
今年のNPB打者成績を主成分分析したらやっぱり村上が異次元だった【Python】

こんにちは。いけだといいます。
NPBのレギュラーシーズンも無事終了し、ヤクルトの村上選手が2004年松中以来の三冠王を獲得されましたね!
同じ熊本出身として、村上選手の活躍は嬉しいものがあります。
村上選手の活躍っぷりはもはや語るまでもないのですが、主成分分析という統計学上のデータ解析手法を用いても、やはり村上選手が凄かったので共有したいと思います。
この記事は、Pythonによる主成分分析の簡単な解説も兼ねています。
細かいことはいいから結論だけ見たい!という方は分析結果の確認をご覧ください。
主成分分析とは
ざっくりいうと
そもそも主成分分析とは、ざっくりいうと「多くの項目があるデータから、少数の項目にデータを集約」(次元を縮小)することです。
主成分分析のイメージ(例:5教科の点数)
例えば、あるクラスの5教科(国語、数学、理科、社会、英語)のテスト成績をグラフで表したい、と思ったとします。
2次元のグラフで表そうとすると、横軸分(x軸)と縦軸分(y軸)の2つの項目しか図示できません。
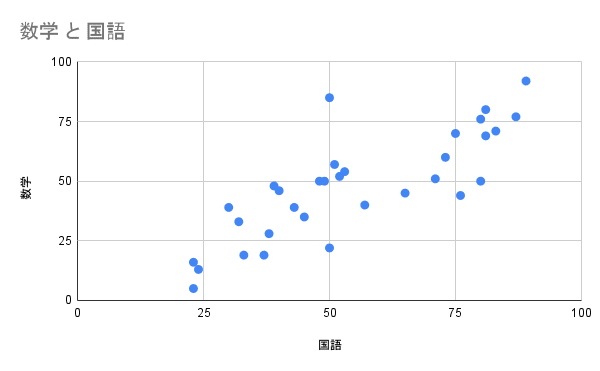
そこで、国語と社会、英語の平均点を「文系科目」、数学と理科の平均点を「理系科目」とそれぞれ大胆に一本化することで、5教科(5次元)のデータを2次元に集約できます。
主成分分析とは、おおよそこのようなイメージで行われる分析です。

実際の分析では
5教科の例では集約先の2軸を「文系科目」「理系科目」と、算出方法も含め恣意的に決めました。ですが、実際の分析では元データの各項目について、データの散らばり具合などを計算しながら、いくつかの項目を掛け合わせて軸を算出します。
そして、算出されたアウトプットを眺めることで、全体の概要を把握できたり、次の分析につながるひらめきを得られたりします。
算出の詳しい方法についてはここでは割愛しますので、詳しく知りたい方は以下のURLやWikipediaをご参照ください。
(参考URL)
マーケティング用語集主成分分析とは - インテージ
主成分分析 - 統計科学研究所
Pythonによるモデル学習
ここからは実際のコードも交えつつ、分析していこうと思います。
分析にはPythonを利用します。
今回は2022年セパ規定打席到達者の48人について分析を行います。
データ元は プロ野球データFreak様 です。(引用データ元ページは こちら)
CSVの読み込み
まずはCSVデータを読み込みます。
import pandas as pd
df = pd.read_csv('npb_batting_2022.csv')※使用したCSVファイルを置いておくので、ぜひご利用ください。
データの標準化とモデル作成・学習
つぎにデータを標準化します。
from sklearn.preprocessing import StandardScaler
#項目「打率」以降の標準化
df2 = df.loc[:,'打率':].astype('float')
sc = StandardScaler()
sc_df = sc.fit_transform(df2)そしてモデルを作成・学習します。
from sklearn.decomposition import PCA
#モデル作成
model = PCA(n_components=2, whiten=True)
#モデル学習
model.fit(sc_df)作成された新しい2軸を、既存のsc_df(標準化したデータ)に当てはめます。
new = model.transform(sc_df)
new_df = pd.DataFrame(new)
new_df.head(5)
[実行結果]
-----------
0 1
0 1.408209 0.102732
1 1.118366 0.769823
2 3.607486 0.312527
3 -0.458732 2.221916
4 -0.423739 2.582557
5 -0.432789 2.6474学習させたモデルの固有値ベクトルを確認してみます。(今回は第1主成分)
print(model.components_[0])
[実行結果]
-----------
[ 0.14435171 0.19566932 0.2164959 0.15027245 0.25336402 0.19371936
0.16012095 -0.11637375 0.31251831 0.34353913 0.3270579 -0.06632519
-0.06478357 -0.21027585 0.03810093 0.27550189 0.25858487 0.08008424
0.14558669 0.12327998 0.25239962 0.32299313]よさそうですね。(適当)
次に、標準化したデータから、2軸のスコアを算出します。
new = model.transform(sc_df)
new_df = pd.DataFrame(new)
new_df.head(5)
[実行結果]
-----------
0 1
0 1.408209 0.102732
1 1.118366 0.769823
2 3.607486 0.312527
3 -0.458732 2.221916
4 -0.423739 2.582557これで、「打率」~「長打率」の22次元データを2次元に集約できました。
データの整理とプロット
主成分の分析
これまでで2つの軸が作れたので、今度はこの2軸が、何の項目から作られているか(何の項目と相関性が高いか)を確認していきたいと思います。
new_df.columns=['PC1','PC2'] #生成された軸に仮の名前を付けておく
#標準化データと生成された2軸を合体
df3 = pd.DataFrame(sc_df,columns=df2.columns)
df4 = pd.concat([df3,new_df],axis=1)
#打率~長打率とPC1の相関性を確認
df_corr = df4.corr()
pc_corr = df_corr.loc[:'長打率','PC1':]
pc_corr['PC1'].sort_values(ascending=False)
[実行結果]
-----------
塁打 0.958485
打点 0.912502
長打率 0.901161
本塁打 0.871936
四球 0.768659
敬遠 0.721460
得点 0.706894
出塁率 0.704203
(略)
第1主成分(PC1)と相関性が高い項目は、相関係数順に塁打、打点、長打率、本塁打…と出てきました。
相関係数の高い項目をまとめた、抽象的な概念でPC1を名付けたいです。
この分析では、第1主成分を「Slugger」スコアと名付けようと思います。
#打率~長打率とPC2の相関性を確認
pc_corr['PC2'].sort_values(ascending=False)
[実行結果]
-----------
打数 0.751306
盗塁 0.734584
盗塁刺 0.692736
打席数 0.675605
安打 0.640892
三塁打 0.523511
犠打 0.463468
(略)同様に第2主成分は打数や盗塁と相関が高いようです。
今回は第2主成分を「Speedstar」スコアと名付けます。
(「Speedstar」という名前に私自身あまりしっくり来てないので、いい名前を思いついたら教えてください)
データの整理
主成分に名前を付け終わったので、次は分析しやすいようにデータに選手名を付けます。
#PCの名前変更
col = ['Slugger','Speedstar']
new_df.columns = col
#選手名を追加
df_name = df[['選手名','チーム']]
df5 = pd.concat([df_name,new_df],axis=1)
df5.head(5)
[実行結果]
-----------
選手名 チーム slugger technical
0 浅村 栄斗 楽天 1.408209 0.102732
1 島内 宏明 楽天 1.118366 0.769823
2 村上 宗隆 ヤクルト 3.607486 0.312527
3 中野 拓夢 阪神 -0.458732 2.221916
4 岡林 勇希 中日 -0.423739 2.582557選手名と分析結果を紐づけできました。
散布図でプロット
ここからはプロットの準備をしていきます。
x軸に「Slugger」、y軸に「Speedstar」を当てます。
import matplotlib.pyplot as plt
x = df5['Slugger']
y = df5['Speedstar']
labels = df5['選手名'] #データラベル用
plt.figure(figsize=(36,24))
plt.xlabel('Slugger', fontsize=24)
plt.ylabel('Speedstar', fontsize=24)
plt.scatter(x, y, s=300)
for i, label in enumerate(labels):
plt.text(x[i], y[i], label, fontname="Meiryo", fontsize=24)
plt.grid(True)
plt.show()以上でプロット完了です。
分析結果の確認
村上選手の凄さ
分析した結果がこちらです。
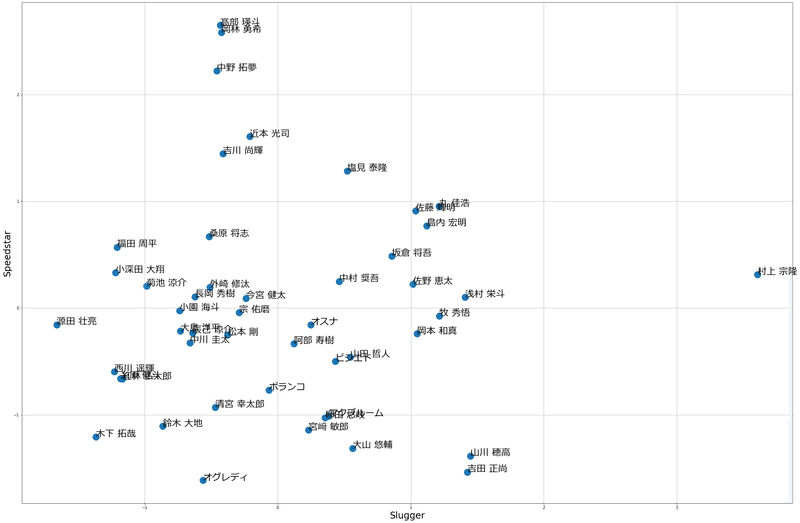
村上異次元すぎる~~~~~!!!!!
今年の村上選手がいかに異質な存在だったか、一目瞭然ですね。
OPSやWARでも異次元ですが、今回の分析でも村上選手は外れ値のようなスコアでした。
散布図からの気づき
村上選手以外にも、散布図からはいろいろなことが読み取れます。
例えば高部選手、岡林選手、中野選手あたりはとても近い位置にいます。
プロ野球ファンの方ならなんとなく、この3人には近いものがある、と共感いただけるのではないでしょうか。
そのほかにも「〇〇選手と××選手が近い位置にプロットされるのは納得」という感想や、「▢▢選手と△△選手が近いのは意外!」といった驚きもあるかと思います。
筆者の分析例
ここからはあくまで私の主観的な分析です。
私はざっくりと、このような分類ができるのではないか、と考えました。
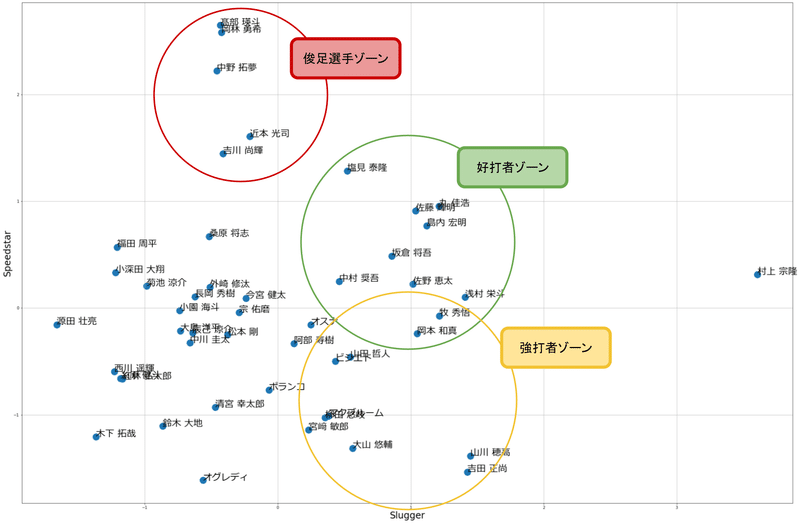
①Speedstar軸の上部に位置する5人は、1,2番を任されやすい俊足巧打の選手が位置しているので「俊足選手ゾーン」としました。
②散布図の中心に位置している選手は、チームの中核を担う打撃力を備えている選手が多いため、「好打者ゾーン」としました。
特に円の上側の選手は走力もあり、高いレベルでバランスの取れた選手だと思います。
③図の中央下部に位置する選手は、一発や長打が怖いバッターが多いため「強打者ゾーン」としました。
一部好打者ゾーンと被っている選手もいるイメージです。
いかがでしょうか。
円はあくまでも目安です。円から外れたらといって、無個性な選手ということではありません。
どの円により近いかで、選手の傾向が予測できます。
この分析について「いや、私はこう思う」といった意見があれば、ぜひコメントください。
分析の補足
今回は、下記条件で分析を行いました。
・2022年度規定打席の到達者のみ
・基本的な打撃成績のみ(守備指標を入れず)
・とりあえずすべての項目を分析対象に(打数なども入れた)
そもそも規定打席到達者のみの分析なので、分析対象に「打席数」を入れる必要はないかもしれません。
また、守備指標も分析対象とすると、例えば好守の外崎選手や長岡選手などは守備指標に引っ張られ、目立ったアウトプットが出てくることでしょう。
最後に
今回は利用規約上、UZRやWARなどのDELTA社が取り扱っているセイバーメトリクスデータは利用できませんでした……。
こういったデータも規約改正で利用できれば、より深い分析ができると思います。
(有料会員契約後にこの規約に気づきました……泣)
また、私自身データ分析の初心者なので、有識者の方からアドバイスをいただければ幸いです。
(追記)続編の記事を書きました!
続編を書きました。
変更点として期待値ベースでの再分析と、クラスタリングを行っています。よければご覧ください。
続・打者成績を主成分分析したら村上が異次元だった【再分析・クラスタリング編】
また気が向いたら不定期で記事を上げようと思います。
それではさようなら。
この記事が面白かったらおひねりをください。 いただいたお金は責任をもって、筆者のQOL上昇に役立たせていただきます。