
NVIDIAが切り開いたAI半導体市場: 市場の拡大と細分化(1)主要半導体メーカー編

生成AIとともに拡がりを見せているAI半導体ブームですが、NVIDIAの現在の支配的地位については、広く知られる状況にあります。
実際、市場シェアの90%以上を占めるとされるNVIDAのデータセンター向けのGPUの売上は、2023年に入ってから躍進を続け、2024年Q2決算での売上が103.2億ドルと前年同期比171%の増加、そして2024年Q3の売上が145.1億ドルと前年同期比279%増という凄まじい成績を上げています。
そして、このAI半導体市場、米Gartnerが2023年8月に発表したAI半導体の市場予測では、2023年の売上534億米ドル(前年比21%増)から、2027年には、2倍を超える1,194億ドルに達すると予想されています。この記事を書いている2024年2月からすると、意外とコンサバティブな数字と思えてしまうほど、現在もなお、生成AIブームは盛り上がりが続けている状況です。実際、AMDのCEOは、2023年12月の同社イベントで、4年後には4,000億ドルを超えるAI半導体市場が生まれる、と発言して周囲を驚かせたりしています。

そして、盛り上がりを見せているこの市場を誰もが見過ごすわけはありません。AI半導体市場が拡大していく中で、新たなプレイヤーが新たなビジネスチャンスを獲得しようとこの市場に参入してきています。
NVIDIAの優位性、つまりハードウェアやソフトウェア、そしてエコシステム全体を通じて圧倒的に市場を先行しているNVIDIAのポジションがすぐに揺らぐ状況ではありませんが、これからAIの社会実装が進むにつれ、AI半導体への需要がさらに拡大して大きな市場を創り上げていく過程では、AIのアーキテクチャやアプリケーションの形態も変化し、市場も細分化していくことが予想されます。つまり、直接NVIDIAと市場シェア争いを繰り広げるプレイヤーだけではなく、市場の拡大にともなって新たな生まれる参入領域にNVIDIAと直接競合しないかたちで多くの市場プレイヤーが参入してくることも予想されます。
今回は、NVIDIAと直接競合する大手半導体メーカーの現在をスナップショットし、現在彼らがどの様な品揃えでAI半導体市場にチャレンジしているのかを紹介したいと思います。
1. AIアクセラレーターの市場トレンドについて
メーカーと需要家、そして新規参入者が様々に渦巻いているこのAI半導体市場ですが、市場を俯瞰すると観察可能な主要なトレンドを最初に共有します。
※ これ以降、AI半導体ではなく、AIアクセラレーターという言葉を使います。このAIアクセラレーターは、GPUやASIC、SoCなどのハードウェアのフォームファクターだけでなく、ソフトウェアアクセラレーターなども含む、AIタスクを高速処理するための技術の総称です。
① 需給のギャップ
ようやく最近、NVIDIAのGPU製品「H100」の品不足が緩和されてきたようですが、まだ売り手市場は続いています。市場が拡大するにつれて市場のパイが拡がり、NVIDIA以外の企業の目の前にも市場が拡がります。その結果、大手半導体メーカーのみならず、技術と体力を兼ね備えた企業の市場参入や新たな技術を携えた新興企業の市場参入する機運も高まって行くことが予想されます。
② コンピューティングアーキテクチャ
全てのAIタスクをデータセンター上の高性能サーバーで集中処理するのではなく、異なる複数の仕組みで分散処理させるアーキテクチャの研究開発は、いつの時代でも行われています。このような潮流は、単にサーバー側の負荷分散という目的だけでなく、遅延の削減やプライバシー保護などのメリットも生み出すことになります。
③ 汎用型と特化型
NVIDIAがそのGPUとソフトウェア開発プラットフォームで様々な業種業態のAIアプリケーションニーズに応えられるよう、全方位的な汎用プラットフォーム戦略を展開しています。これに対し、特定のAIタスクであったり、エッジデバイス用のチップや低消費電力チップなど、特定領域での強みに特化した製品を開発する企業が存在し、それには多くのスタートアップ企業も含まれています。
④ 自社開発を進めるクラウドプラットフォーマー
これまでGPUの大口需要家であった巨大クラウドプラットフォーマーも自社のAIタスクに最適化したカスタムプロセッサーの開発を進めています。早い時期から実用化しているGoogleやAWS、またNVIDIAのGPU安定供給に懸念を抱くMicrosoftやMeta Platformも自社向けのASICの設計開発を進めています。
⑤ リソースの適材適所配置
AIの利用シーンが拡大するにつれて、各AIアプリケーションに必要なコンピューティングリソースにも変化が来ます。すべてのAIタスクが最高スペックのGPUを必要となるわけではなく、コストパフォーマンスを見据えたコンピューティングリソースの適材適所の再配置が進んでいます。
今回は、NVIDIAと直接競合する大手半導体メーカーを整理しました。
対象は、AMD、インテル、クアルコムの3社です。
2. AMD
NVIDIA が開拓してきたGPU市場におけるの競争相手の筆頭がAMDです。データセンター向けのNVIDIAの競合製品として特に注目すべきAMD製品は、最新モデルのInstinct MI300シリーズです。 AMDではその他、AI処理の強化をうたう「Ryzen AI」に対応するCPU製品がリリースされています。 また、データセンター向けには、データパイプラインのスループットを最大化するDPU(データプロセッシングユニット)やAI処理を高速化する技術をCPUで実現するなど、多様な製品と技術をリリースしています。
(1)Instinct GPUシリーズ
AMDにとってフラッグシップのAIアクセラレーターがInstinct GPUシリーズです。これは、深層学習、機械学習、高性能コンピューティング(HPC)のアプリケーション用に設計された高性能GPUを搭載するのプロダクト群で、大規模データに対する複雑な計算を高速化し、科学計算やAIモデルの学習と推論などのタスクをターゲットとしています。

Instinctには、CDNA3(Compute DNA3)というAIとHPCに最適化された新たなアーキテクチャが採用され、高速な帯域幅を持つ大容量のHBM3メモリを搭載し、浮動小数点演算の高い処理能力によって、高度で高速な並列処理を可能にしています。
MI300シリーズには、GPUアクセラレーターのみで構成されるMI300XとCPUコアとGPUを組み合せたAPU(Accelerate Processing Unit)であるMI300Aの2つのラインナップがあり、両モデルともに2023年12月からOEMメーカー向けに出荷されています。尚、MI300XとMI300Aでは、同じアーキテクチャのGPUを搭載していますが、そのコア数や搭載メモリ量が異なっており、MI300XはGPU処理性能がたかく、MI300AはCPUと統合されていることで、データ処理の効率化が図られている点で各々特徴が異なっています。
またその他、MI300シリーズの下位スペックに、MI200シリーズが存在しています。

(出典)AMDより開示された情報を二次加工
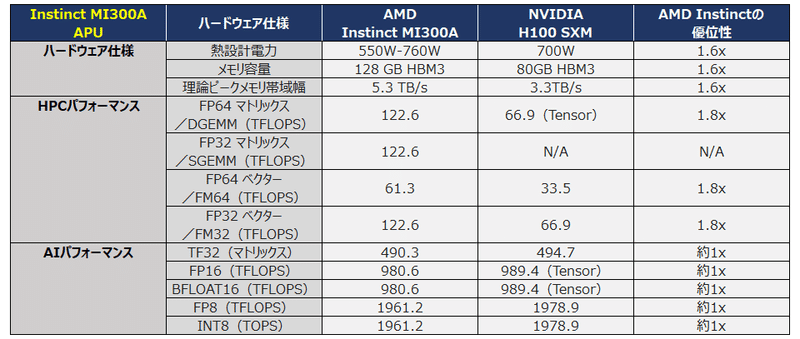
(出典)AMDより開示された情報を二次加工
尚、NVIDIAのH100のメモリ量を遥かに超える大容量のHBM3メモリを搭載したこのAMDのMI300シリーズ(MI300Xは192GB、MI300Aは128GB)は、大容量の大規模言語モデルがすっぽり入り、モデルの学習や推論の取り回しが非常に便利になることから、既に多くのクラウドプロバイダーでの試験導入が進んでおり、マイクロソフト、メタプラットフォームズ、OpenAIも採用を表明しています。
下図は、Meta Platformがオープンソースとして公開している大規模言語モデル「Llama 2」を単一GPUで推論した際のNVIDIA H100とのパフォーマンス比較結果を示す図です。

(2)Ryzen AI対応CPU
APU(Accelerated Processing Unit)製品として、GPU機能を統合したCPU製品をリリースしています。 Ryzen 7040シリーズや同8000番台シリーズが該当しますが、これらは、「Ryzen AI」と称するXDNAアーキテクチャに基づくAIタスクに最適化されたプロセッサで、PCのAI処理能力を向上させ、画像や音声処理などのAIタスクを高速に処理することができるようにした製品です。

(3)EPYC CPUシリーズ
高性能CPU ラインナップであるEPYCシリーズは、高性能コンピューティング(HPC)、クラウドコンピューティング、データセンター向けに設計されたサーバー用のプロセッサです。この製品は、AI専用のアクセラレーターを内蔵していませんが、AIタスクの処理性能を向上させるための機能を提供しています。
EPYC CPUは、最大64コア128スレッドのマルチコア設計となっており、AIや機械学習のような並列処理の求められるタスクを最適に処理することができ、モデルの学習と推論の高速化を図ることができます。また、高帯域幅メモリと大容量キャッシュにより、大量のデータを迅速に処理し、ワークロードのパフォーマンスを向上させることができます。EPYC CPUには、GPUが搭載されていませんが、GPUや他のアクセラレーターと組み合わせることで、高度なAIアプリケーションを高速に実行する環境を実現します。

(4)ROCm(Radeon Open Compute Platform)
ROCm (Radeon Open Compute) は、AMDが開発したNVIDIAのCUDAに対抗するオープンソースのソフトウェア開発プラットフォームで、CPUとGPU間の効率的なデータ共有と計算タスクの配分を可能とします。
顕著な特徴としては、ROCmの提供するHIP(Heterogeneous-compute Interface for Portability)というクロスプラットフォーム機能は、NVIDIAのCUDAと互換性を持ち、CUDAで記述されたコードをAMDのGPU上で実行可能なように変換する機能を持っています。またHIPのAPIは、CUDA APIと非常に似通っているため、NVIDAのCUDAでの開発経験のある開発者がAMDのGPUを使ったアプリケーションを容易に作ることができるほか、同じコードを使ってAMDとNVIDIAの両方のGPUでアプリケーションを動かすことができるようになります。

3. インテル
長年にわたってCPU市場を支配してきたインテルですが、AIアクセラレーター市場においては完全にNVIDIAの後塵を拝しています。これには幾つかの理由があるとされています。NVIDIAがゲームやグラフィックといった特定市場向けに開発してきたGPUのアーキテクチャが、深層学習のモデル学習に非常に有効であることが分かり、この認識が一気に拡がってNVIDIAの1強ともいえる現在の状況を作り出したと言えますが、これは単に結果論に過ぎません。もちろん、NVIDIAが単に幸運だったわけではなく、早い段階でAIの重要性と将来性を認識し、GPU技術の更なる活用のためのCUDA(Compute Unified Device Architecture)に代表されるソフトウェア開発プラットフォームを積極的に開発し、そして、さまざまな業界でのユースケースを他社に先駆けて開発することで、他の大手半導体メーカーが簡単に越えられない高い参入障壁を構築したという背景がそこにあります。
そして、インテルのAIへの取組みが決して遅かった訳でもありませんが、既存のCPUアーキテクチャを踏襲する開発アプローチを採ってしまったことやNVIDIAのcudaに対抗できるような開発エコシステムを十分に構築できなかったことなどがNVIDIAの後塵を拝している理由であるといわれています。
実際、インテルは、高度化するコンピューティング技術に多くの投資を行っており、企業買収や企業出資も積極的に行っています。企業の買収では、ニューロモーフィック技術を開発するNervana社(2016年)、深層学習フレームワークを開発するvertex.ai社(2018年)、現在のインテルの製品「Habana Gaudi2」の原型を開発していたHabana Lab(2019年)。そして、ICE Tech社、SambaNova社、SimpleMachines社、UntetherAI社、Xsight社、NeuroBlade社、Prophesee社、Syntiant社、Motivo社など、多くの企業にも出資を行っています。
そしてインテルは、サーバーやPC、データセンター向けにAIアクセラレーション製品を様々に展開しており、CPUのみでAI処理を行うものから、GPUや専用アクセラレーターを組み合わせた統合製品まで、顧客ニーズに様々に応えるラインナップを強化し続けています。
以下、インテルのAIタスク向け製品を紹介していきます。
(1)データセンター向けGPU製品
「Data Center GPU Max」は、高性能コンピューティング(HPC)およびAIアプリケーション向けのデータセンター向けにラインナップされたGPU製品です。Xe-HPCアーキテクチャにより、大規模な計算処理能力と高度で複雑なデータ計算処理機能を実現し、ディープラーニングや機械学習のアルゴリズムを高速に実行できるよう最適化され、HPCやAIタスクの処理能力を大幅に向上させています。また、2.5次元パッケージング技術の「EMIB(embedded multi-die interconnect bridge)」と3次元パッケージング技術の「Foveros」によって、複数チップを高密度に統合してデータ転送速度を高めていたり、大容量で高速なHBM(High Bandwidth Memory)を搭載し、大規模データへの高速アクセスを可能としており、科学計算や気象モデリング、金融工学やAIのモデル学習など、膨大な計算量が必要となるアプリケーションをターゲットとしています。

(2)Habana Gaudi/Gaudi2
インテルが2019年に買収したHabana Labs社は、インテルのデータセンター向けのポートフォリオを拡張するための戦略子会社として、インテルブランドのAIアクセラレーター製品をリリースしています。 それがインテルHabana Gaudi2とGaudiです。
2022年に発表されたGaudi2は、2019年に発表されたGaudiの次世代製品で、深層学習に特化したアクセラレーターとCPUを組み合わせたAIモデルの学習と推論のための製品です。先代のGaudiに比べ、Tensorコアの数が2.5倍、メモリ帯域幅が3倍に増加し、処理能力が倍以上に向上し、スケーラブルに拡張可能なアーキテクチャによって大規模な言語モデルや画像認識モデルなどの学習と推論に適した製品です。
Gaudi2は、NVIDIAのH100ではオーバースペックとなるが、一定の性能が求められるニーズに向けて、特にクラウドサービスプロバイダーでの採用例が増加している模様で、2024年後半には、次期モデルとなるGaudi3の発表が予定されているようです。
またHabana Labs社は、SynapseAIと称するAIモデルの開発・学習・推論を支援するデータエンジニアおよびデータサイエンティスト向けのクラウドサービスを提供しています。 これは、データエンジニアやデータサイエンティストがAIのモデル開発プロセス(データ準備、モデル生成、モデル学習、モデル実装、モデル管理)の各種タスクをノーコード/ローコードで実現できるクラウド環境をサービスとして提供するものです。

(3)ソフトウェア開発環境
インテルは、「oneAPI」というソフトウェア開発プラットフォームをリリースしています。このソフトウェア群は、インテルのCPU、GPU、FPGAなどの異なるハードウェアで動作させるアプリケーションの開発を移植性高く、効率的に行えるツールやライブラリを提供しており、気候変動予測やマテリアルインフォマティクス、画像認識や音声認識などのAI処理、高度なグラフィックスとリアルタイム処理を伴うゲームなどの開発を促進します。このoneAPIは、以下の要素で構成されています。
oneAPIベースツールキット
CPU、GPU、FPGA向けの共通のプログラミングモデルとツールを提供
oneAPI HPCツールキット
高度な計算科学アプリケーション開発向けのツールを提供
oneAPI レンダリングツールキット
高度なグラフィックスアプリケーション開発向けのツールを提供
AI開発ツール
AIモデルの開発、トレーニング、デプロイ向けのツールを提供
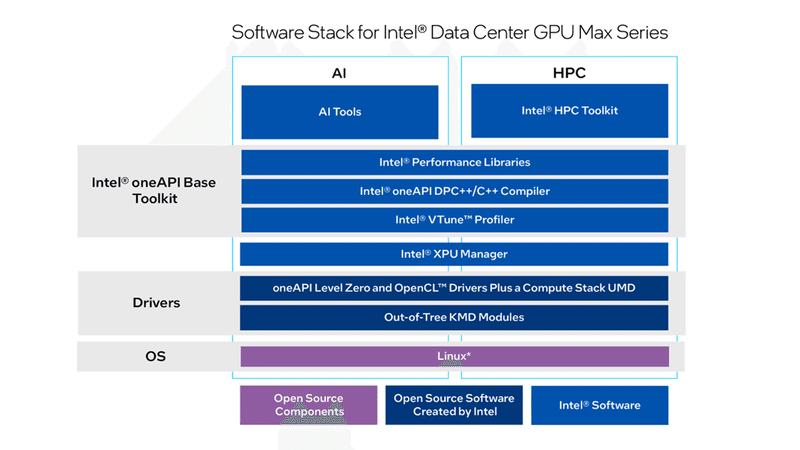
上図は、「oneAPI」のソフトウェアのイメージ図です。 OSレイヤーに基盤となるLinux OSがあり、ハードウェアとソフトウェアをつなぐDriversレイヤーにoneAPI Level Zero および OpenCL Drivers Plus a Compute Stack UMD(User Mode Driver)とOut-of-Tree KMD(Kernel Mode Driver)モジュールが配置されています。その上に配置されているのが「oneAPI Base Toolkit」で、ライブラリやコンパイラ、そしてプロファイラによって構成されています。そして一番上に、AIとHPCのためのツールキットがあり、AIやHPC上の特定アプリケーションを開発するための高度なツールとライブラリが提供されています。
(4)サーバー用Xeonシリーズ
最新の第5世代Xeonシリーズは、CPUのみでAIタスクを処理するシリーズですが、その高性能な計算能力は、データセンターでの利用をターゲットとした製品です。この「Xeonスケーラブル・プロセッサー」は、構成するコアの全てにAIアクセラレーション機能を搭載し、ベクトルニューラルネットワーク命令(VNNI)を使用して、畳み込み演算やプーリング演算などを伴う画像認識や音声処理におけるAI推論性能を向上させる「DL Boost」、データの大量処理能力を向上させる高度なベクトル拡張命令セット「AVX-512」のサポート、そして、オンチップメモリとキャッシュの最適化などの技術に支えられ、AIモデルの学習と推論を高速に処理できます。

(5)AI機能を強化したPC用のCPU
パソコン用のCoreシリーズも、CPUのみでAIタスクを強化しています。前述のXeonスケーラブル・プロセッサーにも採用され、深層学習で頻繁に使用される演算を高速化するDL Boost技術を2019年発表のIce Lake以降のCore製品から採用し続けています。また、バッテリー駆動デバイスにおいて、低消費電力での音声処理やノイズ抑制などのタスクを高速実行するGNA(Gaussian & Neural Accelerator)や自動画像補正やオブジェクト認識などのAIタスクを高速化する「インテル Iris Xe Graphics」を搭載するなど、エンドユーザーコンピューティング環境でのAI処理に応える製品をラインナップしています。
(6)その他の製品
インテルでは、上記に紹介した製品以外の複数のプロジェクトが存在しています。
① Nervana ニューラル・ネットワーク・プロセッサー
Nervana ニューラル・ネットワーク・プロセッサー(NNP)は、深層学習とAIアプリケーションに特化して設計されたPCI ExpressをインタフェースとするASICで、データセンターやエッジ環境での高度なAIモデルの学習と推論の効率を大幅に向上させることを目的とした製品です。2023年11月現在の最新バージョンはNNP-T1000で、複雑な深層学習モデルを高速処理するために最適化され、大規模なデータセットを対象とする学習と推論をエネルギー消費を抑えて効率的に行うことができます。
Nervana NNPは、画像認識や音声認識、自然言語処理や様々な推論を高速に処理し、医療や金融、自動運転やソーシャルメディア分析など、様々な用途に適した製品となっています。 尚、後続で開発されている上述のGaudi2とは、価格と利活用シーンへの適合性によって異なる顧客ニーズに対応するオプションとなっている模様です。

② Movidius ビジョン・プロセッシング・ユニット
インテルが2016年に買収したMovidius社の技術をベースに開発したコンピュータービジョンとディープニューラルネットワーク推論アプリケーションに特化したVPU(Vision Processing Unit)で、Movidius Myriad X VPUが最新モデルとなっています。ディープニューラルネットワーク推論専用のハードウェアアクセラレーターを搭載し、1秒間に4兆回以上の演算処理能力を実現。16個の強力なSHAVEコアによって、画像処理やコンピュータービジョンのタスクを高速処理します。さまざまな画像フォーマットに対応し、最大4Kの動画解像度でハードウェアエンコードが可能。また、低消費電力で、モバイルデバイスやIoTデバイスに最適なハードウェアであり、クラウドに依存することなく、スマートカメラやドローン、スマートホームや産業用機器に搭載しての画像処理系タスクを実現します。尚、Myriad 2という製品は、更にエネルギー効率に優れたビジョン・プロセッシング・ユニットです。

4. クアルコム
1990年代にCDMAという通信技術を開発し、4G/5Gなどの無線通信技術の基礎技術と特許を多数保有し、スマホやIoTデバイス等に組み込まれるモバイルプロセッサやモデムの設計と製造で知られる会社です。「Snapdragon」というブランドを冠したモバイルSoCが良く知られています。
このクアルコムもAIタスクを高速化するための技術を積極的に開発しています。特に、スマホなどのバッテリー稼働のデバイスで、AIタスクを高速かつ省電力で実現するための技術の開発に強みを持っています。以下は、「Snapdragon」シリーズに組み込まれるAIアクセラレーター技術です。
(1)Snapdragon AIアクセラレーター
クアルコムは、スマホなどに組み込まれているSoC「Snapdragon」にAIアクセラレーター技術を組み込み、エッジデバイスでのAI処理能力を高めています。Snapdragonプラットフォームに組み込まれるAIアクセラレーターは、以下のように多岐に及びますが、これらは各々、専用のハードウェアとソフトウェアから構成されます。スマホのようなデバイス側でAIタスクを処理することには、プライバシー保護やネットワーク不在でもスタンドアロンで実行可能であったり、処理遅延を最小化できるなどの多くの恩恵を受けることができます。

① Snapdragon Neural Processing Engine
AIの推論向けアクセラレーターで、現在のエンジンは7世代目となる。 このNPEを搭載したSnapdragon 8 Gen 2では、最大4.35 TOPS(INT8)の処理能力を発揮し、現時点で最も高性能なモバイル AI 推論アクセラレーターの1つとなります。
TensorFlow、PyTorch、Caffe2などの主要なフレームワークをサポートし、画像・動画処理、音声処理、AR/VR/XR、自然言語処理等のアプリケーションを低消費電力で実現します。
※TOPS(1 秒間に実行できる 8 ビット整数演算の回数)
② Hexagon Tensor Processor
AIタスクの推論用アクセラレーターで、従来のCPUやGPUと比べて、低い電力消費で高い処理能力を発揮し、スマートフォンやタブレットなどのモバイルデバイス上で、高度なAI処理を可能にします。
特徴としては、テンソル演算に最適化され、電力効率に優れたアーキテクチャを持ち、TensorFlow LiteやPyTorch Mobile、Caffe2などのフレームワークに対応し、画像認識や音声認識、自然言語処理やその他の幅広い機械学習タスクを高いスループットで処理することが可能なことです。
③ Adreno GPU
リアルタイムや高精度な3Dグラフィックスの処理が可能で、AIタスクにも対応するモバイルGPUです。省電力性能に優れた設計によりバッテリー駆動のデバイスでも高速に動作することが可能です。主に画像処理を担い、3DゲームやAR/VR/MR、3Dグラフィックス、動画処理など、高度なビジュアル体験を必要とするアプリケーションで利用されます。
④ Hexagon DSP
機械学習の推論タスクに最適化されたベクトルプロセッサです。高度なデジタル信号処理(DSP)と機械学習タスクの処理能力を持ち、バッテリー駆動デバイス上で、様々なタスクを高速かつ効率的に実行します。Hexagon NN LibraryやSnapdragon Neural Processing Engine SDKなどのソフトウェアライブラリにより、画像処理や音声処理、センサー処理や機械学習など、様々な用途に活用することができます
(2)Cloud AI 100アクセラレーター
そしてクアルコムが取り組むAIアクセラレーション製品のもう一つのラインナップが、ASICを搭載したデータセンター向けの「Cloud AI 100アクセラレーター」です。サーバー向けの推論タスク用ASICを搭載し、75Wという低い消費電力で、INT8で最大400TOPS、FP16で最大200テラフロップス(TFLOPS)の機械学習処理が可能な高いパフォーマンスを発揮する高い省エネルギー性能を兼ね備えた低プロファイルアクセラレータです。自然言語処理やコンピュータービジョン、自動走行など、多岐にわたってサポートし、既に、AWSのクラウドサービスでは、「EC2 DL2qインスタンス」として、一般利用が可能となっています。また、HPEやレノボがサーバーに搭載して販売するなど、マーケットへの浸透が進んでいることが伺えます。

御礼
最後までお読み頂きまして誠に有難うございます。
今回は、主要な半導体メーカーの現状を紹介しましたが、細分化の進む市場動向については、別途続編として記事掲載を予定しています。
ご興味ありましたら、ぜひともフォローをお願いいたします。
今後ともどうぞよろしくお願いいたします。
だうじょん
免責事項
本執筆内容は、執筆者個人の備忘録を情報提供のみを目的として公開するものであり、いかなる金融商品や個別株への投資勧誘や投資手法を推奨するものではありません。また、本執筆によって提供される情報は、個々の読者の方々にとって適切であるとは限らず、またその真実性、完全性、正確性、いかなる特定の目的への適時性について保証されるものではありません。 投資を行う際は、株式への投資は大きなリスクを伴うものであることをご認識の上、読者の皆様ご自身の判断と責任で投資なされるようお願い申し上げます。
この記事が気に入ったらサポートをしてみませんか?