
Gait Recognition via Disentangled Representation Learning(CVPR2019採択論文)を読んでみた

どらです.
私は20日まで夏季休暇でした.弊社ホワイト杉内.
そんな連休の最終日は,歯医者さんに行ったあとに,スタバでコーヒーを啜りながら論文を読んで過ごしました.
今回は,CVPR2019に採択された論文のうち自分の興味があるものをサラサラっと読みました.記憶があるうちに,自分の考えを整理するためにも内容をまとめていきたいと思います.
専門的な話になるので,機械学習をやっていない方はつまらないと思います.
専門の方は「説明がちがうぞ!」などあれば,優しくご教授くだされば幸いです.
ちなみにSlide Shareでまとめてくださっている方がいたのでリンクを貼っておきます.めっちゃ分かりやすいので,専門の方はそっちを見た方がいいかもです.
解説スライドのリンク
https://www.slideshare.net/TakujiTahara/20190722-lt-gait-recognition-via-disentangled-representation-learning
以下,原著のリンクです.
http://openaccess.thecvf.com/content_CVPR_2019/html/Zhang_Gait_Recognition_via_Disentangled_Representation_Learning_CVPR_2019_paper.html
Gait recognition
Gait recognition,日本語では歩容認証(または歩容認識)と訳します.
訳については色々と議論があったりするので,ここでは深く触れません.
歩容とは人の歩き姿のことを指します.ズバリ,歩容認証は人の歩き姿で誰かを当てちゃおうというタスクです.

ここで,コンビニ強盗を思い浮かべてください.
そのコンビニ強盗が目出し帽を被っていた場合,お店の監視カメラに犯人が映っていても誰か分からないので逮捕できません.しかし,歩容認証であれば,歩き姿だけで誰か分かるので,そのような場合でも特定可能です.
このように歩容認証は主に防犯,犯罪捜査などにおいてメリットがあり,世界でも研究が進められている分野です.
Disentangled representation
Disentangle,「もつれをほどく」という意味の英単語です.
人物認証を行うために,画像などのデータから何かしらの特徴を抽出し,その特徴を元に人物を照合します.例えば,天狗を顔認証する場面では,天狗の‟とっても長い鼻”,‟赤い体”などが特徴として考えられ,それを用いて照合を行うという感じです.
ここで,深層学習の登場です.近年のAIブームの火付け役ですね.深層学習のすごいところは,「何を特徴にしたらうまくいくか」を機械が自動で計算して見つけることができるという点にあります.しかし,「機械が顔の特徴をうまく獲得した!」という場合,私たち人間は,機械が顔のどんな特徴をうまく獲得したのか分かりません.
機械が計算した特徴はかなり複雑で,イメージとしては整理整頓されていない机の引き出しのような状態になっています.
そこで,特徴をごちゃまぜにしてまとめて扱わずに,できるだけ独立に表現するように機械に学習させよう!というのがDisentangled representation learningになります.
イメージとしては,引き出しの中に仕切りを設けて,整理整頓させようという感じです.
特徴を独立に扱えれば,人が理解しやすいし,それらを利用しやすい(他のタスクにも応用できちゃうかも)ってことですね.
論文の貢献
ここからグッと専門的な話になります.
歩容認証を機械学習を用いて行う場合,アピアランスベースとモデルベースの2つのアプローチがあります.

画像は原著論文より引用
アピアランスベースは画像から得られた歩き姿のシルエットから特徴抽出する手法(上図の例では一歩行周期分を平均したGEIを用いている),モデルベースは骨格モデルを作成し,それらを用いて推定した歩き方から特徴抽出する手法と考えてください.
アピアランスベースの手法は,扱いが簡単で,理想的な条件下において非常に高い精度で認証可能ですが,服装,歩行速度,カメラに映った身体の向きなど,現実に起こり得る見え方の変化の影響を大きく受けて性能が低下してしまうことが問題です.
モデルベースの手法の場合,純粋に歩き方のみから特徴抽出するため,アピアランスベースの手法と比較して,見え方の変化による悪影響は受けにくいですが,骨格推定の精度が認証性能に直結するうえ,計算コストも高く,実際のシステムとして社会に組み込むにはまだハードルが高いと言えます.
そこで,著者らは(おそらく)初めて歩容認証のための学習モデルにDisentangled representation learningを取り入れ,見え方の特徴と歩き方の特徴を分離することで,計算コストが小さく,モデルベースの手法のように見え方の変化を受けにくく,さらに高い性能をもつ認証手法を提案しました.
また,正面から撮影した歩容を集めたデータセットを新たに作成し,歩き方の特徴を得ることが困難な条件下でも,従来手法よりも高い性能を維持することを示しました.つまり,従来の歩容認証手法の問題点をまるっと解決した良いとこどりの手法を提案したということです.
提案手法

画像は原著論文より引用
提案手法ではAuto Encoderによる特徴抽出(見え方の特徴と姿勢特徴の分離),LSTMによる歩行シーケンスの姿勢特徴の統合をおこなっています.
人物認証はLSTMによって統合された姿勢特徴のみを利用して,SVMのような線形分類器によって行われます.
また,"分離された特徴表現"の獲得を成功させるため,著書らは新たに3つの損失関数を定義して学習をさせています.それぞれの損失関数について説明します.
Cross-reconstruction loss
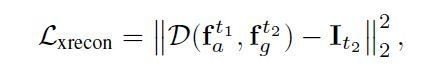
画像は原著論文より引用
入力画像から次元削減して何らかの情報をエンコードするとき,通常Auto Encoderには入力画像を復元するように出力画像を再構成させます.次元削減した情報には,綺麗に再構成できれば,入力画像の何らかの本質的な特徴を捉えたと言えるからです.通常,Auto Encoderの学習では入力画像と再構成画像の最小二乗誤差を損失として最小化します.しかし,このままでは本来の目的である分離された特徴を得ることができません.
そこで,歩行シーケンスのある時間t1の歩容画像から得た見え方の特徴と,時間t2(t1!=t2)の歩容画像から得た姿勢の特徴を用いて,時間t2の歩容画像を再構成するように学習させます.
このような設定で学習をさせることで,学習モデルは時刻t1の歩容画像から,t2の見え方の特徴を得なければならず,その結果,うまく特徴を分離することができるわけです.
Gait similarity loss

画像は原著論文より引用
上述したようにCross reconstruction lossにより,特徴の分離を行うことができそうですが,まだ一つだけ問題点があります.それはCross reconstruction lossのみで学習させた場合,学習モデルが時刻t2に得た歩容画像から姿勢の特徴だけでなく,見え方の特徴も獲得しようとするかもしれないということです.つまり,時刻t1で得た見え方の特徴が何であろうが,時刻t2で得た特徴だけで再構成ができてしまう可能性があるということですね.それでは特徴の分離ができなくなってしまいます.
そこで提案されたのがGait similarity lossです.要は同一人物から,服装などの条件が異なる2種の歩容画像列を取得し,それぞれの姿勢特徴の平均を求め,それらの差が小さくなるように学習させることで,できるだけ姿勢の特徴に特化させようということです.
Incremental identity loss

画像は原著論文より引用
最後は認証のための損失です.認証タスクの場合,学習で用いた人物IDとテストで用いる人物IDがまったく異なるため,一般的なクラスラベルの識別のように学習モデルに多クラス分類まで行わせることができません.そのため,学習モデルを特徴抽出器として扱い,その出力をSVMなどの線形分類器を用いて比較することがよく行われます.
著者らも同様に,抽出した姿勢の特徴をLSTMに入力し,その出力を線形分類器に入力して正解IDとの誤差を計算しています.注意点としては得られた歩行シーケンス分の加重平均を計算していることです.歩容は時系列データであるため,学習モデルには長い歩行シーケンスが得られるほど認証精度が高くなるような特徴を生成することが望まれます.そこで,後から入力されるデータほど大きい重みをつけて加重平均をとるという手法を用いています.

学習ではこれらの全ての損失を加算したものを最小化していますね.
実験結果

画像は原著論文より引用
これは異なる人物から抽出した見え方の特徴と,姿勢の特徴を合成した画像です.一行目が姿勢の情報を抽出した元画像,一列目が見え方の情報を抽出した元画像です.結果をみると見え方の特徴と姿勢の特徴を双方とも持ち合わせた合成画像となっていることが確認できます.
一番下の行は合成時に見え方の特徴をゼロベクトルにしたもの,右端の列は合成時に姿勢の特徴をゼロベクトルにして合成したものです.それぞれ特徴の分離がある程度できていることがわかります.

画像は原著論文より引用
こちらは,各lossの効果を確認できる合成画像です.2枚ずつの合成画像のうち1行目が姿勢の特徴を抽出した元画像,2行目がGait similarity lossを用いていない学習モデルで抽出した特徴で合成した画像.3行目がGait similarity lossを使用した画像です.
Gait similarity lossを使用しない場合ではコートの色は反映されているものの,コートの裾の形が姿勢の特徴を抽出した画像に引っ張られて合成されていることがわかります.一方Gait similarity lossを使用すると,特徴が分離されて双方の特徴をうまく表した合成画像となっています.

画像は原著論文より引用
認証精度においても,提案された全てのlossを使うときが最も高い性能を示しています.

画像は原著論文より引用
こちらが歩容を撮影したカメラの角度,被験者の携行品が異なる状況を再現したデータセットでの結果です.従来手法に比べ,著者らの提案手法は見え方の変化に頑健で,高い精度を保っています.
Front-View Gait Database(FVG)


画像は原著論文より引用
FVGは著者らが新規に作成した歩容データベースです.歩行の特徴が得られにくい正面から撮影され,服装,携行品,歩く速度,背景などの状況変化を含んでいます.こちらのデータベースにおいてもPE-LSTMのようなモデルベースの手法を超える性能を示しています.

画像は原著論文より引用
計算速度においても,モデルベースのPE-LSTMが合計22ms per frameで提案手法が1.5ms per frameと大きく改善し,その他のアピアランスベースの手法と比べても高速となっています.
感想
歩容認証ではアピアランスベースの手法が主流だったなかで,見えの変化による悪影響を軽減することはかなり難しい問題とされてきました.そこで,骨格の情報を推定するモデルベースの手法にトレンドを移りかけていたところ,著者らはこれらの手法の問題点を解決したDisentangled representation learningを取り入れてきました.Disentangled representation learningも最近は精力的に研究されているので,歩容認証でも,今後こちらに流れていくと思います.
提案手法では最終的には,姿勢の特徴(少しは見えも含まれちゃっている?)のみで認証を行っていましたが,アピアランスの特徴も認証において,非常に有効であるので,例えば肌の色など,服装などの影響を受けにくい特徴なんかも組み込めるといいなと思いました.Attention機構なんかが使えたらおもしろいかもしれないですね.
この記事が気に入ったらサポートをしてみませんか?