
【STATA Techs-008】重回帰分析

THEME:重回帰分析
GOAL:STATAで重回帰分析をできるようになる。
◯データセット◯
◯データセットの処理◯
・性別(sex):1=男性、2=女性
・年齢(age):実数
・雇用形態(emp):1=経営者・役員、2=常用雇用、3=臨時・パートアルバイト、4=派遣社員、5=自営業、6=自営業の家族従業者、7=内職、8=その他
・業務内容(job):1=農林漁業、2=技能・労務、3=販売・サービス、4=事務・営業、5=専門・技術、6=管理職、7=その他
・世帯年収(income_household):1=収入なし、2=100万未満、3=100-200万、4=200-300万、5=300-400万、6=400-600万、7=600-800万、8=800-1,000万、9=1,000-1,500万、10=1,500-2,000万、11=2,000万以上
・健康状態(health):1=健康である、2=まあ健康である、3=あまり健康でない、4=健康でない
・生活満足度(satification):1=満足している、2=どちらかと言えば満足している、3=どちらとも言えない、4=どちらかと言えば不満である、5=不満である
・自治体規模(citysize):1=14大都市、2=その他市部、3=人口1万人以上の郡部、4=人口5000~9999人の郡部、5=人口5000人未満の郡部
・地域(region):1=北海道・東北、2=関東・甲信、3=北陸、4=近畿、5=中国、6=九州・沖縄
↓↓↓↓
・性別(sex):0=男性、1=女性
・年齢(age):そのまま
・雇用形態(emp):1=経営者・役員、2=常用雇用、3=非正規雇用(3+4)、4=自営業(5~7)、5=その他(8)
・業務内容(job):そのまま *欠損値処理のみ(888と999)
・世帯年収(income_household):0=収入なし(1)、100万未満(2)=50、100-200万(3)=150、200-300万(4)=250、300-400万(5)=350、400-600万(6)=500、600-800万(7)=700、800-1,000万(8)=900、1,000-1,500万(9)=1,250、1,500-2,000万(10)=1,750、2,000万以上(11)=2,000
・健康状態(health):そのまま *欠損値処理のみ(999)
・生活満足度(satification):そのまま *欠損値処理のみ(999)
・自治体規模(citysize):1=14大都市、2=その他市部、3=郡部(3~5)
・地域(region):そのまま
recode sex 1=0 2=1
recode emp 3=3 4=3 5=4 6=4 7=4 8=5 888=. 999=.
recode job 888=. 999=.
recode income_household 1=0 2=50 3=150 4=250 5=350 6=500 7=700 8=900 9=1250 10=1750 11=2000 999=.
recode health 999=.
recode satification 999=.
recode citysize 3=3 4=3 5=3◯使用コマンド◯
reg varname1 varname2 … varnameX
:varname1を被説明変数(y)、varname2からvarnameXを説明変数(x)とした時の重回帰分析を実行し、回帰係数等を返す
◯やり方◯
①世帯年収 = 性別、年齢
まずは、被説明変数を世帯年収(「income_household」)にとり、性別(「sex」)と年齢(「age」)を説明変数にとった重回帰分析を行ってみましょう。重回帰分析の被説明変数は実数(量的変数)でなければいけませんが、x項は2値変数でも量的変数でもどちらでも大丈夫です。式とコマンドは以下です。
income_household = β0 + β1*sex + β2*age + u
なお、性別はダミー変数ですが、2値変数なので、そのまま挿入して構いません。コマンドは以下です。
reg income_household sex age
ここで返された指標の説明は上の記事でもまとめましたが、再度確認しましょう。
・Number of obs:観測数
・R-squared:決定係数(相関係数の2乗)=回帰分析の当てはまり具合
・Adj R-squared:自由度調整済み決定係数
・Coef.:推定係数
・Std.Err:標準誤差
・P>|t|:P値=仮説検定(自分が設定した仮説が正しいかどうかを統計的に判定する方法)において、元データの指標が、サンプルから観察された値と等しいか、それよりも大きな(小さな)値をとる確率)
・95% Conf. Intervall:95%信頼区間
・_cons:切片
サンプルサイズが1,322、自由度調整済み決定係数が0.0269の分析結果が得られました。ちなみに、決定係数(R-squared)が高ければ、当てはまりがいいモデルといえるますが、説明変数を追加していけばいくほど、決定係数は高くなります。そのため、自由度調整済み決定係数(Adj R-squared)を使用することが大事です。
モデル自体は、sexの推定係数は14.10(標準誤差21.33、95%信頼区間 -27.75012から55.9526)で有意ではありませんでした。他方、ageの推定係数は-4.848(標準誤差0.79、95%信頼区間-6.414187から-3.283364)で、1%水準で有意のようです。年齢が1歳上がるほど、世帯年収は5万円弱減っていくということのようです。サンプルデータなので現実に即しているかどうかはともかく、データ的にそれがありそうか、みてみましょう。これも単回帰分析の編でやったコマンドを使っています。これを見ると、このデータセットでは確かに年齢による世帯年収の逓減が起こるようです。
twoway scatter income_household age, jitter(5) || lfitci income_household age ||, by(sex, total row(1))
②ダミー変数を使った重回帰分析
次に、ダミー変数を使った重回帰分析を行ってみましょう。先ほどのコマンドに、雇用形態(「emp」)を足してみます。empは数値自体に意味を持たない質的変数(カテゴリ変数)ですので、ダミー変数として重回帰の式に入れ込まなければなりません。その場合は、[i.]オプション(接頭辞)をつけます。
reg income_household sex age i.emp
「i.emp」を付け加えることで、emp=1(経営者・役員)をベースダミーにしたempカテゴリーがモデルに加えられました。これでもって推定係数やP値、信頼区間等を解釈していくわけですが、特段、ベースカテゴリーを指定することをしなければデフォルトでベースタミーは1になります。なお、ベースダミーを任意の数値にすることも可能です。例えば、ダミーの中で最も低い推定係数を示している3の「非正規雇用」をベースダミーとして考えたいときは、「 ibX.varname」とし、Xに3を入れます。そうすると、empカテゴリー内の推定係数は「非正規雇用」をベースダミーとした時の値になります。
reg income_household sex age ib3.emp
次に、カテゴリ変数同士交互作用効果(交互作用は2つの因子が組み合わさることで初めて現れる相乗効果のこと)を知りたい時、交差項を重回帰式に入れる必要があります。例えば、単純に雇用形態だけでみるのではなく、性別も考慮した雇用形態の影響を見たい場合、性別と雇用形態ダミーを掛け合わせた交差項を式に入れます。その際は「#」を使用します。「i.varname1#i.varname2」とした際はvarname1とvarname2の交互作用効果だけを検討し、「i.varname1##i.varname2」と#を2つ重ねると、varname1とvarname2の主要効果と交互作用効果を同時に検討してくれます。おそらくこれだけの説明ではイメージしずらいですが、コマンドの式を見ればわかりやすいです。下の式では「#」と「##」の式をそれぞれ用意しましたが、「#」の式では主要効果を入れた後に「i.sex#i.emp」という交差項を入れているのに対して、「##」の式では「i.sex##i.emp」という交差項を入れれば主要効果と交互作用効果の両方を検討してくれるため、主要効果の「i.sex」「i.emp」をそれぞれ入れる必要がありません。
reg income_household age i.sex i.emp i.sex#i.emp
| |
reg income_household age i.sex##i.emp
実際に同じ結果になるのか見てみましょう。違いがわかりやすいように、「reg income_household age i.sex#i.emp」というモデルもやってみましょう。
reg income_household age i.sex i.emp i.sex#i.emp
reg income_household age i.sex##i.emp
reg income_household age i.sex#i.emp


最初2つの結果と最後の結果が微妙に違うことがわかりますが、回帰分析や分散分析では基本的には「reg income_household age i.sex#i.emp」のように交差項のみを入れることはないので「##」のみを使うか、主要効果の入れた上で「#」を使った交差項を入れるかのいずれかであると思います。
③marginsコマンドを使った回帰予測(質的変数)
②に関連して、marginsコマンドを使えば、②で追加したカテゴリ変数であるvarnameX以外の変数が平均値をとったときに、varnameXがそれぞれどういう値を取るのか、簡単に予測することができます。手順は、①重回帰分析を行い、②marginsコマンドを走らせ、③marginsplotで図を表示させる。今回は、「reg income_household i.sex age i.emp」において、量的変数「age」が平均の値をとったときに、カテゴリ変数「emp」の1~5の「income_household」が何の値になるか、そして標準偏差はどのくらいかをみます。コマンドは以下の通りです。
reg income_household i.sex age i.emp
margins emp, atmeans
marginsplot
まず、sexとageの平均がそれぞれ0.51、42.55歳となっています。「性別の平均」というと奇妙ですが、機械的にやっているためしょうがないですね。次に、empの1~5の平均が示されていますが、これは相対度数が返されていて、累積(Σ)すると1になります。推定値は「Margin」列に列挙されているようなものになり、図で示すと下のようになります。

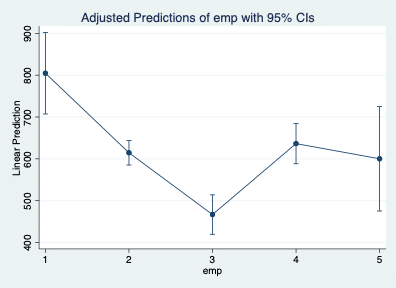
ちなみに、marginsコマンドは重回帰の式で[i.]オプション(接頭辞)をつけたものにしか使えませんが、「sex」もカテゴリ変数ではあるので、重回帰の式で「i.sex」とすれば性別ごと、など複数のカテゴリ変数を変化させた推定値をmarginsplotすることができます。
なお、marginsplotのオプションは以下のようなものです。
margins i.varname, atmeans
marginsplot, OPTION
<OPTION>
・x(varname):x軸に使う変数を指定する
・by(varname):指定した変数の値ごとにグラフを作る
・noci:信頼区間を表示しない
reg income_household i.sex age i.emp
margins i.sex##i.emp, atmeans
marginsplot, x(emp)

これで男女別雇用形態別の推定値を示すことができました。ただ、この重回帰分析(reg income_household i.sex age i.emp)では前の項でやったような、交互作用項が検討されていないので、男女の所得差が主要効果分並行移動されただけになっていて、雇用形態と性別の交互作用効果が考えられていません。ですので、そもそもの重回帰分析の式に交差項を入れる必要があります。確認ですが、作成する式は①と②はどちらでも構いません。やってみましょう。
①reg income_household age i.sex##i.emp
②reg income_household age i.sex i.emp i.sex#i.emp
reg income_household age i.sex##i.emp
margins i.sex##i.emp, atmeans
marginsplot,x(emp)
これでそれっぽい図になりました。
もっとも、モデル式にカテゴリ変数を追加すれば、marginsコマンドで〜##〜##〜と増やすこともできますが、下の図のようにごちゃごちゃになるのでお勧めしません。
reg income_household age i.sex##i.emp i.region
margins i.sex##i.emp##i.region, atmeans
marginsplot,x(emp)
上の図のように、3つの質的説明変数を変化させて予測値を計算し、グラフ化するときは、marginsplotの方をいじります。試しに、地域別(「region」)で見ていきたいので、by(region)をmarginsplotのオプションとして入れてみましょう。コマンドは以下です。ちなみに、by(varname)として指定できるのは、重回帰分析の式およびmarginsコマンドに含んでいる質的変数しか定義づけされていないので指定できません。
reg income_household age i.sex##i.emp i.region
margins i.sex##i.emp##i.region, atmeans
marginsplot, x(emp) by(region)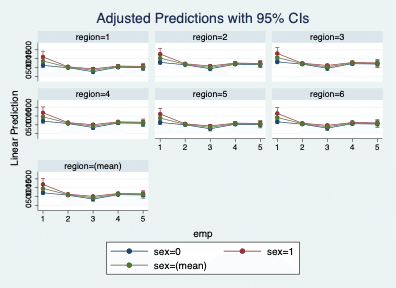
④marginsコマンドを使った回帰予測(量的変数)
次に、量的変数の回帰予測です。やり方は先ほどのカテゴリ変数の時とさほど変わりませんのでやってみましょう。
例えば、「reg income_household age i.sex##i.emp」という重回帰式に関して、量的変数である「age」を変化させて予測値を計算し、グラフ化してみます。カテゴリ変数の時のmarginsコマンドは「margins カテゴリ変数, atmeans」でしたが、量的変数の場合は、「margins, at(量的変数 = X軸のメモリの設定),atmeans」という形をとります。コマンドは以下です。
reg income_household age i.sex##i.emp
margins, at(age=(10 20 30 40 50 60 70 80)) atmeans
marginsplot
ちなみに、X軸のメモリの設定は現在「10 20 30 40 50 60 70 80」としていますが、いちいち書くのが面倒であれば、「10 (10) 80」(「10歳から80歳までを10歳間隔で」)と書き換えることもできます。「(10)」は「10単位ごとに」を指示するコマンドですので、「(5)」とすれば5歳間隔で示してくれます。
次に、年齢の変化だけでなく、雇用形態(「emp」)ごとの性別を考慮した年齢変化による世帯年収(「income_household」)の変化をみたい場合、marginsコマンドとカンマの間に予測したい変数を入れます。今回は「i.sex#i.emp」としましょう。「i.sex##i.emp」と#を2つ重ねてもいいのですが、主要効果を考慮することは、性別を平均値(means)とした時のグラフ入れることと同義なので、グラフが見にくくなります。今回は省いてみましょう。
reg income_household age i.sex##i.emp
margins i.sex#i.emp, at(age=(10 (10) 80)) atmeans
marginsplot,by(emp)

では最後に、実数とカテゴリ変数の交差項を考える時はどうすればいいのか。その際は、実数の前に[c.]接頭辞をつけ、実数であることを指示するのです。あとは、これまでと同じです。今回は男女の2つのグラフとして表示させましょう。
reg income_household c.age##i.sex##i.emp
margins i.sex#i.emp, at(c.age=(10 (10) 80)) atmeans
marginsplot,by(sex)
======
本田恒平(Kohei Honda)
一橋大学大学院経済学研究科博士後期課程(政治経済学、労働政策)
▼質問やご意見等はコメントかホームページのフォームから▼
この記事が気に入ったらサポートをしてみませんか?