
Advanced Data Analysis(旧Code Interpreter)で何ができるのか試してみた

7月7日、OpenAIがChatGPT Plusの公式プラグインとしてCode Interpreter(8月にAdvanced Data Analysisに名称変更)の提供を開始しました。
Code Interpreterを利用することにより、ChatGPT上でPythonコードを生成、実行したり、ファイルをアップロード・ダウンロードしたりすることができます。
以前、ChatGPTのデータ分析プラグインのNoteableで、簡単な算数の問題を解いたり、データ分析をしたりしましたが、Code Interpreterでも同じことができるのかどうか確かめてみました。
1.Code Interpreterの概要と使い方
(1) Code Interpreterの概要
Code Interpreterは、ChatGPTの機能を拡張する公式プラグインであり、以下のようなことができます。
Pythonコードの生成、実行、結果の出力
データのアップロード、編集、ダウンロード
アップロードしたデータを利用したデータ分析
データ分析結果を可視化するためのグラフの作成
なお、アップロード可能なデータサイズは500MBまで、1セッションで使用可能なストレージ容量は3GBまでに制限されています。
(2) 利用方法
Code Interpreterを利用するには、ChatGPT Plusの操作画面で、左下のアカウント名をクリックし、Settingsを選択してください。
そして、以下の設定画面で、Beta featuresを選択し、Code interpreterのトグルボタンをオンにしてください。

次に、操作画面でNew chatを開いて、GPT-4を選択し、Code Interpreter Betaをクリックしてください。すると、GPT-4の横に紫色のマークが付き、Code Interpreterがセットされた状態になります。

入力欄の左端にある「+」マークをクリックすると、データファイルなどをアップロードすることができます。
2.100までの素数を求める
Code InterpreterをセットしたChatGPTに100までの素数を求めてもらいました。
(1) 入力プロンプトとChatGPTの回答
100までの素数を求めてください。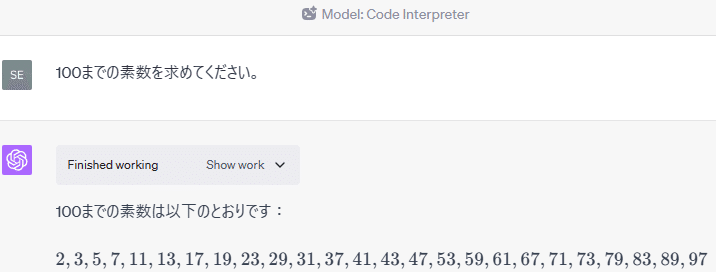
(2) 自動生成されたコード
Show workを開くと、以下のようなコードが自動生成されていました。
def is_prime(n):
if n <= 1:
return False
if n == 2:
return True
if n % 2 == 0:
return False
i = 3
while i * i <= n:
if n % i == 0:
return False
i += 2
return True
primes = [n for n in range(101) if is_prime(n)]
primesこのように、Code Interpreterは、入力したプロンプトの内容から判断して、自動でPythonコードを生成して実行し、回答を出力することができます。
3.鶴亀算を解く
Code InterpreterをセットしたChatGPTに鶴亀算を解いてもらいました。
(1) 入力プロンプトとChatGPTの回答
鶴の足は2本、亀の足は4本です。鶴と亀の合計は5匹で、足の数を合計すると14本です。
その場合、亀は何匹いますか?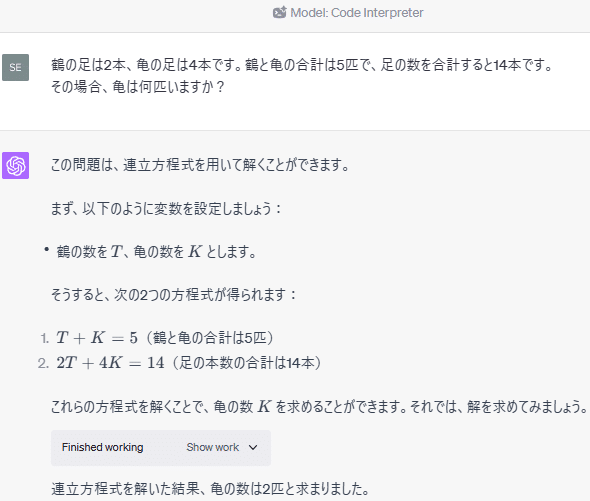
(2) 自動生成されたコード
Show workを開くと、以下のようなコードが自動生成されていました。
from sympy import symbols, Eq, solve
T, K = symbols('T K')
# Define the equations
eq1 = Eq(T + K, 5)
eq2 = Eq(2*T + 4*K, 14)
# Solve the system of equations
solution = solve((eq1,eq2), (T, K))
solution[K]
RESULT
2(3) 解法の可視化(グラフの作成)
さらに、この問題の解法を可視化してもらいました。
この問題の解法を可視化してください。グラフを書く際に、タイトルや説明書きはすべて英語にしてください。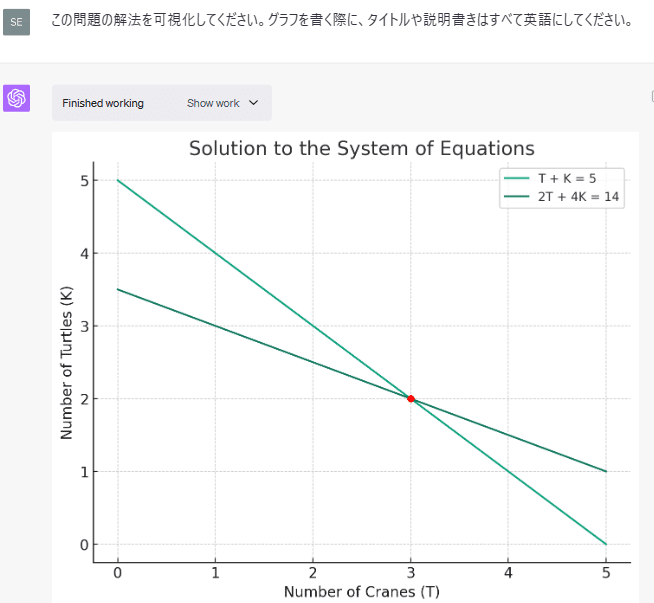

グラフに表示される文字が日本語だと上手く表示できなかったため、英語で表示するように指示しました。その後、説明書き部分だけ日本語訳しています。
このグラフを書くためにCode Interpreterが自動生成したコードは以下のとおりです。
import matplotlib.pyplot as plt
import numpy as np
# Generate a range of values for T
T_values = np.linspace(0, 5, 400)
# Calculate corresponding K values for each equation
K_values_eq1 = 5 - T_values
K_values_eq2 = (14 - 2 * T_values) / 4
# Create the plot
plt.figure(figsize=(8, 6))
plt.plot(T_values, K_values_eq1, label='T + K = 5')
plt.plot(T_values, K_values_eq2, label='2T + 4K = 14')
plt.plot(solution[T], solution[K], 'ro') # solution point
# Add labels, title, and legend
plt.xlabel('Number of Cranes (T)')
plt.ylabel('Number of Turtles (K)')
plt.title('Solution to the System of Equations')
plt.legend()
# Show grid
plt.grid(True)
# Show the plot
plt.show()このように、簡単な指示でグラフを書いてもらうこともできます。
4.ポケモンの強さを比較する
Code InterpreterをセットしたChatGPTに、ピカチュウとヒトカゲとゼニガメの強さを比較してもらいました。
(1) 入力プロンプトとChatGPTの回答
ピカチュウとヒトカゲとゼニガメの強さを比較するグラフを作成してください。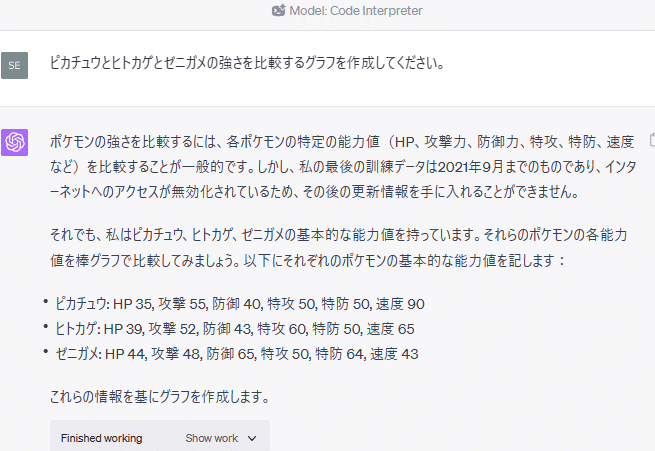
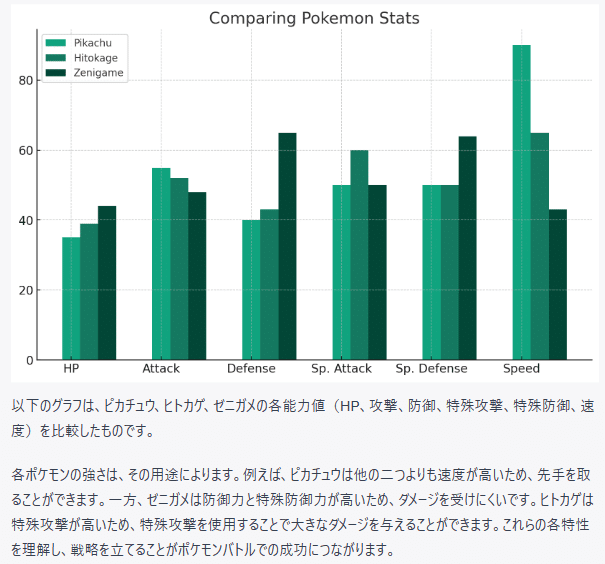
この棒グラフを描くためにCode Interpreterが自動生成したコードは以下のとおりです。
import matplotlib.pyplot as plt
import numpy as np
# define the data
pokemon_names = ['Pikachu', 'Hitokage', 'Zenigame']
stats = ['HP', 'Attack', 'Defense', 'Sp. Attack', 'Sp. Defense', 'Speed']
values = np.array([
[35, 55, 40, 50, 50, 90], # Pikachu
[39, 52, 43, 60, 50, 65], # Hitokage
[44, 48, 65, 50, 64, 43] # Zenigame
])
# create a figure and axes
fig, ax = plt.subplots(figsize=(10, 6))
# plot the data
X = np.arange(len(stats))
for i in range(len(pokemon_names)):
ax.bar(X + 0.2*i, values[i], width = 0.2, label = pokemon_names[i])
# set the x ticks and labels
ax.set_xticks(X)
ax.set_xticklabels(stats)
# adding legends
plt.legend()
# adding title
plt.title('Comparing Pokemon Stats')
# Show the graph
plt.show()(2) レーダーチャートの作成
さらに、各ポケモンの特徴が一目で分かるようにレーダーチャートも作成してもらいました。
この結果をレーダーチャートで表してください。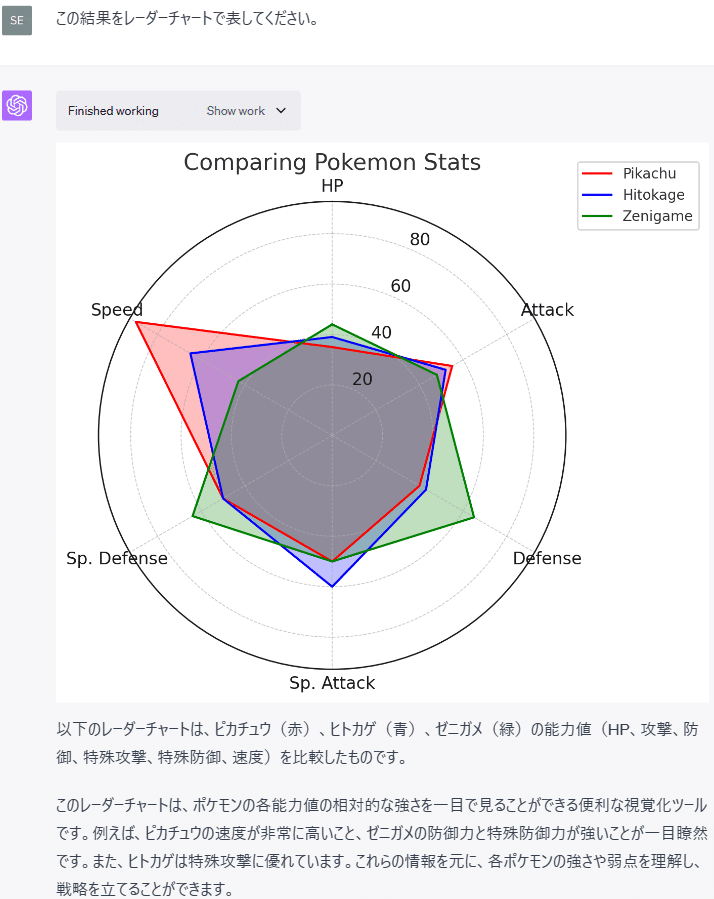
このレーダーチャートを描くためにCode Interpreterが自動生成したコードは以下のとおりです。
# Create a radar chart
# Number of variables we're plotting.
num_vars = len(stats)
# Compute angle of each axis.
angles = np.linspace(0, 2 * np.pi, num_vars, endpoint=False).tolist()
# The plot is a circle, so we need to "complete the loop"
# and append the start to the end.
values = np.concatenate((values,values[:,[0]]), axis=1)
angles += angles[:1]
# Create figure.
fig, ax = plt.subplots(figsize=(6, 6), subplot_kw=dict(polar=True))
# Helper function to plot each Pokemon on the radar chart.
def add_to_radar(pokemon, color):
values_temp = values[pokemon]
ax.fill(angles, values_temp, color=color, alpha=0.25)
ax.plot(angles, values_temp, color=color, label=pokemon_names[pokemon])
# Add each additional pokemon to the chart.
add_to_radar(0, 'red')
add_to_radar(1, 'blue')
add_to_radar(2, 'green')
# Title and legend
plt.title('Comparing Pokemon Stats')
ax.legend(loc='upper right', bbox_to_anchor=(1.3, 1.1))
# Fix axis to go in the right order and start at 12 o'clock.
ax.set_theta_offset(np.pi / 2)
ax.set_theta_direction(-1)
# Draw axis lines for each angle and label.
ax.set_thetagrids(np.degrees(angles[:-1]), stats)
plt.show()このように、データを基に様々なグラフを作成することができ、グラフの見方も示してくれます。
(3) ポケモン画像の表示
ちなみに、Wolframプラグインは、以下のようにポケモンの画像を表示することができます。
ピカチュウとヒトカゲとゼニガメの画像を示してください。
5.日本各地のお天気情報を調べる
Code InterpreterをセットしたChatGPTに日本各地の今日の天気を調べてもらいました。
(1) ネット経由のデータ取得について
https://api.open-meteo.com/v1/forecastから東京の天気予報の情報を入手して、絵文字付きで、元気なお天気お姉さん風に伝えてください。
current_weatherのパラメータを使用してください。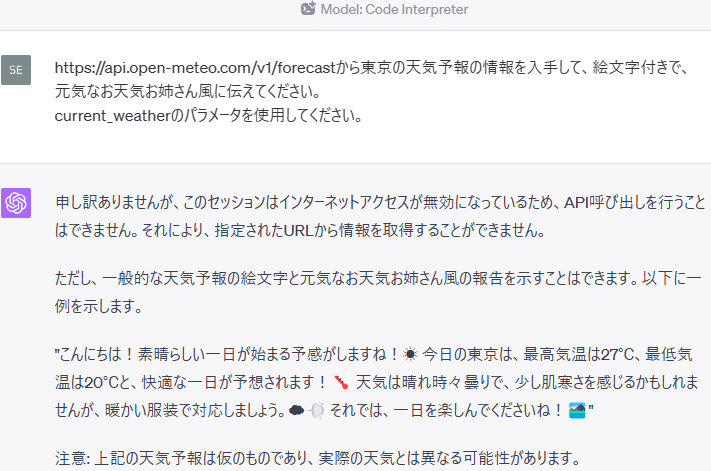
このように、Code InterpreterをセットしたChatGPTは、インターネットアクセスができないため、APIを経由した情報の取得ができません。
したがって、ユーザーが自分でデータを集めてChatGPTにアップロードする必要があります。
(2) 最新の気象データの入手
そこで、気象庁のホームページから最新の気象データを入手することにしました。今回は、以下のページから全国各地の6時間ごとの降水量のデータのCSVファイルをExcel形式で入手しました。
(3) データのアップロードと入力プロンプト
まず、ChatGPTの操作画面でNew chatを開いて、GPT-4とCode Interpreterをセットします。
次に、入力欄の左端の「+」マークをクリックして、先程入手したデータファイル(ファイル名は「全国の降水量」に変更)を選択します。
そして、以下のプロンプトを入力して実行ボタンをクリックします。
全国の降水量のデータを基に、最新の関東地方の各都道府県のお天気の概況を絵文字付きで、元気なお天気お姉さん風に伝えてください。なお、降水量と天気の関係は自分で考えてください。(4) ChatGPTの回答

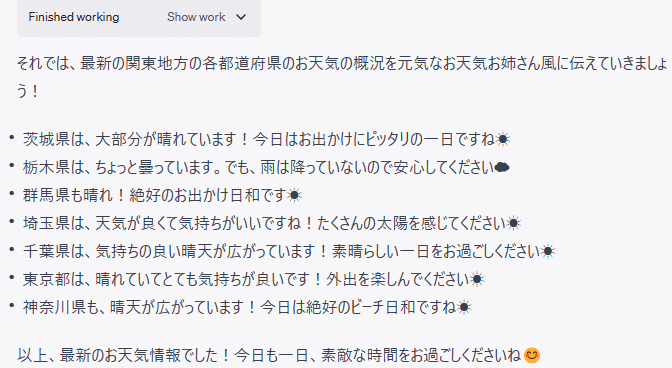
(5) 自動生成されたコード
最初に全国の降水量データファイルから情報を入手するためにCode Interpreterが生成したコードは以下のとおりです。
import pandas as pd
# Load the data
rainfall_data = pd.read_excel("/mnt/data/全国の降水量.xlsx")
# Display the first few rows of the data
rainfall_data.head()
RESULT
観測所番号 都道府県 地点 国際地点番号 現在時刻(年) 現在時刻(月) 現在時刻(日) \
0 11001 北海道 宗谷地方 宗谷岬(ソウヤミサキ) NaN 2023 7 8
1 11016 北海道 宗谷地方 稚内(ワッカナイ) 47401.0 2023 7 8
2 11046 北海道 宗谷地方 礼文(レブン) NaN 2023 7 8
3 11061 北海道 宗谷地方 声問(コエトイ) NaN 2023 7 8
4 11076 北海道 宗谷地方 浜鬼志別(ハマオニシベツ) NaN 2023 7 8
現在時刻(時) 現在時刻(分) 現在値(mm) ... 昨日までの観測史上1位の値の品質情報 昨日までの観測史上1位の値の年 \
0 13 40 0.0 ... 8 2020
1 13 40 0.0 ... 8 2020
2 13 40 0.0 ... 8 2014
3 13 40 0.0 ... 8 2003
4 13 40 0.0 ... 8 2020
昨日までの観測史上1位の値の月 昨日までの観測史上1位の値の日 昨日までの7月の1位の値(mm) 昨日までの7月の1位の値の品質情報 \
0 8 7 76.0 8
1 8 7 75.0 8
2 8 24 63.5 8
3 8 8 49.5 8
4 8 7 66.0 8
昨日までの7月の1位の値の年 昨日までの7月の1位の値の月 昨日までの7月の1位の値の日 統計開始年
0 1990 7 25 1978
1 1990 7 25 1976
2 2018 7 15 2003
3 2019 7 27 2003
4 2015 7 13 1978
[5 rows x 29 columns]
次に関東地方の各都道府県のデータを取得するためにCode Interpreterが生成したコードは以下のとおりです。
# Define the prefectures in the Kanto region
kanto_prefectures = ["茨城県", "栃木県", "群馬県", "埼玉県", "千葉県", "東京都", "神奈川県"]
# Filter the data for the Kanto region
kanto_data = rainfall_data[rainfall_data['都道府県'].str.contains('|'.join(kanto_prefectures))]
# Display the filtered data
kanto_data最後に、降水量から天気を推測するためにCode Interpreterが生成したコードは以下のとおりです。
# Define the relationship between rainfall and weather
def get_weather(rainfall):
if rainfall == 0:
return "晴れ ☀️"
elif 0 < rainfall <= 1:
return "曇り ☁️"
elif 1 < rainfall <= 5:
return "小雨 ☔"
else:
return "大雨 🌧️"
# Apply the function to the data
kanto_data["天気"] = kanto_data["現在値(mm)"].apply(get_weather)
# Group the data by prefecture and get the most common weather
kanto_weather = kanto_data.groupby("都道府県")["天気"].agg(lambda x: x.value_counts().index[0])
kanto_weather
RESULT
都道府県
千葉県 晴れ ☀️
埼玉県 晴れ ☀️
東京都 晴れ ☀️
栃木県 曇り ☁️
神奈川県 晴れ ☀️
群馬県 晴れ ☀️
茨城県 晴れ ☀️
Name: 天気, dtype: object(6) 九州地方の天気
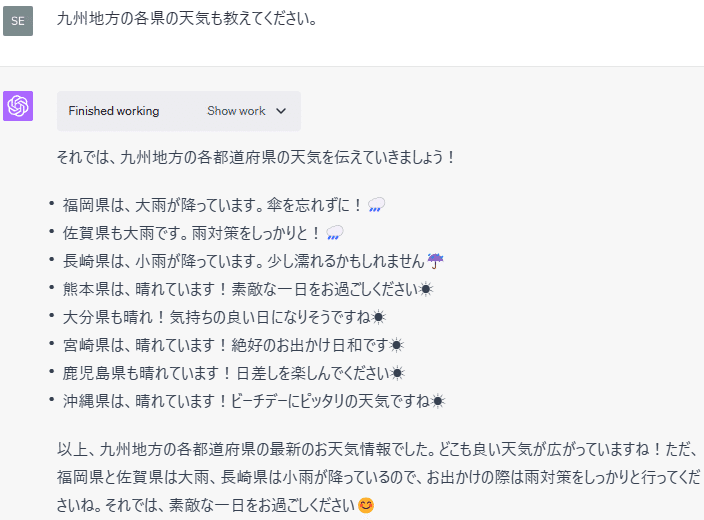
九州の天気を伝えるためにCode Interpreterが自動生成したコードは以下のとおりです。
# Define the prefectures in the Kyushu region
kyushu_prefectures = ["福岡県", "佐賀県", "長崎県", "熊本県", "大分県", "宮崎県", "鹿児島県", "沖縄県"]
# Filter the data for the Kyushu region
kyushu_data = rainfall_data[rainfall_data['都道府県'].str.contains('|'.join(kyushu_prefectures))]
# Apply the function to the data
kyushu_data["天気"] = kyushu_data["現在値(mm)"].apply(get_weather)
# Group the data by prefecture and get the most common weather
kyushu_weather = kyushu_data.groupby("都道府県")["天気"].agg(lambda x: x.value_counts().index[0])
kyushu_weather
RESULT
都道府県
佐賀県 大雨 🌧️
大分県 晴れ ☀️
宮崎県 晴れ ☀️
沖縄県 晴れ ☀️
熊本県 晴れ ☀️
福岡県 大雨 🌧️
長崎県 小雨 ☔
鹿児島県 晴れ ☀️
Name: 天気, dtype: objectこのように、適切なデータを用意すれば、Code Interpreterがそのデータを分析して、求められた結果を出力することができます。
但し、Noteableプラグインのように、APIを経由してネットからデータを取得することができないのは少し残念です。この点は、今後改善されないのでしょうか。
6.大谷選手の成績を分析する
ロサンゼルス・エンゼルスの大谷翔平選手の成績をCode InterpreterをセットしたChatGPTに分析してもらいました。
(1) 大谷選手の成績データの入手
必要なデータは、メジャーリーグの歴史に登場するすべての選手の野球統計データを提供するBaseballReferenceのWebサイトから入手します。
具体的には、以下の大谷選手のページから、2018年から2023年までの6年間のStandard BattingとStandard Pitchingの成績データファイルをExcel Workbook形式でダウンロードして入手しました。
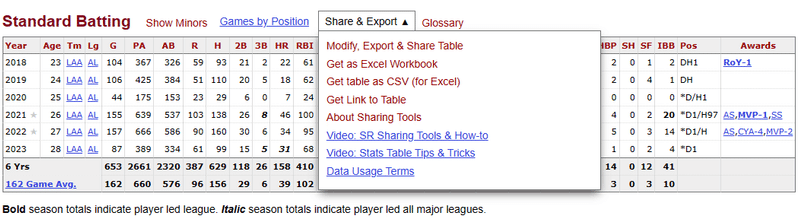
各成績データの表のShare & Exportを選択し、Get as Excel Workbookをクリックして、データファイルをダウンロードします。
(2) 大谷選手の打者成績の分析
まず、New chatを開いて、Code Interpreterをセットします。
次に、入力欄の左端の「+」マークをクリックして、Standard Battingのデータを選択します。
そして、以下のプロンプトを入力して実行ボタンをクリックします。
大谷選手の打者成績の傾向を分析してください。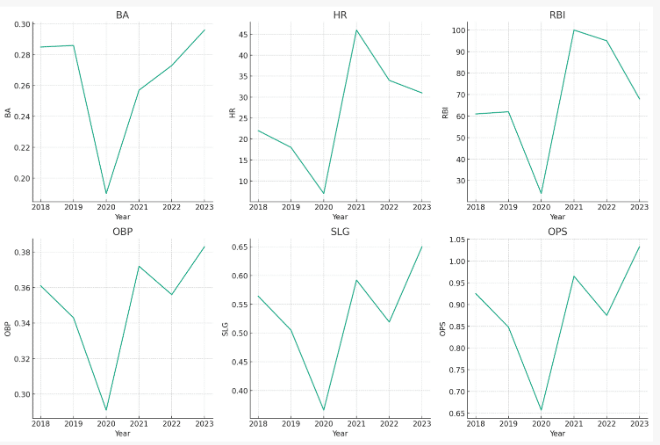

Standard Battingのデータファイルから情報を入手するためにCode Interpreterが生成したコードは以下のとおりです。
import pandas as pd
# Load the data
data_path = "/mnt/data/Standard Batting.xlsx"
data = pd.read_excel(data_path)
# Display the first few rows of the dataframe
data.head()
RESULT
Year Age Tm Lg G PA AB R H 2B ... OPS OPS+ TB \
0 2018 23.0 LAA AL 104 367 326 59 93 21 ... 0.925 151 184
1 2019 24.0 LAA AL 106 425 384 51 110 20 ... 0.848 121 194
2 2020 25.0 LAA AL 44 175 153 23 29 6 ... 0.657 79 56
3 2021 26.0 LAA AL 155 639 537 103 138 26 ... 0.965 157 318
4 2022 27.0 LAA AL 157 666 586 90 160 30 ... 0.875 144 304
GDP HBP SH SF IBB Pos Awards
0 2 2 0 1 2 DH1 RoY-1
1 6 2 0 4 1 DH NaN
2 3 0 0 0 0 *D/H1 NaN
3 7 4 0 2 20 *D1/H97 AS,MVP-1,SS
4 6 5 0 3 14 *D1/H AS,CYA-4,MVP-2
[5 rows x 30 columns]また、グラフを作成するためにCode Interpreterが生成したコードは以下のとおりです。
# Remove the last two rows
data = data[:-2]
# Try the plot again
plt.figure(figsize=(15, 10))
for i, stat in enumerate(stats_of_interest):
plt.subplot(2, 3, i+1)
plt.plot(data['Year'], data[stat])
plt.title(stat)
plt.xlabel('Year')
plt.ylabel(stat)
plt.tight_layout()
plt.show()グラフの作成に当たっては、何度か失敗したようですが、Code Interpreterが自動的に修正して、最終的には作成に成功しました。
(3) 大谷選手の投手成績の分析
打者成績と同様に、Standard Pitchingのデータファイルをアップロードして、以下のプロンプトで分析してもらいました。
大谷選手の投手成績の傾向を分析してください。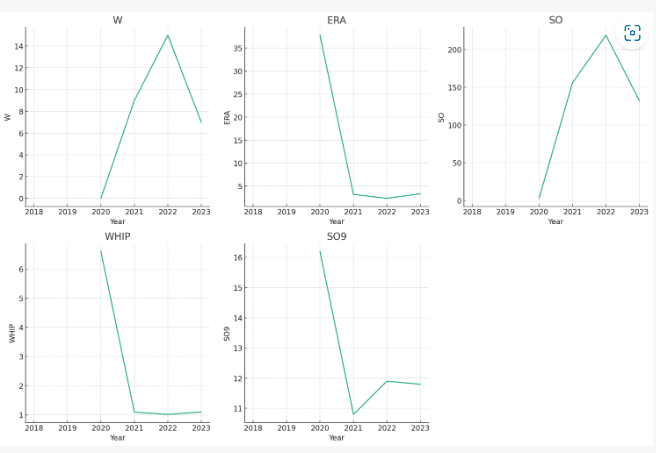

Standard Pitchingのデータファイルから情報を入手するためにCode Interpreterが生成したコードは以下のとおりです。
# Load the pitching data
pitching_data_path = "/mnt/data/Standard Pitching.xlsx"
pitching_data = pd.read_excel(pitching_data_path)
# Display the first few rows of the dataframe
pitching_data.head()
RESULT
Year Age Tm Lg W L W-L% ERA G GS ... BF \
0 2018 23.0 LAA AL 4.0 2.0 0.667 3.31 10.0 10.0 ... 211.0
1 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN ... NaN
2 2020 25.0 LAA AL 0.0 1.0 0.000 37.80 2.0 2.0 ... 16.0
3 2021 26.0 LAA AL 9.0 2.0 0.818 3.18 23.0 23.0 ... 533.0
4 2022 27.0 LAA AL 15.0 9.0 0.625 2.33 28.0 28.0 ... 660.0
ERA+ FIP WHIP H9 HR9 BB9 SO9 SO/W Awards
0 127.0 3.57 1.161 6.6 1.0 3.8 11.0 2.86 RoY-1
1 NaN NaN NaN NaN NaN NaN NaN NaN NaN
2 14.0 13.99 6.600 16.2 0.0 43.2 16.2 0.38 NaN
3 141.0 3.52 1.090 6.8 1.0 3.0 10.8 3.55 AS,MVP-1,SS
4 172.0 2.40 1.012 6.7 0.8 2.4 11.9 4.98 AS,CYA-4,MVP-2
[5 rows x 35 columns]また、グラフを作成するためにCode Interpreterが生成したコードは以下のとおりです。
# Remove the last two rows
pitching_data = pitching_data[:-2]
# Plot each of the pitching stats of interest over time
plt.figure(figsize=(15, 10))
for i, stat in enumerate(pitching_stats_of_interest):
plt.subplot(2, 3, i+1)
plt.plot(pitching_data['Year'], pitching_data[stat])
plt.title(stat)
plt.xlabel('Year')
plt.ylabel(stat)
plt.tight_layout()
plt.show()(4) 大谷選手の打者成績と投手成績の相関関係の分析
以下のプロンプトを入力して、Code Interpreterに大谷選手の打者成績と投手成績の相関関係を分析してもらいました。
Standard BattingとStandard Pitchingのデータを利用して、大谷選手の打者成績と投手成績の相関関係を分析してください。
この相関関係の分析のためにCode Interpreterが生成したコードは以下のとおりです。
# Select relevant columns from both datasets
batting_cols = ['Year', 'BA', 'HR', 'RBI']
pitching_cols = ['Year', 'W', 'ERA', 'SO']
# Create new dataframes with these columns
batting_subset = data[batting_cols]
pitching_subset = pitching_data[pitching_cols]
# Merge the two dataframes on the 'Year' column
combined_data = pd.merge(batting_subset, pitching_subset, on='Year')
# Calculate the correlation matrix
correlation_matrix = combined_data.corr()
# Display the correlation matrix
correlation_matrixまた、相関係数の計算結果は以下のとおりです。
RESULT
BA HR RBI W ERA SO
BA 1.000000 0.596719 0.618558 0.546286 -0.934945 0.598368
HR 0.596719 1.000000 0.959864 0.762656 -0.809603 0.837181
RBI 0.618558 0.959864 1.000000 0.888909 -0.843610 0.921337
W 0.546286 0.762656 0.888909 1.000000 -0.714659 0.986480
ERA -0.934945 -0.809603 -0.843610 -0.714659 1.000000 -0.759709
SO 0.598368 0.837181 0.921337 0.986480 -0.759709 1.000000
次に、この相関分析の結果が分かりやすくなるようにCode Interpreterに可視化してもらいました。
この結果を可視化してください。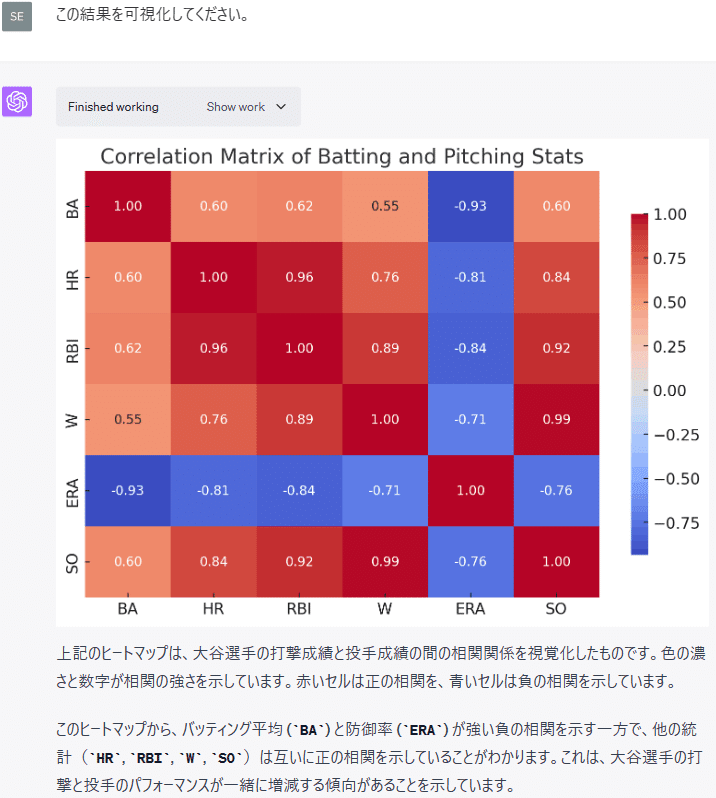
このヒートマップを描くためにCode Interpreterが自動生成したコードは以下のとおりです。
import seaborn as sns
# Set up the matplotlib figure
f, ax = plt.subplots(figsize=(9, 6))
# Draw the heatmap with the mask and correct aspect ratio
sns.heatmap(correlation_matrix, annot=True, fmt=".2f", ax=ax, cmap="coolwarm", cbar_kws={"shrink": .8})
# Set labels
ax.set_title('Correlation Matrix of Batting and Pitching Stats')
# Show plot
plt.show()最後に、この結果を野球解説者の落合博満さんに解説してもらいました。
野球解説者の落合博満さんとして、この結果を解説してください。
7.パワーポイントのスライドを自動生成する
ChatGPTについて解説するパワーポイントのスライドをCode InterpreterをセットしたChatGPTに自動で作成してもらいました。
(1) 入力プロンプトとChatGPTの回答
入力したプロンプトは以下のとおりです。
あなたは人工知能研究の専門家です。
python-pptxを使用して、ChatGPTについて解説する5枚のスライドを作成してください。
1枚につき3つの文章を書いて、それらを箇条書きで構成し、パワーポイントファイルで出力してください。
(2) 自動生成されたパワーポイントのスライド
このリンクをクリックすると以下のようなパワーポイントファイルがダウンロードできます。





(3) 自動生成されたコード
このスライド作成のためにCode Interpreterが生成したコードは以下のとおりです。
# Create a new PowerPoint presentation
presentation = Presentation()
# Slide 1: Introduction to ChatGPT
slide_1 = presentation.slides.add_slide(presentation.slide_layouts[1]) # Use the 'Title and Content' layout
slide_1.shapes.title.text = "ChatGPTの概要"
content_slide_1 = slide_1.shapes.placeholders[1]
content_slide_1.text = "ChatGPTはOpenAIによって開発された大規模な言語モデルです。\nこのAIは、様々なタスクに対応するための一般的な知識を学習します。\nGPTはGenerative Pre-training Transformerの略で、自然言語生成タスクにおける強力なツールです。"
# Slide 2: How ChatGPT is Trained
slide_2 = presentation.slides.add_slide(presentation.slide_layouts[1])
slide_2.shapes.title.text = "ChatGPTの訓練方法"
content_slide_2 = slide_2.shapes.placeholders[1]
content_slide_2.text = "ChatGPTは大量のテキストデータから学習します。\n具体的には、インターネット上の書籍やウェブページなどのテキストを用います。\nモデルはテキストのパターンを学習し、それを基に新たなテキストを生成します。"
# Slide 3: Applications of ChatGPT
slide_3 = presentation.slides.add_slide(presentation.slide_layouts[1])
slide_3.shapes.title.text = "ChatGPTの用途"
content_slide_3 = slide_3.shapes.placeholders[1]
content_slide_3.text = "ChatGPTは質問応答、文章生成、文章の要約など、多くの用途に使用できます。\n教育分野では、対話型の学習ツールとして活用されます。\nビジネスでは、自動的な文章生成やカスタマーサポートなどに使用されます。"
# Slide 4: Limitations of ChatGPT
slide_4 = presentation.slides.add_slide(presentation.slide_layouts[1])
slide_4.shapes.title.text = "ChatGPTの限界"
content_slide_4 = slide_4.shapes.placeholders[1]
content_slide_4.text = "ChatGPTは訓練データに含まれる情報しか知りません。それ以外の新たな情報を理解することはできません。\nまた、結果は確率的であり、同じ入力に対して異なる出力を生成することがあります。\nモデルは感情や意識を持たず、人間と同じように思考するわけではありません。"
# Slide 5: The Future of ChatGPT
slide_5 = presentation.slides.add_slide(presentation.slide_layouts[1])
slide_5.shapes.title.text = "ChatGPTの未来"
content_slide_5 = slide_5.shapes.placeholders[1]
content_slide_5.text = "モデルの訓練データやアルゴリズムの改善により、ChatGPTの精度は今後も向上するでしょう。\nChatGPTは今後も多くの産業や生活の場で活用されることが期待されます。\nしかし、その一方で、AIの倫理的な問題や使用の制限なども重要な議論となるでしょう。"
# Save the presentation
presentation_file = "/mnt/data/ChatGPT_Presentation.pptx"
presentation.save(presentation_file)
presentation_fileこのように簡単にパワーポイントのスライドを自動生成することができます。
8.PDFファイルの英語論文を要約する
(1) 実施方法とChatGPTの回答
最初に、論文(プレプリント)公開サーバーのarXivから要約したい英語論文のPDFファイルをダウンロードしておきます。
次に、Code InterpreterをセットしたChatGPTの入力欄の「+」マークをクリックして、このPDFファイルを指定します。
そして、「この論文を要約してください。」と入力して、実行ボタンをクリックします。
なお、今回要約した論文は、「LONGNET: Scaling Transformers to 1,000,000,000 Tokens」です。

これまで、PDFファイルの読み込みにはかなり苦労してきたのですが、これでだいぶ楽になりそうです。
注)他の英語論文のPDFファイルでも試してみましたが、上手く読み取れない場合もあるようです。テキストの長さや画像、図表の量の多さなど何が関係しているのかはよく分かりませんでした。
(2) 自動生成されたコード
PDFファイルからテキストを読み込むためにCode Interpreterが生成したコードは以下のとおりです。
from PyPDF2 import PdfFileReader
def extract_text_from_pdf(file_path):
pdf = PdfFileReader(file_path)
text = ""
for page in range(pdf.getNumPages()):
text += pdf.getPage(page).extractText()
return text
# Extract text from the PDF
pdf_text = extract_text_from_pdf("/mnt/data/2307.02486.pdf")
pdf_text[:2000] # Display the first 2000 characters to get a glimpse of the text content9.画像を読み取る
(1) 写真の読み取り
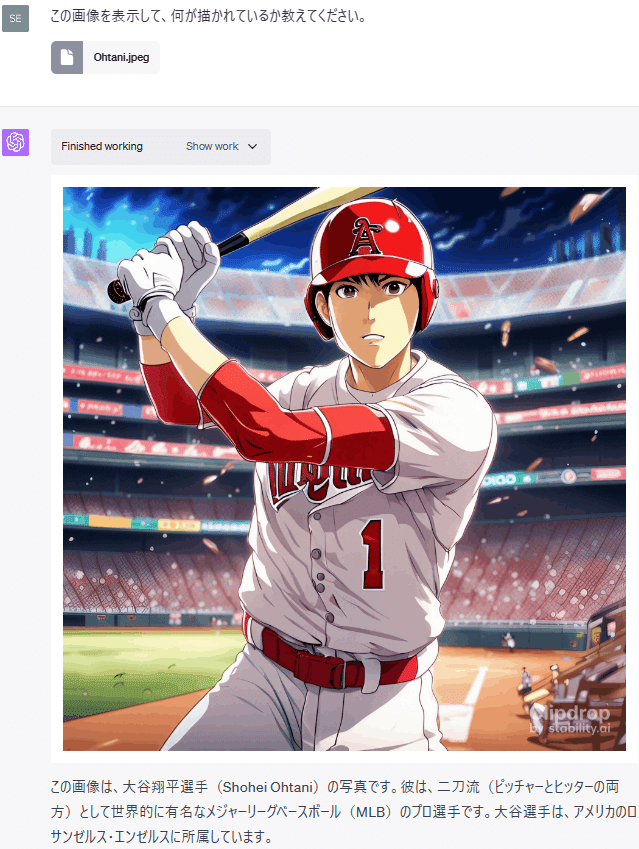
Code InterpreterをセットしたChatGPTに写真をアップロードして、描かれている内容を読み取れるか試してみました。
この画像を表示してください。この画像には何が描かれていますか?
Code Interpreterがこの画像を表示するために生成したコードは以下のとおりです。
from PIL import Image
# Open the image file again
img3 = Image.open("/mnt/data/Elon_Musk_Colorado_2022_(cropped)(1).jpg")
# Display the image
img3.show()画像を表示したり、画像の内容をある程度読み取ったりすることも可能なようです。
ただし、これは上手くいった例であり、画像の読み取りは失敗することも多いようです。
(2) 画像中の文字の読み取り
文字が含まれる画像をアップロードして、文字を読み取ることができるか試してみました。
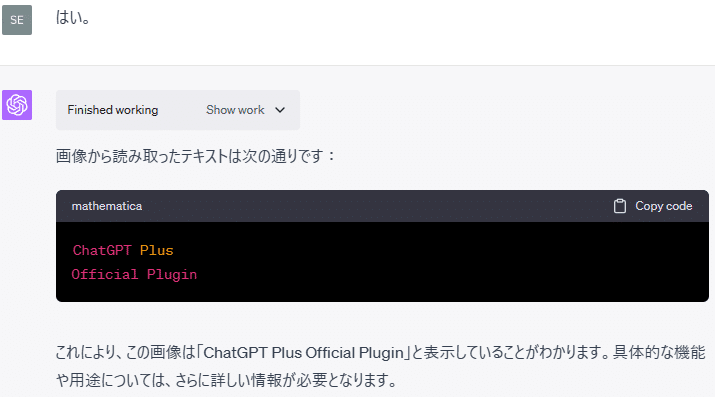
Code Interpreterが画像の読み取りとOCRの使用のために生成したコードは以下のとおりです。
from PIL import Image
import matplotlib.pyplot as plt
# Open the image file
img = Image.open('/mnt/data/Code Interpreter.png')
plt.imshow(img)
plt.axis('off') # to hide the axis
plt.show()import pytesseract
# Use Tesseract to do OCR on the image
text = pytesseract.image_to_string(img, lang='eng')
textこのように、OCRを使用して、画像内のテキストを読み取ることもできます。
なお、「Code Interpreter」の文字の方は、背景と文字の色合いが似ていたせいか、上手く読み取ることができませんでした。
(3) 画像の編集
画像をアップロードして、様々な編集を試してみました。
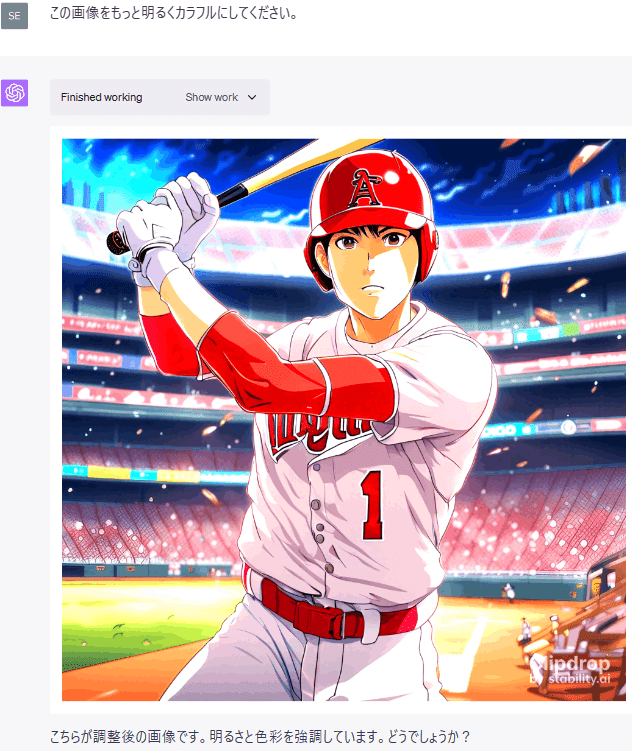
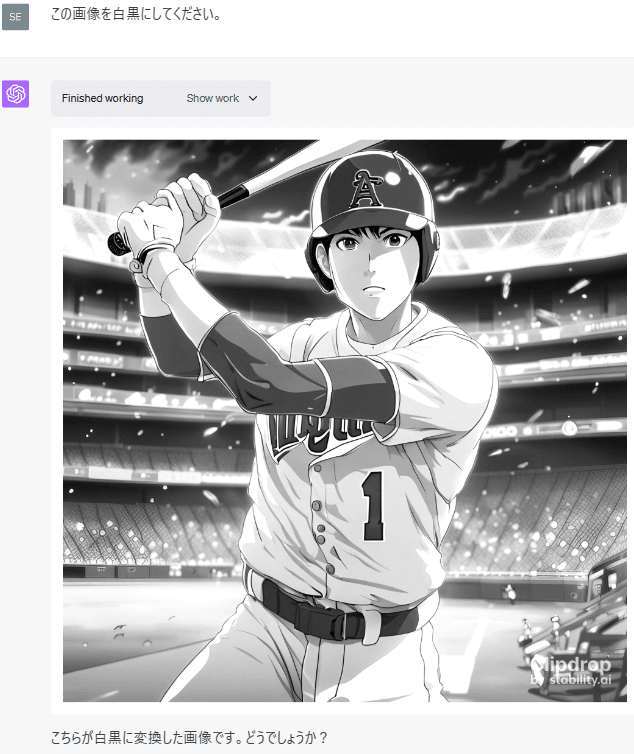
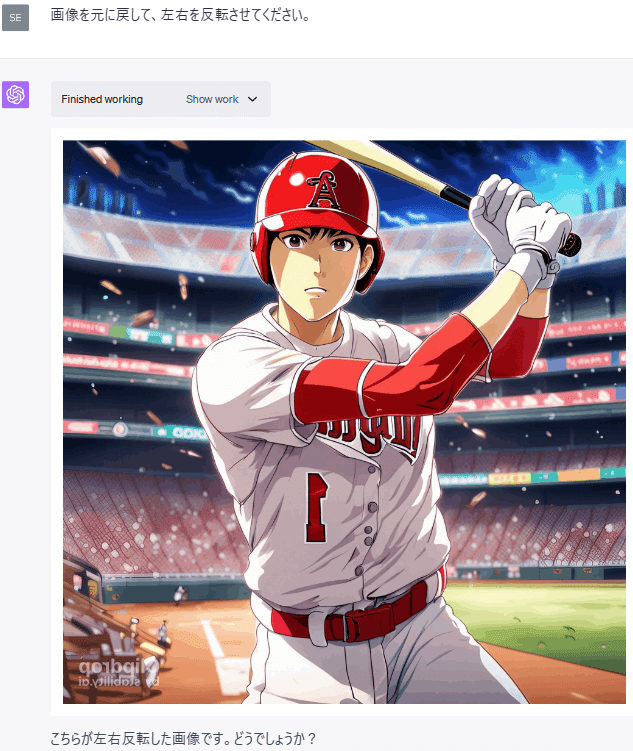
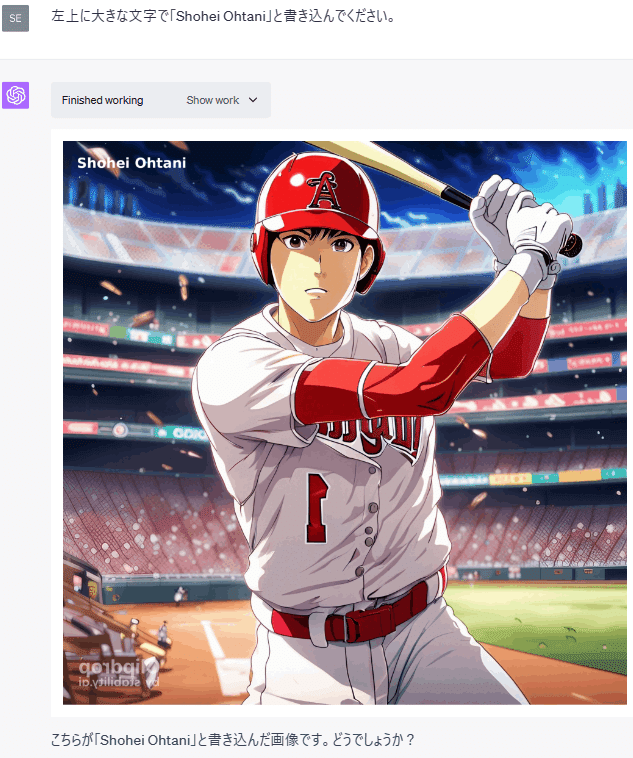
このように、Code Interpreterは画像の編集をすることもできます。
具体的には、以下のようなことができます。
色彩、彩度、明るさ、コントラストなどの調整
グレースケール(白黒)への変換
画像の回転と反転
画像サイズの変更、一部領域の切り取り
ブラー、シャープネスなどのフィルターの適用
画像へのテキストの追加
10.まとめ
Code Interpreterは、データさえ準備すれば、簡単なプロンプトの指示でも、自ら工夫して分析を進めてくれるので、とても便利です。
沢山のデータの中からどのデータを使えばよいか分からないときでも、主なデータを適当にピックアップして、十分納得できるようなデータ分析を行ってくれます。
他方、Noteableプラグインなどのようにネットからデータを入手することができず、ユーザーが自分で必要なデータを探してこないといけないところは少し不便です。
この点が将来的に改善されるとよいのですが、OpenAIは、悪用を気にしているようです。
また、ネット検索ができないと、最近の変更などには対応できないため、例えば、GPT-4のAPIを利用したプログラムの作成ができないなどの不便さもあります。
とは言え、Code Interpreterは、非常に活用範囲の広いプラグインなので、皆さんも是非、色々な用途に使ってみてください。まだまだ、驚くような活用方法があると思います。
この記事が気に入ったらサポートをしてみませんか?