
プログラミングで、分からないことは自分で調べるとよく理解できる

どうも、じぇいかわさきです。
皆さんは、参考書とかに書かれた事が間違っている場合、どのように対処しますか?
正誤表が有れば良いかもしれませんが、正誤表がなかったり状況が変わったりする場合もありますよね。
そんな時、できる限り自力で考えると付帯することも覚えられて、良いことばかりですよ。
今回は、Pythonの学習で参考書通りにやっても動かなかった内容を、自力で解決した事の紹介です。
記述内容通りに動かなかったので自力で調べてみた

自分で考えると、パズルのようで面白い
ツールの使い方も取得できるぞ
本の内容通りにやったらエラーだらけ
さて、今回もPythonによるスクレイピングの練習を行いました。
今回はサンプルページではなく、実際のYahooのページからトピックス項目を抜き出してくるコードです。
前回までに、どのようにやればよいのか理解できていますので、今回はそのカスタマイズみたいなものですね。
そう考えると、ちょろいと思い参考書を見ながらコードを書いていきました。
参考書に書かれている内容を、よく読みながらコードをタイプしていく過程で、参考書では、どのようにして抜き出す為のコードを選ぶのかなど、詳しく書いてあります。
コードとしてはこんな感じですね。
import requests
from bs4 import BeautifulSoup
load_url = "https://news.yahoo.co.jp/categories/it"
html = requests.get(load_url)
soup = BeautifulSoup(html.content, "html.parser")
topic = soup.find(class_="topicsList_main")
for element in topic.find_all("a"):
print(element.text)
早速、出来上がったコードをセーブして実行してみました。
当然、期待としては実際のYahooのホームページに記載されているトピックスリストが出てくると思いますから、ワクワクいしますよね。
しか〜し、出てきた結果は以下の通り。
Traceback (most recent call last):
File "/Users/******/Documents/chap2-7-1.py", line 9, in <module>
for element in topic.find_all("a"):
AttributeError: 'NoneType' object has no attribute 'find_all'
>>> なんとエラーなんです。
何度やっても同じだし、コード自体を何回も見直してみても、参考書通りで間違っていない。
はて?
AttributeErrorは、メソッドなどを呼び出す際に、オブジェクトや識別子(属性やメソッド)の名前、オブジェクトの型を間違えている場合に発生するエラーらしい。
今回のエラーを見ていくと、'NoneType' object has no attribute 'find_all' と言うエラーなので、どうやらfind_allでマッチするものがないと言っているのではないかと思う。
しょうがないので自力で原因を突き止めた
まず、'NoneType' object has no attribute 'find_all' というエラーですが、エラーので具合からすると、次のように推測されます。
コードでは
topic = soup.find(class_="topicsList_main")
for element in topic.find_all("a"):の部分にあたり、これはHTMLタグでclassの部分がtopicsList_mainものを見つけて、その部分に記載されている aタグの部分を取り出せという内容。
つまりだ、aにあたる部分が無いよと言っているのではないかと思う。
参考書を見る限りでは、HTMLコードの中ではtopicsList_mainが存在し、その配下にaタグは確かに存在している。
でも実際にコードを実行すると無いと言うのであれば、記述内容に違いが有るとしか思えない。
自分でChromeのデベロッパーツールを使って調べてみた。
対象のページはこのページなので、ここでデベロッパーツールを起動させる。
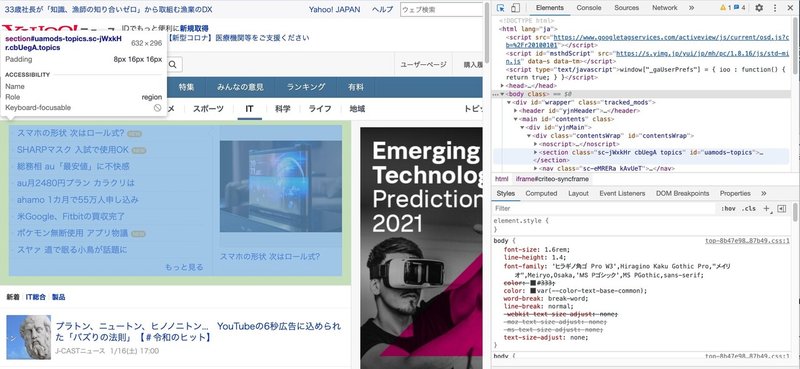
デベロッパーツールで、対象部分を選択して右のHTMLコードをチェックしていく。
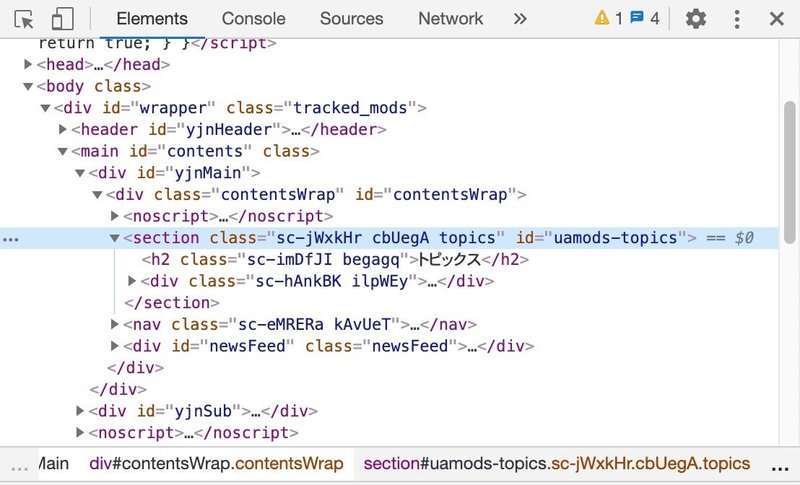
対象となる部分を、デベロッパーツールを用いて調べてみると
topic = soup.find(class_="topicsList_main") の部分の、topicsList_mainが実際と違っているようなんです。
デベロッパーツールを使って調べた結果は、sc-jWxkHr cbUegA topicsになっており、topicsList_mainという部分は有りません。
従って、実際のHTMLコードに合わせて上記部分を修正します。
topic = soup.find(class_="topicsList_main")
↓
topic = soup.find(class_="sc-jWxkHr cbUegA topics")この状態が実際の状態と同じはずなので、コードは全体では以下の通り。
import requests
from bs4 import BeautifulSoup
load_url = "https://news.yahoo.co.jp/categories/it"
html = requests.get(load_url)
soup = BeautifulSoup(html.content, "html.parser")
topic = soup.find(class_="sc-jWxkHr cbUegA topics")
for element in topic.find_all("a"):
print(element.text)
今度は良いはずですので、一旦セーブ後に期待して実行させてみましょう。

完璧です、実際のYahooのITページで表示されているトピックス部分が切り取られて読み込むことができました。
やはり、参考書に書いてある内容が実態と異なっていたようです。
自ら調べると、何が違うかが見えてくる
さて、今回の記事は学習に使っている参考書通りのコードでは、参考書に書かれている内容通りにならなかったことについて書いています。
実際に、参考書に書かれている内容を信じるのではなく、自らが同じツールを使って調べることで、実際の内容がどのようになっているかを確認できたということです。
自ら同じツールを使い、調べることでツールの使い方も取得でき、かつ何故違うのかの原因も明確にすることができたのです。
参考書に書かれている内容で、実際と動作が異なった場合、正誤表に書かれていなければ、実際に自分で同じ事をやって確認することで、原因を調べることができるのです。
参考書を読んで学習しているだけだと、実際に動かしたときのエラーはわかりませんので、学習するには同じコードを打ち込み、動作させることが確実に自分の身になるという事が証明できました。
プログラミング学習は実際にコードを打ち込み動かす、これが最も重要な事だと再認識しました。
じぇいかわさきです。生産技術者として35年、今まで培った経験とスキルを元に、ものづくりに関わる世の出来事に対して思ったことをホンネで書いてます。ノウハウやアイデアもありますよ。 また写真も全力で撮っています、気に入った写真があればサポートや感想をぜひお寄せください。