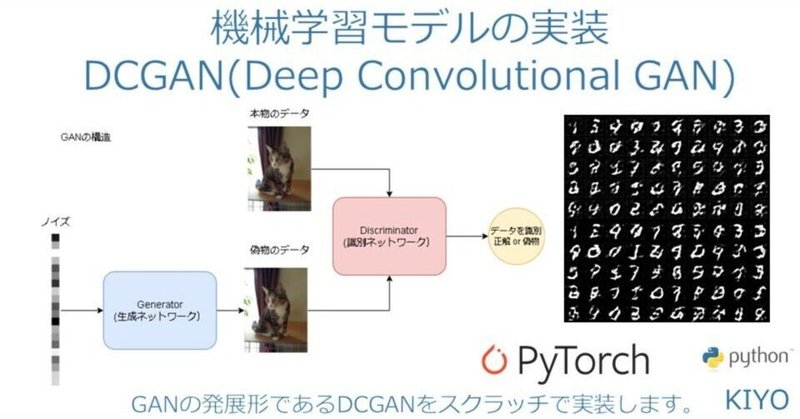
機械学習モデルの実装:DCGAN(Deep Convolutional GAN)

1.概要
本記事ではDCGANsをPytorchで実装します。ライブラリ紹介ではなく実装がメインのため学習シリーズに近い内容となります。
2.DCGANの概念理解
2-1.GANとは?
2014年にIan J. Goodfellow氏により発案された敵対的生成ネットワーク(GAN:Generative Adversarial Network)とは2つのネットワークを競わせながら学習させることで高品質な画像を創る生成モデルです。
【GANの2つのネットワーク】
●Generator(生成ネットワーク):ノイズ(ランダムな正規分布)から転置畳み込みなどにより画像を生成
●Discriminator(識別ネットワーク):画像を畳み込み演算などにより識別
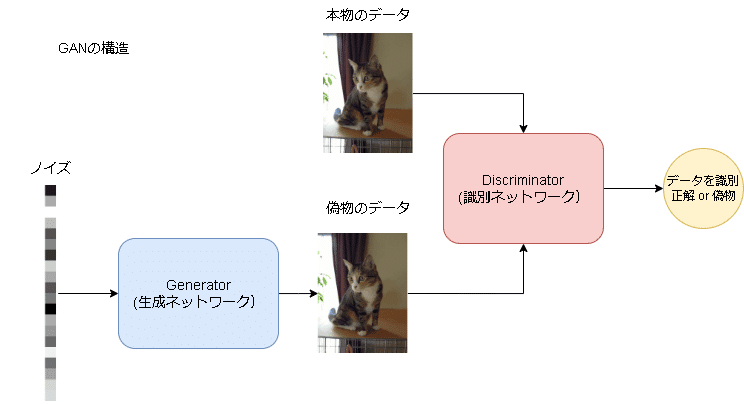
GANでは下記ステップにより生成器と識別器を交互に学習させることで生成するデータ(画像)の品質を向上させます。
【GANの学習手順※ラベルは正解:1, 偽物:0とする】
1.ノイズを生成器に入力してフェイク画像を作成
2.フェイク画像を識別器に入力して正解ラベル0(偽物)を出力するように識別器重みを更新する
3.識別器の学習完了後に、識別器が正解ラベル1(正解)を出力するように生成器の重みを更新する
VAEはノイズを加える過程をモデル化しており、この方法だと1ピクセル単位で最適化が行われるため生成画像がぼやけたりします(VAEは下記参照)。
GANはノイズを最適化するためより鮮明な画像が生成できます。
【参考:生成器に入力するノイズ】
今回の記事で使用する実際のノイズは下記の通りです。出力は画面の都合上90°回転させております。
[IN]
import torch
gn_input_dim = 100 # 生成器に入力するノイズの次元
batch_size = 1 # バッチサイズ
# エポックごとに出力する生成画像のためのノイズを生成:出力(bs, 100, 1, 1)
noise = torch.randn(batch_size, gn_input_dim, 1, 1, device=device)
import matplotlib.pyplot as plt
print(noise[0].shape)
plt.figure(figsize=(10, 10))
plt.imshow(noise[0].cpu().detach().numpy(), cmap='gray')
plt.axis('off')
[OUT]
noise.shape: torch.Size([1, 100, 1, 1])
(-0.5, 0.5, 99.5, -0.5)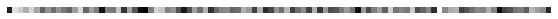
2-2.DCGANの特徴
2016年にAlec Radford氏らによって発案されたDCGANはGANの発展形です。GANより①大きな画像を生成、②深い層、③安定して学習 できます。そのための特徴は下記の通りです。
識別器はストライド2の畳み込み層
生成器はストライド2の転置畳み込み層
生成器の出力層(最終層)と識別機の入力層を除く全層で「バッチ正規化」を実施
畳み込み層のみを使用して全結合層(Affine Layer)は使用しない
生成器では出力層(最終層)を除くすべての層でReLU関数を使用する。最終層はTanh関数を使用する。
識別器ではすべての層でLeakyReLU関数を使用する:生成器の学習時(誤差逆伝搬)に識別器を通るため負の値をカットすると学習が進まなくなるため使用する。
3.MNIST(手書き数値)画像データの生成
MNISTをデータとして用いることでノイズから画像を生成します。
3-1.MNISTデータの理解およびデータ取得
MNIST(Mixed National Institute of Standards and Technology database)とは手書きの数値であり下記特徴があります。
学習用データ数:60,000枚、テスト用データ数:10,000枚
画像サイズは(1, 28, 28)の白黒データ
データサイズは8bitグレースケールであり0~255(int)である
MNISTデータは”torchvision.datasets”でラベルと合わせて取得可能です。
【datasetsの引数】
●root:保存ディレクトリ名を指定(なければ自動で作成される)
●train(True/False):学習用(True)か検証用(False)か
●download(True/False):データが指定フォルダ(root)に存在しないならDL
●transform{defalut:None}:T.ToTensor()を設定することで出力値がPIL形式からtorch.tensor形式になる
[IN]
import torch
import torchvision.datasets as datasets
import torchvision.transforms as transforms
# MNISTデータセット
dataset = datasets.MNIST(
root='MNIST',
download=True, #フォルダがなければダウンロード
train=False, #False:テストデータ
transform=transforms.Compose(
[transforms.ToTensor(), # Tensorオブジェクトに変換
transforms.Normalize((0.5,), (0.5,))] # データを平均0.5、標準偏差0.5の標準正規分布で正規化※チャネル数は1なのでタプルの要素も1
)
)
batch_size=50 # ミニバッチのサイズ
# DataLoaderの作成
dataloader = torch.utils.data.DataLoader(
dataset,
batch_size=batch_size,
shuffle=False,
)
# 使用可能なデバイスを確認
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print('device:', device)
print(dataset)
[OUT]
device: cuda:0
Dataset MNIST
Number of datapoints: 10000
Root location: C:/Users/moody/Desktop/note/04_機械学習・ディープラーニング/04. AutoEncoder(VAE)/MNIST
Split: Test
StandardTransform
Transform: Compose(
ToTensor()
Normalize(mean=(0.5,), std=(0.5,))
)
※MNISTフォルダが作成され、その中にデータが格納される:データそのものはtorchvision.datasets.MNISTのインスタンス化時に自動で取得・なおサンプルを1つ取り出して中身を見ると、下記が確認できます。
”torchvision.datasets”で取得したデータは(data, label)のTuple型
データセット取得時に"transform"で前処理しており画像データは1次元配列かつ正規化(min:-1, max:1)されている。
[IN]
import matplotlib.pyplot as plt
for (images, labels) in dataloader:
_im, _l = images[0], labels[0] #データローダーのバッチから1つだけ取り出す
break
print(f'data:{_im.shape}, label:{[_l]}')
print(f'最大値:{_im.max()}, 最小値:{_im.min()}')
plt.imshow(_im.reshape(28, 28), cmap='gray')
[OUT]
data:torch.Size([1, 28, 28]), label:[tensor(7)]
最大値:1.0, 最小値:-1.0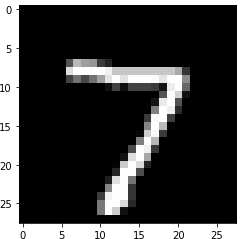
3-2.モデル作成/パラメータ設定
3-2-1.Discriminator(識別ネットワーク)作成
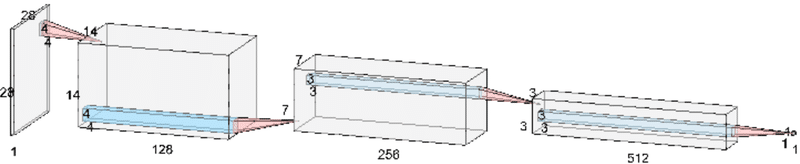
識別器のネットワークを構築するクラスを作成します。活性化関数:LeakyReLU(最終層はSigmoid:正誤判定を0~1の確率で出力)、過学習防止:バッチ正規化を使用してCNNで処理します。
[IN]
import torch.nn as nn
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
in_ch = 1 # 入力画像のチャネル数
start_ch = 128 # 先頭層の出力チャネル数
# 識別器のネットワークを定義する
# 第1層: (bs, 1, 28, 28) -> (bs, 128, 14, 14)
self.layer1 =nn.Sequential(
nn.Conv2d(in_ch, start_ch, 4, 2, 1), # 4×4のフィルター , ストライド:2, パディング:1
nn.LeakyReLU(negative_slope=0.2)) # 論文に従って負の勾配を制御する係数を0.2(デフォルトは0.01)に設定
# 第2層: (bs, 128, 14, 14) -> (bs, 256, 7, 7)
self.layer2 = nn.Sequential(
nn.Conv2d(start_ch, start_ch * 2, 4, 2, 1), # 4×4のフィルター , ストライド:2, パディング:1
nn.BatchNorm2d(start_ch * 2), # 出力値を正規化する(チャネル数は128×2)
nn.LeakyReLU(negative_slope=0.2)
)
# 第3層: (bs, 256, 7, 7) -> (bs, 512, 3, 3)
self.layer3 = nn.Sequential(
nn.Conv2d(start_ch * 2, start_ch * 4, 3, 2, 0), # 3×3のフィルター , ストライド:2, パディング:0
nn.BatchNorm2d(start_ch * 4), ## 出力値を正規化する(チャネル数は128×4)
nn.LeakyReLU(negative_slope=0.2)
)
# 第4層: (bs, 512, 3, 3) -> (bs, 1, 1, 1)
self.layer4 = nn.Sequential(
nn.Conv2d(start_ch * 4, 1, 3, 1, 0), # 3×3のフィルター , ストライド:1, パディング:0
nn.Sigmoid() # 最終出力にはシグモイド関数を適用
)
# ネットワークをリストにまとめる
self.layers = nn.ModuleList([self.layer1, self.layer2, self.layer3, self.layer4])
def forward(self, x):
for layer in self.layers:
x = layer(x) #x: 画像データまたは生成画像
return x.squeeze() ## 出力されたテンソルの形状をフラット(bs,)にする
[OUT]
-
3-2-2.Generator(生成ネットワーク)
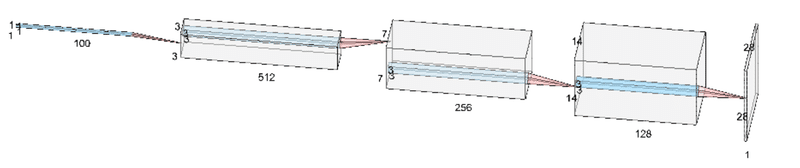
生成器のネットワークを構築するクラスを作成します。活性化関数:ReLU(最終層はTanh関数で-1.0~1.0にすることで初期画像と同じ範囲にする)、過学習防止:バッチ正規化を使用して転置畳み込みで処理します。
[IN]
import torch.nn as nn
class Generator(nn.Module):
def __init__(self):
super().__init__()
input_dim = 100 # 入力データの次元
out_ch = 128 # 最終層のチャネル数
img_ch = 1 # 生成画像のチャネル数
# 生成器のネットワークを定義する
# 第1層: (bs, 100, 1, 1) -> (bs, 512, 3, 3)
self.layer1 = nn.Sequential(
nn.ConvTranspose2d(input_dim, out_ch * 4, 3, 1, 0), # 3×3のフィルター , ストライド:1, パディング:0
nn.BatchNorm2d(out_ch * 4), # 出力値を正規化する(チャネル数は128×4)
nn.ReLU()
)
# 第2層: (bs, 512, 3, 3) -> (bs, 256, 7, 7)
self.layer2 = nn.Sequential(
nn.ConvTranspose2d(out_ch * 4, out_ch * 2, 3, 2, 0), # 3×3のフィルター , ストライド:2, パディング:0
nn.BatchNorm2d(out_ch * 2), # 出力値を正規化する(チャネル数は128×2)
nn.ReLU()
)
# 第3層: (bs, 256, 7, 7) -> (bs, 128, 14, 14)
self.layer3 = nn.Sequential(
nn.ConvTranspose2d(out_ch * 2, out_ch, 4, 2, 1), # 4×4のフィルター , ストライド:2, パディング:1
nn.BatchNorm2d(out_ch), # 出力値を正規化する(チャネル数は128)
nn.ReLU()
)
# 第4層: (bs, 128, 14, 14) -> (bs, 1, 28, 28)
self.layer4 = nn.Sequential(
nn.ConvTranspose2d(out_ch, img_ch, 4, 2, 1), # 4×4のフィルター , ストライド:2, パディング:1
nn.Tanh() # 最終出力にはtanh関数を適用
)
# ネットワークをリストにまとめる
self.layers = nn.ModuleList([self.layer1, self.layer2, self.layer3, self.layer4])
def forward(self, z):
for layer in self.layers:
z = layer(z) #z: ノイズデータ
return z
[OUT]
-
3-3.ネットワークの重みを初期化
DCGANの論文では重みを初期化しているためこれに従います。
[IN]
#重みの初期化 m: ネットワークのインスタンス
def weights_init(m):
# DCGANの論文では重みを正規分布からサンプリングした値で初期化している
classname = m.__class__.__name__
# 畳み込み層の重み
if classname.find('Conv') != -1:
m.weight.data.normal_(0.0, 0.02) # 平均0、標準偏差0.02の正規分布
m.bias.data.fill_(0) # バイアスのみ0で初期化
# バッチ正規化層の重み
elif classname.find('BatchNorm') != -1:
m.weight.data.normal_(1.0, 0.02) # 平均1.0、標準偏差0.02の正規分布
m.bias.data.fill_(0) # バイアスのみ0で初期化
[OUT]”Generator”クラス(生成器)をインスタンス化して重みを初期化します。
[IN]
import torchsummary
# 生成器Generator
generator = Generator().to(device)
generator.apply(weights_init) # 重みを初期化
# 識別器Discriminator
discriminator = Discriminator().to(device)
discriminator.apply(weights_init) # 重みの初期化
# 生成器のサマリを出力
torchsummary.summary(generator,
(100, 1, 1)) # 入力テンソルの形状
torchsummary.summary(discriminator,
(1, 28, 28)) # 入力テンソルの形状
[OUT]
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
ConvTranspose2d-1 [-1, 512, 3, 3] 461,312
ConvTranspose2d-2 [-1, 512, 3, 3] 461,312
BatchNorm2d-3 [-1, 512, 3, 3] 1,024
BatchNorm2d-4 [-1, 512, 3, 3] 1,024
ReLU-5 [-1, 512, 3, 3] 0
ReLU-6 [-1, 512, 3, 3] 0
ConvTranspose2d-7 [-1, 256, 7, 7] 1,179,904
ConvTranspose2d-8 [-1, 256, 7, 7] 1,179,904
BatchNorm2d-9 [-1, 256, 7, 7] 512
BatchNorm2d-10 [-1, 256, 7, 7] 512
ReLU-11 [-1, 256, 7, 7] 0
ReLU-12 [-1, 256, 7, 7] 0
ConvTranspose2d-13 [-1, 128, 14, 14] 524,416
ConvTranspose2d-14 [-1, 128, 14, 14] 524,416
BatchNorm2d-15 [-1, 128, 14, 14] 256
BatchNorm2d-16 [-1, 128, 14, 14] 256
ReLU-17 [-1, 128, 14, 14] 0
ReLU-18 [-1, 128, 14, 14] 0
ConvTranspose2d-19 [-1, 1, 28, 28] 2,049
ConvTranspose2d-20 [-1, 1, 28, 28] 2,049
Tanh-21 [-1, 1, 28, 28] 0
Tanh-22 [-1, 1, 28, 28] 0
================================================================
Total params: 4,338,946
Trainable params: 4,338,946
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 1.96
Params size (MB): 16.55
Estimated Total Size (MB): 18.51
----------------------------------------------------------------
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 128, 14, 14] 2,176
Conv2d-2 [-1, 128, 14, 14] 2,176
LeakyReLU-3 [-1, 128, 14, 14] 0
LeakyReLU-4 [-1, 128, 14, 14] 0
Conv2d-5 [-1, 256, 7, 7] 524,544
Conv2d-6 [-1, 256, 7, 7] 524,544
BatchNorm2d-7 [-1, 256, 7, 7] 512
BatchNorm2d-8 [-1, 256, 7, 7] 512
LeakyReLU-9 [-1, 256, 7, 7] 0
LeakyReLU-10 [-1, 256, 7, 7] 0
Conv2d-11 [-1, 512, 3, 3] 1,180,160
Conv2d-12 [-1, 512, 3, 3] 1,180,160
BatchNorm2d-13 [-1, 512, 3, 3] 1,024
BatchNorm2d-14 [-1, 512, 3, 3] 1,024
LeakyReLU-15 [-1, 512, 3, 3] 0
LeakyReLU-16 [-1, 512, 3, 3] 0
Conv2d-17 [-1, 1, 1, 1] 4,609
Conv2d-18 [-1, 1, 1, 1] 4,609
Sigmoid-19 [-1, 1, 1, 1] 0
Sigmoid-20 [-1, 1, 1, 1] 0
================================================================
Total params: 3,426,050
Trainable params: 3,426,050
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 1.55
Params size (MB): 13.07
Estimated Total Size (MB): 14.62
----------------------------------------------------------------【参考:クラスの特殊メソッドの動作確認】
コード内で使用されている特殊メソッドの動作を確認しました。__name__だと出力は文字列になります。findの動作は下記記事参照のこと。
[IN]
class KIYO:
def __init__(self):
self.A = 1
kiyo = KIYO()
print(kiyo.__class__, type(kiyo.__class__))
print(kiyo.__class__.__name__,type(kiyo.__class__.__name__))
[OUT]
<class '__main__.KIYO'> <class 'type'>
KIYO <class 'str'>3-4.損失関数・最適化関数の設定
損失関数はBCE、最適化関数はAdam(初期値を設定)を使用します。ポイントとして生成器と識別器をそれぞれ個別に学習できるよう最適化関数は2つに分けて作成します。
[IN]
import torch.optim as optim
criterion = nn.BCELoss() # 損失関数はバイナリクロスエントロピー誤差
# 識別器のオプティマイザ−を設定
optimizer_ds = optim.Adam(discriminator.parameters(),
lr=0.0002, # デフォルトの学習率0.001を論文で提案されている0.0002に変更
betas=(0.5, 0.999) # 指数関数的減衰率としてデフォルトの(0.9, 0.999)のβ1の値のみ論文で提案されている(0.5, 0.999)に変更
)
# 生成器のオプティマイザーを設定
optimizer_gn = optim.Adam(generator.parameters(),
lr=0.0002,
betas=(0.5, 0.999)
)
[OUT]
-3-5.学習
前述で作成した「Generator」と「Discriminator」を使用して学習していきます。ポイントは下記の通りです。
【GAN学習時のポイント】
●生成器に入れるノイズは標準正規分布(randn)を使用
●生成器・識別器を学習時に正誤判定できるため正解:1、偽物:0とした
ー>識別器が学習する時は正解画像の識別で1、偽物で0を渡す
ー>生成器を学習する時は偽物画像に対して識別器のlabelに1を渡す
●学習時のnoize(標準正規分布に従う乱数)は乱数値だが結果確認(各Epochでの学習状況)するときは同じ条件で確認するため同じ値のノイズを使用した(よって学習用とは別に確認用ノイズfixed_noiseを用意)。
●学習後はノイズ(乱数値)から学習させたデータ(MNIST:手書き数値)とほぼ同じ画像が生成されていることが確認できた。つまり学習させるデータにより様々な画像が生成できることが理解できる。
[IN]
%%time
'''
9. 学習を行う
'''
import torchvision.utils as vutils
# パラメータの設定
dir_output = 'result' # 画像の保存先のパス※環境に合わせて要変更
n_epoch = 10 #学習回数
gn_input_dim = 100 # 生成器に入力するノイズの次元
batch_size=50 # ミニバッチのサイズ
# エポックごとに出力する生成画像のためのノイズを生成
fixed_noise = torch.randn(batch_size, gn_input_dim, 1, 1, device=device)
# 学習のループ
for epoch in range(n_epoch):
print('Epoch {}/{}'.format(epoch + 1, n_epoch))
for itr, data in enumerate(dataloader):
#正解データ
real_image = data[0].to(device) # ミニバッチのすべての画像を取得
sample_size = real_image.size(0) # 画像の枚数を取得(バッチサイズ)
real_target = torch.full((sample_size,), 1., device=device) # オリジナル画像に対する識別信号の正解値「1」で初期化
#偽物(ノイズ)データ
noise = torch.randn(sample_size, gn_input_dim, 1, 1, device=device) # 標準正規分布からノイズを生成: 出力(bs, 100, 1, 1)
fake_target = torch.full((sample_size,), 0., device=device) # 生成画像に対する識別信号の正解値「0」で初期化
# -----識別器の学習-----
#正解データを識別器に入力
discriminator.zero_grad() # 識別器の誤差の勾配を初期化
output = discriminator(real_image) # 識別器に画像を入力して識別信号を出力(Sigmoidを通すため0~1)
ds_real_err = criterion(output, real_target) # # オリジナル画像に対する識別値の損失を取得:正解ラベル(1)
true_dsout_mean = output.mean().item() # 1ステップ(1バッチ)におけるオリジナル画像の識別信号の平均
#偽物データを識別器に入力
fake_image = generator(noise) # ノイズを生成器に入力してフェイク画像を生成
output = discriminator(fake_image.detach()) # フェイク画像を識別器に入力して識別信号を出力
ds_fake_err = criterion(output, fake_target) # フェイク画像を偽と判定できない場合の損失:正解ラベル(偽物の0)
fake_dsout_mean1 = output.mean().item() # フェイク画像の識別信号の平均
# オリジナル画像とフェイク画像に対する識別の損失を合計して識別器としての損失を求める
ds_err = ds_real_err + ds_fake_err
ds_err.backward() # 識別器全体の誤差を逆伝播
optimizer_ds.step() # 判別器の重みのみを更新(生成器は更新しない)
# -----生成器の学習-----
generator.zero_grad() # 生成器の誤差の勾配を初期化
output = discriminator(fake_image) # 更新した識別器に再度フェイク画像を入力して識別信号を取得
gn_err = criterion(output, real_target) # フェイク画像をオリジナル画像と誤認できない場合の損失:誤認させるのが目的なので正解ラベルは1
gn_err.backward() # 更新後の識別器の誤差を逆伝播
fake_dsout_mean2 = output.mean().item() # 更新後の識別器のフェイク画像に対する識別信号の平均
optimizer_gn.step() # 生成器の重みを更新後の識別誤差の勾配で更新
# 100ステップごとに結果を出力(testデータ1万枚, batch=50より200ステップ->1epochで2回表示)
if itr % 100 == 0:
print('({}/{}) ds_loss: {:.3f} - gn_loss: {:.3f} - true_out: {:.3f} - fake_out: {:.3f}>>{:.3f}'
.format(
itr + 1, # ステップ数(イテレート回数)
len(dataloader), # ステップ数(1エポックのバッチ数)
ds_err.item(), # 識別器の損失
gn_err.item(), # フェイクをオリジナルと誤認しない損失
true_dsout_mean, # オリジナル画像の識別信号の平均
fake_dsout_mean1, # フェイク画像の識別信号の平均
fake_dsout_mean2) # 更新後識別器のフェイクの識別信号平均
)
# 学習開始直後にオリジナル画像を保存する
if epoch == 0 and itr == 0:
vutils.save_image(real_image,f'{dir_output}/real_samples.png', normalize=True,nrow=10)
# 1エポック終了ごとに生成器が生成した画像を保存
fake_image = generator(fixed_noise) # バッチサイズと同じ数のノイズを生成器に入力
vutils.save_image(fake_image.detach(),f'{dir_output}/generated_epoch_{epoch + 1:03d}.png',
normalize=True, nrow=10)
[OUT]
Epoch 1/10
(1/200) ds_loss: 2.056 - gn_loss: 0.349 - true_out: 0.581 - fake_out: 0.727>>0.727
(101/200) ds_loss: 2.182 - gn_loss: 0.357 - true_out: 0.514 - fake_out: 0.718>>0.718
Epoch 2/10
(1/200) ds_loss: 1.780 - gn_loss: 0.456 - true_out: 0.581 - fake_out: 0.657>>0.657
(101/200) ds_loss: 2.275 - gn_loss: 0.356 - true_out: 0.514 - fake_out: 0.724>>0.724
Epoch 3/10
(1/200) ds_loss: 1.930 - gn_loss: 0.393 - true_out: 0.581 - fake_out: 0.699>>0.699
(101/200) ds_loss: 2.114 - gn_loss: 0.410 - true_out: 0.514 - fake_out: 0.688>>0.688
Epoch 4/10
(1/200) ds_loss: 1.995 - gn_loss: 0.383 - true_out: 0.581 - fake_out: 0.708>>0.708
(101/200) ds_loss: 2.368 - gn_loss: 0.311 - true_out: 0.514 - fake_out: 0.751>>0.751
Epoch 5/10
(1/200) ds_loss: 1.946 - gn_loss: 0.406 - true_out: 0.581 - fake_out: 0.692>>0.692
(101/200) ds_loss: 2.108 - gn_loss: 0.393 - true_out: 0.514 - fake_out: 0.696>>0.696
Epoch 6/10
(1/200) ds_loss: 1.903 - gn_loss: 0.397 - true_out: 0.581 - fake_out: 0.693>>0.693
(101/200) ds_loss: 2.259 - gn_loss: 0.341 - true_out: 0.514 - fake_out: 0.730>>0.730
Epoch 7/10
(1/200) ds_loss: 1.958 - gn_loss: 0.396 - true_out: 0.581 - fake_out: 0.699>>0.699
(101/200) ds_loss: 2.038 - gn_loss: 0.421 - true_out: 0.514 - fake_out: 0.677>>0.677
Epoch 8/10
(1/200) ds_loss: 1.940 - gn_loss: 0.393 - true_out: 0.581 - fake_out: 0.698>>0.698
(101/200) ds_loss: 2.184 - gn_loss: 0.381 - true_out: 0.514 - fake_out: 0.708>>0.708
Epoch 9/10
(1/200) ds_loss: 1.964 - gn_loss: 0.408 - true_out: 0.581 - fake_out: 0.692>>0.692
(101/200) ds_loss: 2.133 - gn_loss: 0.379 - true_out: 0.514 - fake_out: 0.705>>0.705
Epoch 10/10
(1/200) ds_loss: 1.856 - gn_loss: 0.390 - true_out: 0.581 - fake_out: 0.689>>0.689
(101/200) ds_loss: 2.111 - gn_loss: 0.377 - true_out: 0.514 - fake_out: 0.703>>0.703
Wall time: 1min 31s
【参考:Epochごとの生成画像】
生成された画像がどのように学習されているか確認します。前述の通りnoiseは固定値です。一番上が1回目学習後、下から2番目が10回目、一番下が正解データです。
[IN]
from PIL import Image
import glob
def image_grid(imgs, rows, cols):
assert len(imgs) == rows*cols #画像の枚数がrows*colsと一致するか確認
w, h = imgs[0].size #画像のサイズを取得
grid = Image.new('RGB', size=(cols*w, rows*h)) #新しい画像を作成
grid_w, grid_h = grid.size #新しい画像のサイズを取得
for i, img in enumerate(imgs):
grid.paste(img, box=(i%cols*w, i//cols*h)) #画像を貼り付ける
return grid
# ファイルパス取得
path_imgs = glob.glob(f'{dir_output}/*.png')
print(len(path_imgs), path_imgs) #ファイルパス取得
# 画像読み込み
images = [Image.open(path) for path in path_imgs] #PIL形式で開く
#画像の表示
grid = image_grid(images, rows=len(path_imgs), cols=1) #2行4列の結合画像を作成
grid
[OUT]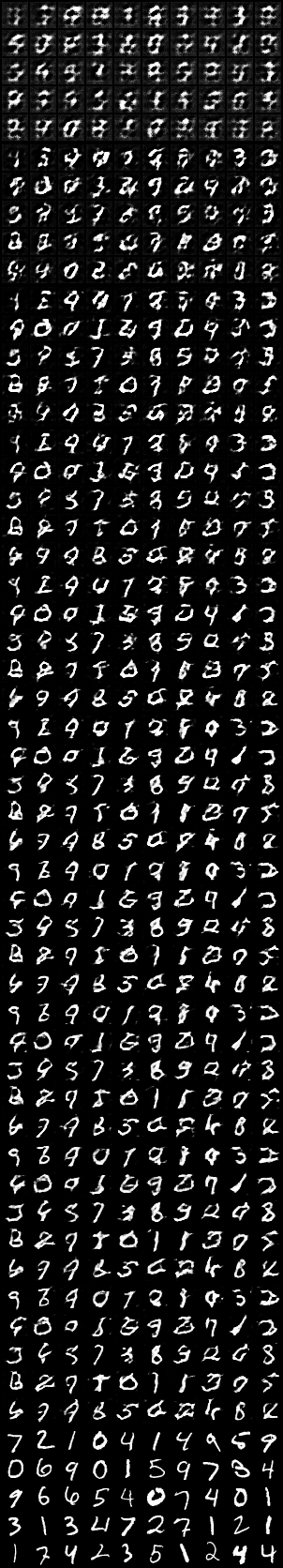
【参考:torch.full()で連続データ生成】
バッチ数分の正解:1, 偽物:0のラベルは"torch.full((<バッチ数, >), <配列で埋めたい値>, devide=<デバイス>)"で作成できます。
[IN]
sample_batch = 3
torch.full((sample_batch, ), 1.0, device=device)
[OUT]
tensor([1., 1., 1.], device='cuda:0')4.GANの更なる理解へ
4-1.GANの難しさ
GANを安定させるには下記のような課題があります。専門家ではないため用語だけ紹介します。
モード崩壊:GANが同じような画像ばかり生成する状態(多様性がなくなっている状態)
生成器と識別器のバランスが悪く十分な学習ができない
4-2.訓練ループの止め時:ナッシュ均衡
前章で紹介の通り「生成器を学習して訓練器をだます」と「訓練器を学習して生成器を見破る」を繰り返すのであれば訓練ループの辞め時が決められません。理屈上は識別器の正答率が50%(つまりランダムに推定)の場合に収束したということができ、この状態をナッシュ均衡状態といいます。
GANに対してナッシュ均衡を見つけることはほとんど不可能となります。ただし、出力結果を見てわかる通り理論的なナッシュ均衡でなくても高品質な画像を生成することが出来るため
参考資料1:実装・コード用
参考資料2:技術用
あとがき
本当はいろいろなGAN(プログレッシブGAN、半教師ありGAN、条件付きGAN、Cycle GAN)を1から実装したいけど、時間がないし根本的な部分は同じだと思うのでとりあえず学習はいったん中止しよう。
この記事が気に入ったらサポートをしてみませんか?