データサイエンスは最強のリベラルアーツだとおもう理由

2018年9月28日、「データサイエンス「超」入門 嘘をウソと見抜けなければ、データを扱うのは難しい」という本が刊行されました。
ところで、いきなりですが「データ」とは何でしょうか。手前味噌ですが「グラフをつくる前に読む本」から引用します。データとは、
万国共通で、誰もが認識の齟齬なく、伝達・解釈・処理が行える表現として最適なものが「数字」です。(略)何らかの意味を持たなければ数字は「データ」とは言えないのです。(略)つまり、データは「数学」でありながら、「国語」の要素があります。どれだけ数字に強い人間であったとしても、数字が誕生した背景やどのような文脈で用いられているかを把握できなければ、トンチンカンな解釈をしてしまい、誤った理解でデータにふれてしまいます。
私のようなポンコツデータサイエンティストは、数字だけに着目して、文脈を理解せず、結果的に「言っていることはわかるけど、それどうやって実行するの?」「そんな予測モデル、当たり前すぎて使い物にならない」という分析結果を生みがちです。
データは数学でもありながら、国語でもある。
そんな当たり前を僕は「データサイエンス「超」入門 嘘をウソと見抜けなければ、データを扱うのは難しい」という本に書きました。
本書は次のように始まります。
この本は、データサイエンスについて学びたいと思っているけど、数学は苦手だし、なにより何から学んでいいかわからないと戸惑っている人のための超・入門書です。(略)本書のメインテーマは「テータの読み方」です。読み方といっても、1をイチと読むという話ではありません。データの特徴を理解して、背景に隠されている事象に想いを馳せて、データに違和感を覚え、時には現場に足を運び、データが何を表現しているかを読み解く作業が「データを読む」という仕事です。
データの特徴を理解して、背景に隠されている事象に想いを馳せて、データに違和感を覚え、時には現場に足を運び、データが何を表現しているかを読み解くには、数学が必要であり、国語が必要だと私は考えています。
一方で、それってどういうこと?と考えている人も多いはず。そこで今回は2つの事例をご紹介します。
「大阪都構想はシルバー民主主義の勝利」という間違い
大阪に住んでいない人からすれば何も興味ないでしょうが、ほんの数年前、大阪は都構想で揺れていました。
住民投票の結果、都構想は否決され、当時の橋下市長は退任し、「維新」衰退のキッカケにすらなりました。
投票日の翌日、(私の記憶が確かだったら)読売テレビで辛坊治郎さんが「老い先短い人たちの目の前の不安感を解消することができなかった」「これからの世代の子はかわいそうかなって気がします」と、都構想が否決されたことを嘆いていました。
読売新聞の年代別出口調査結果は以下の通りです。「グラフをつくる前に読む本」から引用します。なるほど確かに、年代が上がるごとに、反対の割合が上がっています。70代以上は反対が多数です。
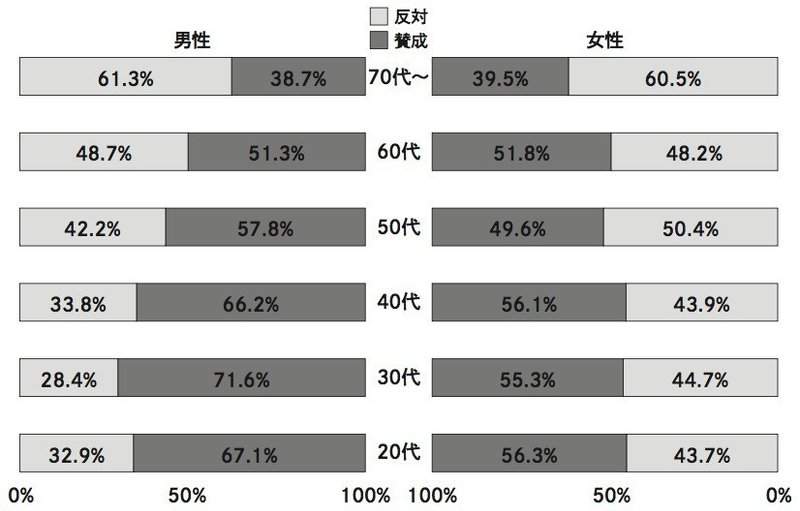
ということは、70代以上が60代以下の意見を踏み潰したんでしょうか。改めて結果を見てみましょう。
当日の有権者数210万4076人中、投票したのは140万429人。私もその中の一人です。反対70万5585票、賛成69万4844票、その差1万741票でした。
そこで、大阪市選挙管理委員会が公表している年齢別帳票結果をグラフにしてみます。「グラフをつくる前に読む本」から引用します。
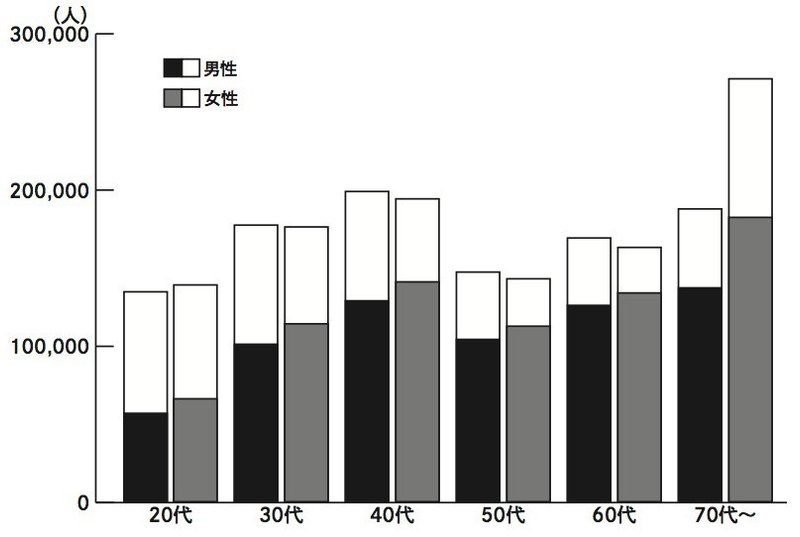
棒の高さが当日有権者数、色で塗られたのが投票者数、白枠が棄権者数です。
どの年代も一律では無いとわかります。20代は投票率が低く、50代以上は関心が高いことが伺えます。
では、この結果から、読売新聞の年代別出口調査結果を掛け合わせてみましょう。例えば20代男性の投票者数が57,215人なので、反対32.9%=18,824人と賛成67.1%=38,391人といったような感じです。
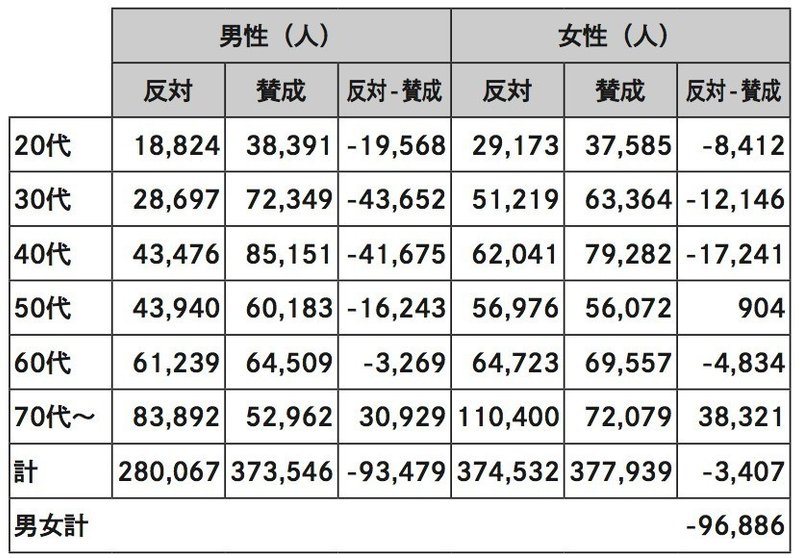
結果、反対65万人強、賛成75万人強で大阪都構想は可決…ってあれ?
大阪市選挙管理委員会が発表している数字が違うなんてことありえませんから、読売新聞の年代別出口調査結果が間違っていたんでしょう。選挙では反対に投票したのに、出口調査では賛成と言ったのです。
つまり、ええかっこしたかったわけですね。本当のことを言わなかった。
こうした出口調査の精度問題は、のちにEU離脱(ブレグジット問題)やトランプ当選でも垣間見得ます。
なぜ辛坊治郎さんは選挙結果と、70代以上が反対しているという結果だけを見て短絡的に「老い先短い人たちが…」とウンチク垂れたんでしょう。ちょっと計算すれば分かると思うのですが。
これが、結果を「国語」として読んで、間を取り繋ぐ「数字」が読めなかった例です。反対派が買った、反対派が過半数を占めたのは高齢者だった、だから高齢者が若者の意見を踏みにじったという三段論法です。
マスメディアに登場されている方は、その場で思いついただけのコメントを後先に渡って僕みたいな人間にネチネチと間違いを指摘されて大変だなぁと思います。
「FBはおじさん・おばさんだらけは間違い」という間違い
私がFacebookを使い始めたのは2011年2月ごろでした。当初は20代〜30代前半しかユーザーはいなかった印象を持っています。それがいつしか、ご年配の方から友達申請を多くいただくようになりました。
見ず知らずの50代後半の方から「おはよう〜今日も頑張ろう(≧∀≦*)/」と顔文字付きでメッセージが飛んできた経験も1度や2度ではありません。リアルでそんな挨拶されたら、全身が逆立ちます。
いつしか「Facebookはおじさんとおばさんしか使っていないからやりたくない」と言われるようになりました。おそらく多くの若者がFacebookを使いたがらない理由の1つに該当するのではないでしょうか。
しかし「情報通信メディアの利用時間と情報行動に関する調査報告書」によると、2016年はFacebookは各年代で以下のような利用率でした。
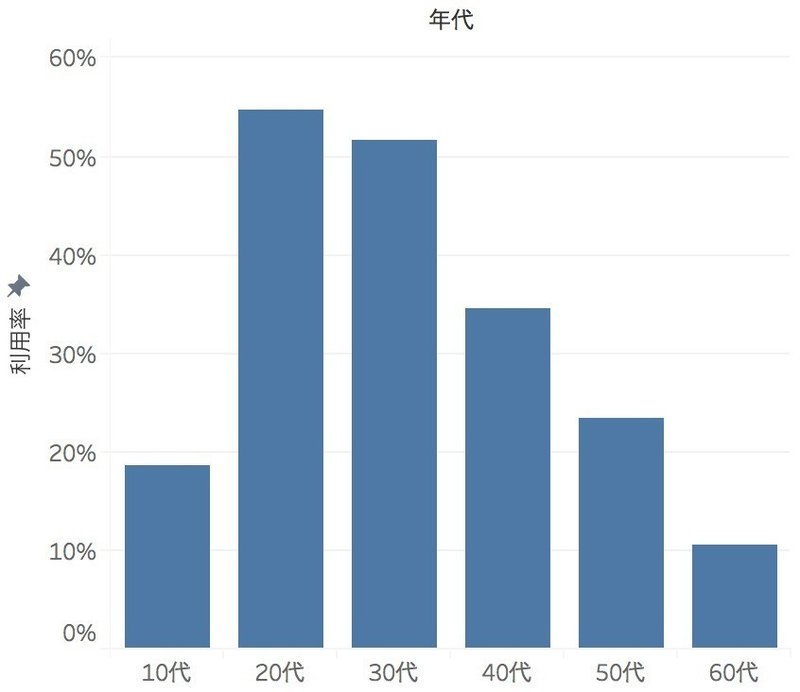
20代が突出して高く、ついで30代、40代と続きます。
この結果からすれば「FBはおじさん・おばさんだらけは間違い」だと言えるかもしれません。
そこで、データの見方を変えてみましょう。
このデータは利用「率」です。各年代の回答者に対してそれぞれFacebookを使っている割合を求めて計算しています。各年代の回答者数内訳は公表されていたので、そこから「Facebookを使っている数」を求めてみました。
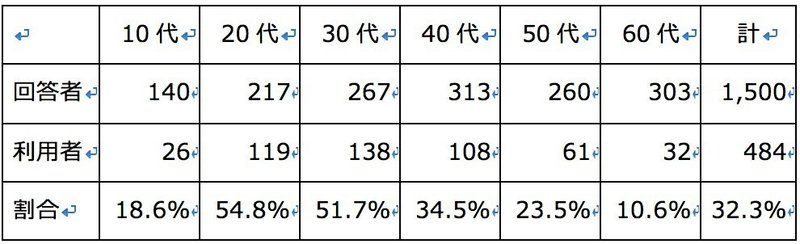
「大阪都構想」の時と同様、各年代は均等ではありません。ちなみに2015年の国勢調査による総人口は各年代で以下のようになります。
10代:1167万4千人
20代:1263万3千人
30代:1581万3千人
40代:1861万3千人
50代:1562万5千人
60代:1831万1千人
10代は40代の60%でしかありません。
ちなみに今回の回答者数も、調査報告書によれば「13歳から69歳までの男女 1,500人を(性別・年齢10歳刻みで2017年1月住民基本台帳の実勢比例)、 全国125地点(都市規模×地域(11区分)により層化)、ランダムロケーションクォータサンプリングにより抽出」と書かれており、バランスよく抽出したら、こんな結果になったという具合です。
各年代は「満遍ではない」のですから、単純に利用率という割合で年代を比較するのは間違っているのではないでしょうか?
回答者に対する利用者の数を見てみましょう。20代の119人と40代の108人、ほぼ同じ結果です。
さらに、「情報通信メディアの利用時間と情報行動に関する調査報告書」はfacebookの利用者数を2012年からデータとして掲載しており、以下のような推移を見せています。
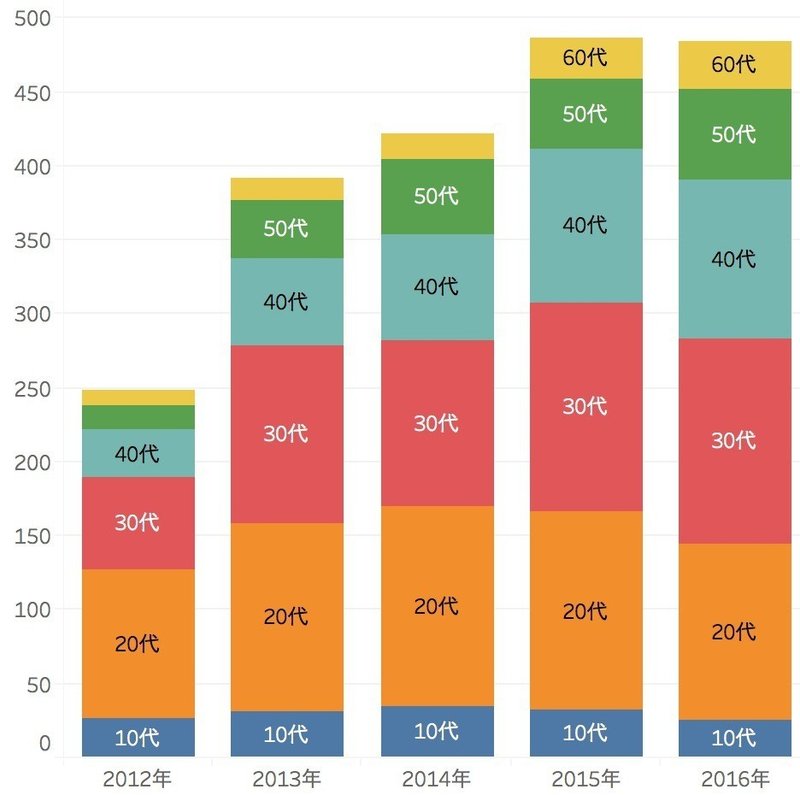
少し見方を変えて、利用者の内訳にしてみましょう。
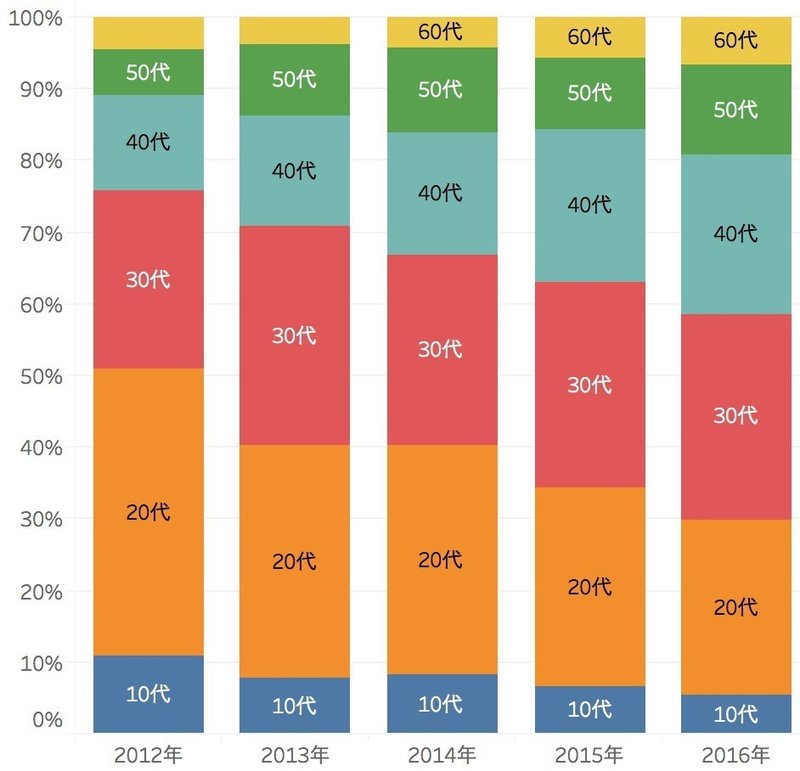
今回のデータに限って言えば、2012年には10代〜30代が全体の80%弱を占めていました。しかしFacebookの利用者数が増えるに伴い、10代〜30代の割合が下がっています。ちなみに、この5年間でもっともユーザー数が増えているのは、40代〜50代でした。
「Facebookはおじさんとおばさんしか使っていない」と言うよりも、どちらかと言えば「Facebookはおじさんとおばさんの利用が急激に増えているから、"ばかり"に感じる」という表現が正確ではないでしょうか。
最後に、物の見方そのものを変えてみましょう。
私は以前、何歳からがおじさんで、何歳までがお兄さんと呼べるのかを分析したことがあります。その結果がこちら。
分析の結果、①20代前半から見れば一回り上は「おじさん」、②20代後半〜30代から見れば清潔感があれば30代後半でも「お兄さん」だけど、ヒゲがある・肩書きが付く等あれば同年代でも「おじさん」だとわかりました。
つまり20代から見れば多少の違いはあっても、30代の大半は「おじさん」なのです(女性はおばさんと言えるかは不明ですが恐らくそうなのでしょう)。
では、そもそものお題に立ち返りますが「Facebookはおじさんとおばさんしか使っていない」という意見は「誰」の目線、「誰」の意見なのでしょう。
まさか、30代の感想ではないでしょう。おそらく10代か20代の意見だと思われます。だとすると、今まで何歳以上をもっておじさんおばさんとするかを定義しなかった分析自体を改める必要があります。
ちなみに、データ元が違えば、調査結果が変わることは大いにあるので、この結果をもって言い切るのは難しいです。
例えば、このコンテンツでは平成28年度情報白書を参照しています。ただ、情報白書は「ソーシャルメディアの利用状況」の情報元がわからないので、N=200より(加重平均)に目が向いてしまいます。
データを読む力はリベラルアーツだ
「データサイエンス「超」入門」では詳しく書かなかったのですが、僕はデータを読む国語と数学の能力を「リベラルアーツ」だと考えています。
そもそもリベラルアーツとは、言語(国語)に関する「文法」「修辞学(弁論術)」「論理学(弁証法)」の三学と、数学に関する「算術」「幾何」「天文」「音楽」の四科の合わせて7つの科目で構成されます。
この由来は古代ローマ時代にまでさかのぼります。古来、技術は奴隷人が身に付けるべき「機械的技術(artes mechanicae)」と、自由人が身に付けるべき「自由諸技術(artes liberales)」に区分されていました。後者がリベラルアーツの大本になっています。
奴隷人と自由人というのは物騒な表現に思われるかもしれませんが、これは土地を収奪し続けたローマの特性から生じたものです。吸収合併した土地に住む人が「奴隷人」、もともとローマの土地に住んでいた人が「自由人」だと考えると分かりやすいかもしれませんね。日本の江戸時代でいうところの「外様大名」と「譜代大名」の差みたいなものです。
奴隷人は生きるために仕事をしており、だからこそ機械的技術(工芸などの技術)を必要としていました。一方の自由人は、生きるために生きていました。だからこそ「僕らはなぜ生きるのか?」という哲学が流行し、そのための基礎知識として自由諸技術を必要としていました(哲学は7科の上位に位置付けられています)。
やがて中世以降、リベラルアーツは欧州の大学制度において「人間が身に付けるべき最初の芸術(=arts)」と見なされるようになり、今日では「学士過程における基礎分野を横断的に教育する科目」となりました。日本の大学では“一般教養”という名前で授業が開かれています。
芸術と聞くと、絵画や骨董などを思い浮かべるかもしれませんが、欧米では、人の手によって作られたもの全般を芸術(arts)、神の手によって作られたもの全般を自然(nature)と分類します。この分類に準拠すると、絵画も音楽も歴史も法律も全て芸術となります。つまり、リベラルアーツは全ての専門知識の根幹を成すものなのです。
何かを行おうとする際に、最初に必要な学問がリベラルアーツならば、専門的な技術である「機械的技術」はその先にあるものです。リベラルアーツがあってこそ、初めて専門知識を使えるようになるといっても過言ではありません。
リベラルアーツでは三学四科を通じて、本質を見る目を身に付けます。例えば、月が満ち欠けするのは、月自体が消えたり生まれたりしているのではなく、地球の周りを回ることで影が生まれて欠けているように見えるだけです。満ち欠けは現象であり結果です。月の公転軌道は本質であり、原因と捉えられます。
不変の「本質」と可変の「現象」を見極める――現象や結果にばかり目を向けず、原因や本質は何か、それを論理的に思考する能力を養うのがリベラルアーツなのです。
だからこそ、データサイエンスにはリベラルアーツが必要なのだと考えています。「本質」ではなく「現象」ばかり目を向けて無残な現状を晒した人たちの残骸が、上で紹介した辛坊治郎さんや以下のnoteに登場する人たちではないでしょうか。
データジャーナリズムって楽しい!
とまぁ、こんなことをつらつら書き連ねておりますが、基本的には「データを使って社会現象を読み解くって意外と楽しい!」ぐらいの感覚を抱いていただければ幸いです。
ちなみに上記本では、オープンデータを使って様々な社会事象を読み解き、いかにバイアスを持って判断しているかを明らかにしております。
書籍のお題を挙げると…
・「世界から愛される国、日本」に外国人はどれくらい訪れているのか
・なぜネットと新聞・テレビで支持率がこんなに違うのか
・結局、アベノミクスで景気は良くなったのか
・東日本大震災、どういう状況になれば復興したと言えるのか
・経済大国・日本はなぜ貧困大国とも言われるのか
・人手不足なのにどうして給料は増えないのか
・海外旅行、新聞、酒、タバコ…若者の◎◎離れは正しいのか
・地球温暖化を防ぐために、私たちが今できることは何か
・糖質制限ダイエットの結果とデータにコミットする
・生活水準が下がり始めたのか、エンゲル係数急上昇の謎
経済問題からダイエットまで、幅広くデータで読み解いております。書籍で見かけたらぜひ立ち読みして頂き、面白かったらぜひお買い求めください!
以上、お手数ですがよろしくお願いいたします。
1本書くのに、だいたい3〜5営業日くらいかかっています。良かったら缶コーヒー1本のサポートをお願いします。