
【インタラクション2024に参加】EarHover:ヒアラブルデバイスにおける音漏れ信号を用いた空中ジェスチャ認識

はじめに
こんにちは、杉浦裕太研究室B4の鈴木です。
3/6-8の3日間、学術総合センター内一橋記念講堂で開催された第28回 一般社団法人情報処理学会シンポジウムINTERACTION2024に参加し,「EarHover:ヒアラブルデバイスにおける音漏れ信号を用いた空中ジェスチャ認識」というタイトルで登壇発表を行いましたので、報告させていただきます。
研究の概要
近年の技術発展に伴い,イヤホン型のウェアラブル端末であるヒアラブルデバイスが注目を集めています.ヒアラブルデバイスの操作は,スマートフォンから間接的に操作する方法と,ヒアラブル本体に直接触れて操作する方法の2 種類があります.スマートフォンによる操作は,画面を見ながら操作す
る必要があり,ユーザビリティが低下します.そのため,デバイス本体のみで操作が完結するのが理想的です.しかし市販のヒアラブルデバイスに搭載されている物理ボタンなどは手で直接触れる必要があり,手が汚れている場合や手を清潔に保ちたい場合には利用が困難です.
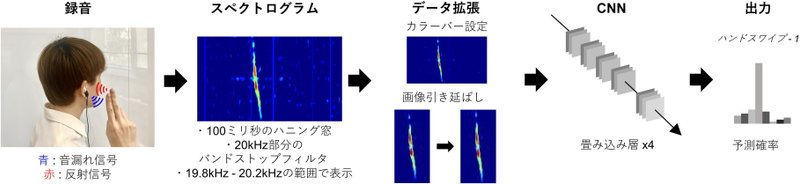
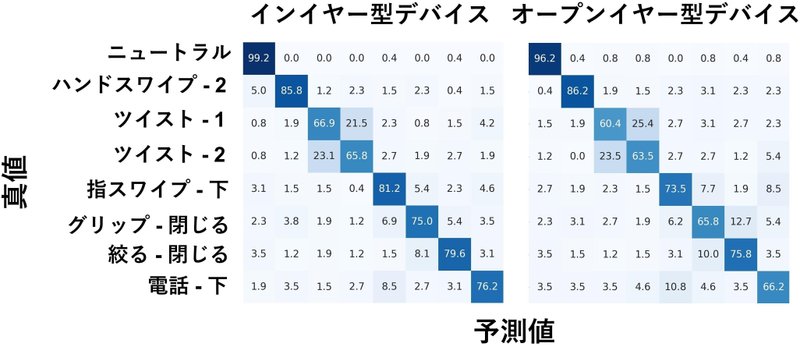
本研究では,ヒアラブルデバイスへの空中ジェスチャ入力を可能にする新しいジェスチャ認識手法“EarHover” を提案します.本手法は,ヒアラブルデバイス特有の音漏れ現象に着目します.本研究では,有効な27 種類のジェスチャの中から,信号の識別性とユーザの受容性の観点から,7 種類のジェスチャを選択しました.その後,これらの7 種類のジェスチャとニュートラル状態の計8 状態のデータをインイヤー型/オーバーイヤー型の2 つのプロトタイプデバイスを用いて収集し,深層学習による認識性能の評価を行いました.実験の結果,インイヤー型/オーバーイヤー型デバイスのそれぞれのF-score は78.7%/73.4%でした.さらに,5 種類のジェスチャに絞ることで,F-score は6 状態で86.2%/82.5% でした.
当日のフィードバック
当日は主に実験設定に関する質問・意見を頂きました.また,リアルタイムジェスチャ分類の実装や,システム内のジェスチャ分類指標の提案など,今後検討していきたい内容についてのフィードバックも頂きました.
感想
初めての登壇発表で大変緊張しましたが,無事トラブルなく発表を終えることができました.ポスター発表とは異なり,自分の研究を詳細にお伝えすることができ,より多くの方からフィードバックを得られました.この経験を活かし,更なる研究の発展に向け努力していきたいと感じました.
発表文献情報
鈴木俊汰、雨坂宇宙、渡邉拓貴、志築文太郎、杉浦裕太、EarHover:ヒアラブルデバイスにおける音漏れ信号を用いた空中ジェスチャ認識、インタラクション2024、一橋大学、東京.
発表スライド
発表動画
この記事が気に入ったらサポートをしてみませんか?