Scipyのcurve_fitを使用した非線形曲線Y=ax/x+bへの近似方法
はじめに
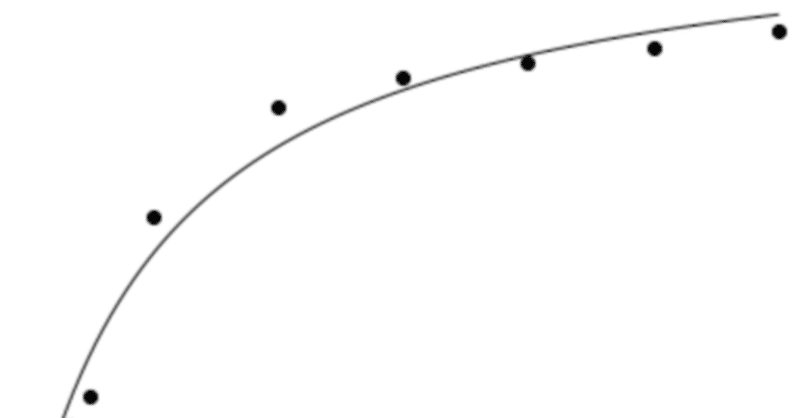
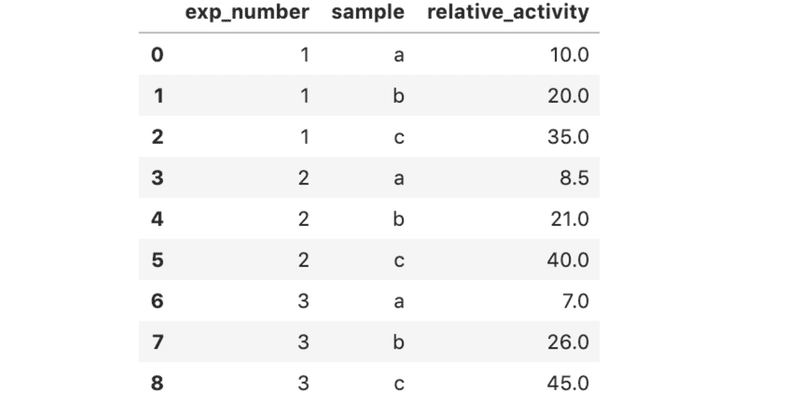
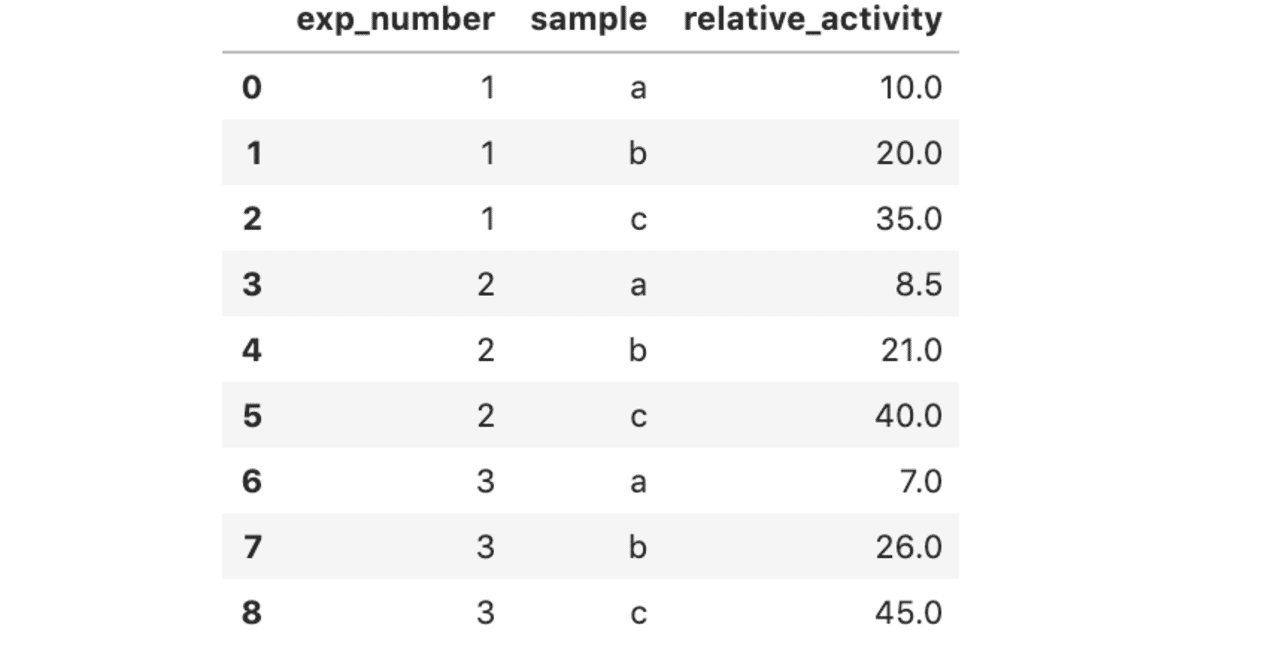
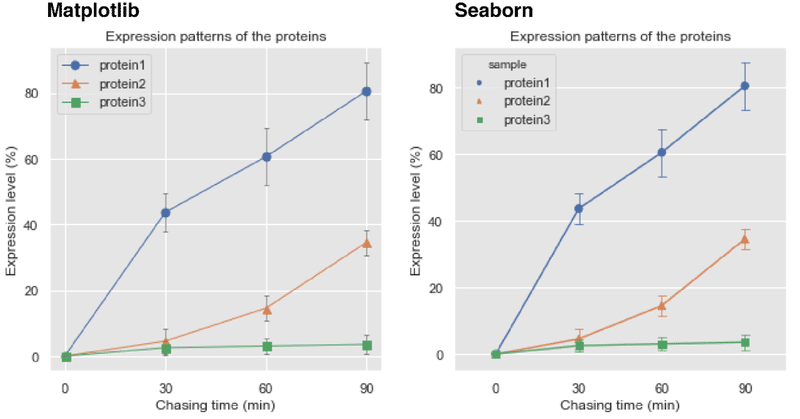
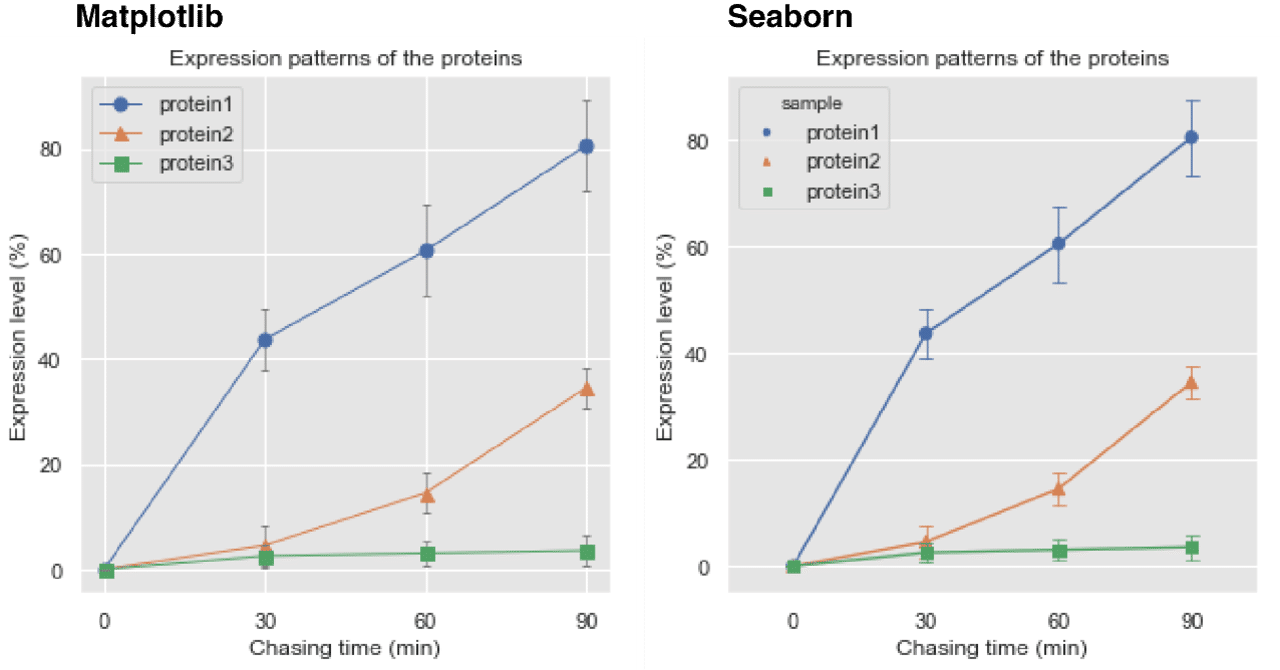
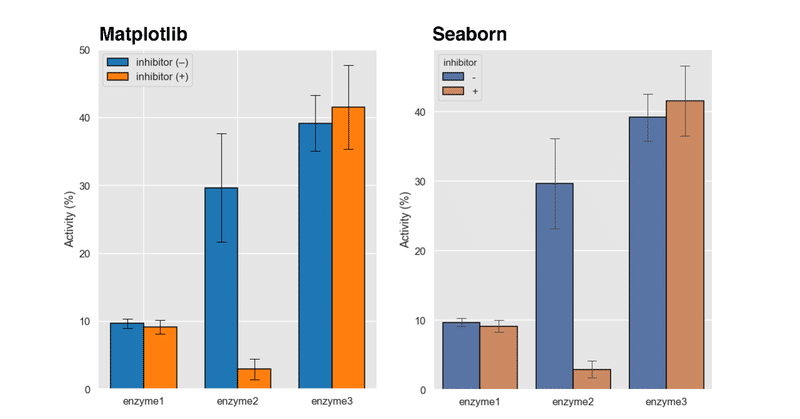
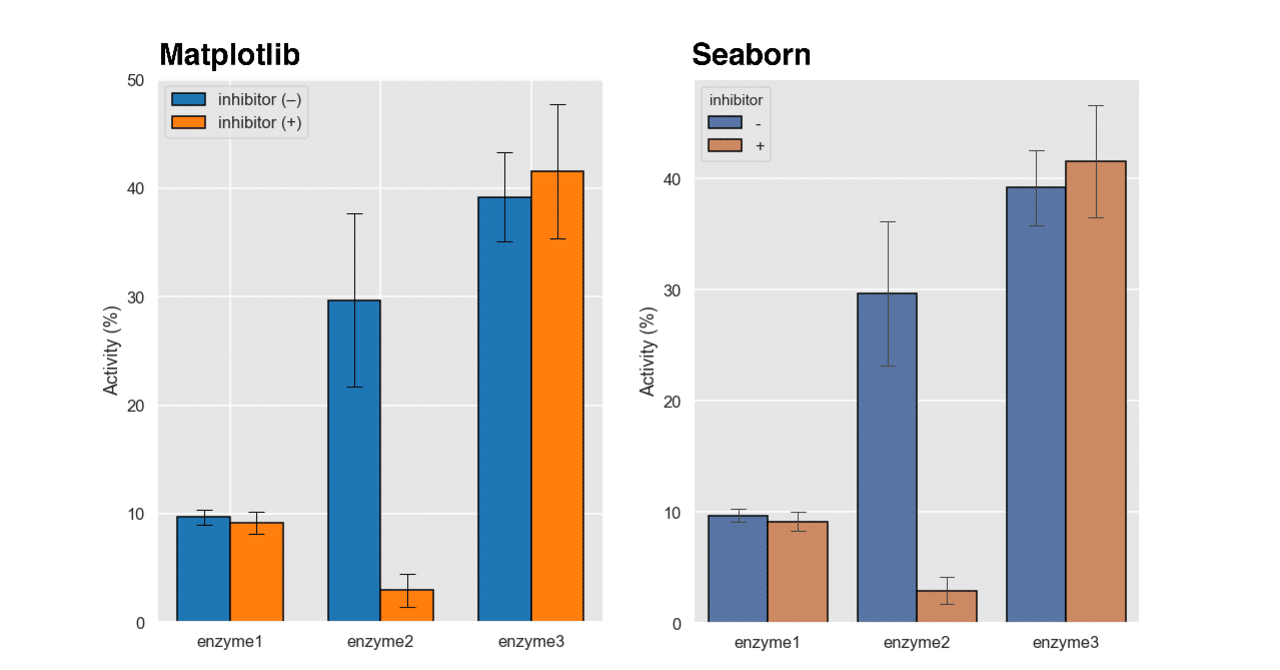
生化学でよく出てくる酵素反応の経時変化を,下記の式への近似する。
まずはモジュールのimport
# import moduleimport numpy as npimport matplotlib.pyplot as plt
数値例を作成
(X値,0から360までの範囲で,上記のような曲線に近いY値が得られたという想定)。
X = [0,10,20,30,60,120,180,240,300,360]y = [0,6,15,19,43,58,62,64,