'].value_counts()--end--(06/05/2019)
インデックス振り直し(reset_index())
元のインデックスは新たなcolumnとして残る
df.reset_index()元のインデックスを削除するには"drop=True"をつける
df.reset_index(drop=True)--end--(04/28/2020)
NaN関連
df内のNaNを探す
df.isna().any() df内のNaNを特定の数字(例: 0)に変換
df.fillna(0)df内のNaNを含む行を落とす
df.dropna(axis = 0)--end--
dictionaryからdataframeへの変換
a = {'name':['a','b','c','d'],'value':[1,2,3,4]}
df = pd.DataFrame(a) これで4行2列のdataframe作成ができる(下記)
In [6]: df
Out[6]:
name value
0 a 1
1 b 2
2 c 3
3 d 4--end--
列と列のLog計算
● math モジュールのlog()をつかって計算
● log(x, a) x:変数,a:底を指定
● 下記例ではb列の各数値についてlog2(b)を計算した数値の列を新たに作成
# Data frameの作成
df = {'a':['a','b','c','d'],'b':[1,2,3,4]}
df = pd.DataFrame(df)
df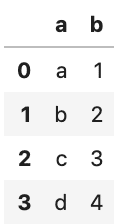
# log2(x)の計算
import math
df['log2(b)'] = df['b'].apply(lambda x: math.log(x,2))
df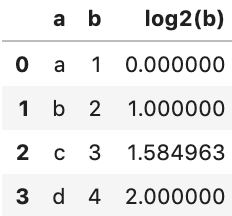
(続き)四捨五入の方法
● Python3のround()は偶数に丸めるためのもので,四捨五入ではない
● Decimal()を使って四捨五入
Decimal(x).quantize(Decimal('0.01'), rounding=ROUND_HALF_UP))
xに四捨五入する数値を入れて,ケタ数をDecimal('x.xx')で指定する
● 数値はDecimal型(固定小数点数型)で出力される
# 例
from decimal import Decimal, ROUND_HALF_UP, ROUND_HALF_EVEN
Decimal(0.3333333333).quantize(Decimal('0.01'), rounding=ROUND_HALF_UP)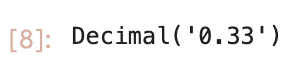
# 例2:データフレーム内で列単位で四捨五入
from decimal import Decimal, ROUND_HALF_UP, ROUND_HALF_EVEN
df['log2(b)'] = df['log2(b)'].apply(lambda x: Decimal(x).quantize(Decimal('0.01'), rounding=ROUND_HALF_UP))
df
--end--(05/12/2020)
特定の文字で列を分割 (str.split)
●コロンなどの特定の記号で列を分割する
# データフレーム作成
df = {'a':['a:4','b:3','c:2', 'd:1'],'b':[1,2,3,4]}
df = pd.DataFrame(df)
df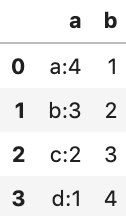
# コロンで分割
df = df['a'].str.split(':', expand=True)
df
# 複数の列に分割してデータフレームとして取得するには、引数expand=Trueを指定する
# bの行は消え, columnameが新たに0と1になる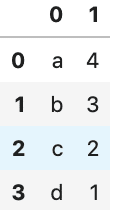
(続き)特定の文字を置き換える replace
● 列内の特定の文字を置き換える replace(a, b)
● cをYにdをZに置き換えるなど複数の場合は辞書を使う
replace({'c': 'Y', 'd': 'Z'})
df[0] = df[0].replace({'c':'Y', 'd':'Z'})
df

--end--(05/12/2020)
この記事が気に入ったらサポートをしてみませんか?