
人工知能は人間を超えた?GPTが掴んだ世界の本質

GPTブームが爆発してから一念が過ぎ、私のある考えが安定してきました。この記事では、現在の局面を整理していきましょう。
新しいものへの興奮
新しいものに対して、最初からそれがすごいと感じ、いたるところでその凄さを宣伝することは、少しリスクがある行為です。なぜなら、すぐに流行が去り、事実が最初の想像ほどすごくなかったと証明されてしまうと、自分が当時馬鹿だったと感じるかもしれないからです。
しかし、私はこれが正しいと思います。新しいものを見た瞬間にすごく興奮することは、まさにあなたの心がまだ躍動していることを証明しており、認知の硬直化に陥っていないことを示しています。これは、どんなものを見ても自分の古い世界観で解釈し、30年前に理解したものだと言い張るより、ずっと強いものです。自分を成長させ続けるためには、人に馬鹿だと言われるリスクを恐れないことです。
GPT-4 の革新性
GPTは30年前の概念で理解することはできません。近年のいくつかのキーブレークスルーが、ニューラルネットワークと言語モデル研究の様子を根本的に変えました。
私見では、2021年以前に出版されたAIについての全ての本は、もう時代遅れです。
AIと人間の脳の差異
AIと人間の脳には本質的な違いはあるのでしょうか?言語モデルとはいったい何なのでしょうか?
オバマ氏と彼の同僚数人が廊下にいる写真を見てみましょう。写真には、体重計に乗って体重を量っている人がいて、その人が知らないのは、オバマ氏が後ろにいて、彼の体重計に足を乗せ、少し重さをプラスしているということです。周りの人はみんな笑っています。

コンピュータビジョンの専門家、アンドレイ・カルパチ(Andrej Karpathy)は、2012年10月のブログ記事でこの写真を使用しました。当時彼の主張は、AIにこの写真を理解させることは非常に非常に困難だというものでした。
AIがこのシーンの面白さを理解するためには、いくつかの「常識」を持っている必要があります。体重計が何に使うのか、体重計にもう一つ足を乗せると読み取りが増えること、オバマ氏がいたずらをしていること、現代人は体重が増えることを怖れること、そして大統領としてオバマ氏がこのような冗談を言うことは面白いことなどです。これらの常識は、どの本にもシステマティックに列挙されているわけではなく、私たちが知っているけれども意識していないものです、これが「暗黙の知識(tacit knowledge)」です。
AIにこれら暗黙の常識をどのように教えればいいのでしょうか?
コンピュータサイエンスの研究者メラニー・ミッチェル(Melanie Mitchell)です。彼女はダグラス・ホフスタッターの教え子で、私が進化アルゴリズムを初めて学んだのは彼女の本でした。ミッチェルは2019年に「AI 3.0」という本を出版し、AIに常識を教える難しさについて多くの例を交えて説明しています……。
確かに難しかったです。人間の全ての常識を一つずつ書き下ろしてプログラムにコード化させ、AIに学ばせることは、決して完了しない作業だったのです。そうではないですか?
したがって、そのような困難な仕事については皆が嘆いていたのです。
……しかしそれらの嘆きも、今はすでに古いものとなっています。
GPT-4 は暗黙の知識を理解できるか?
GPT-4はその写真を理解しています。
GPT-4がリリースされたその日、OpenAIのマニュアルには例がありました。画像の中で、元々は古いモニターに接続されていたVGAプラグが携帯電話に差し込まれており、これが一種のアンマッチングなユーモアだった……。

そしてGPT-4はそれを理解し、どこがおかしいのかを端的に説明しました。

すぐにカルパチのオバマ氏と体重計の写真を思い出した人がいて、TwitterでカルパチにGPT-4で試してみてはどうかと尋ねました。彼はすぐに返事をして、もうテストした、理解している、そして解説していると言いました。
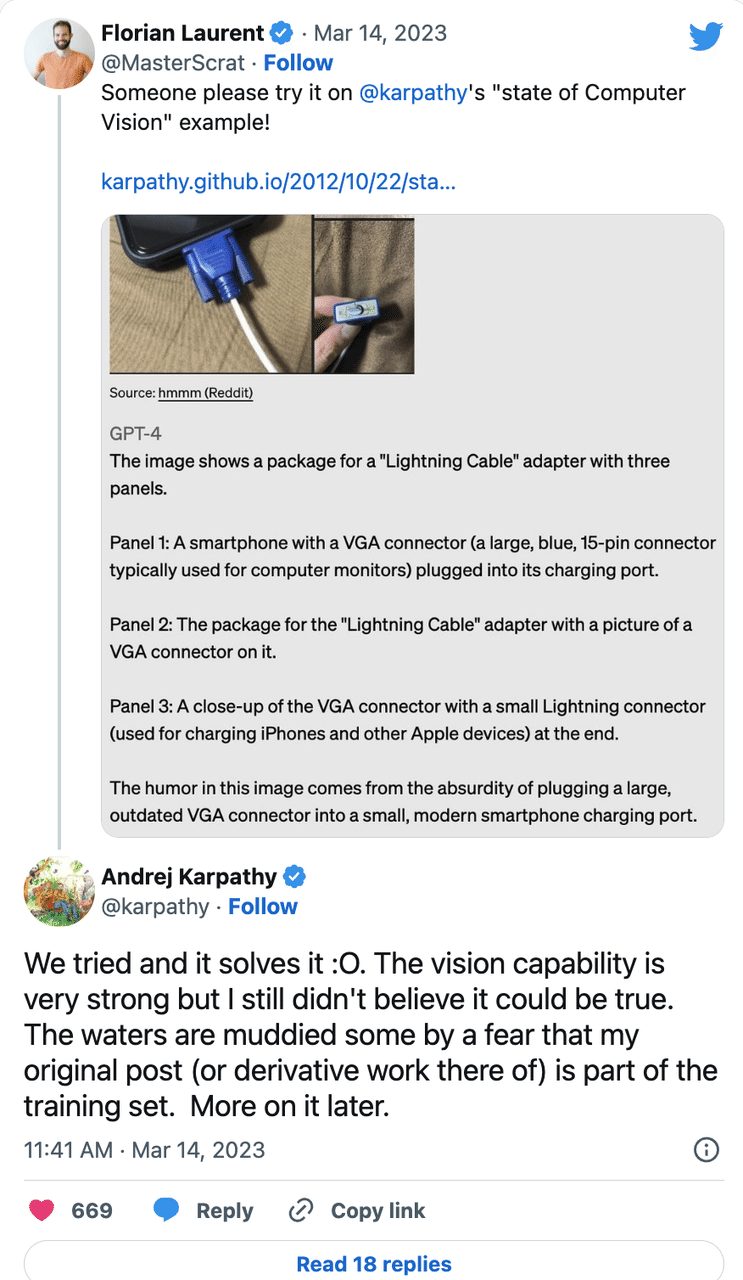
カルパチが心配していたのは、OpenAIがその写真でGPTを訓練した可能性です……しかし、私はそれは無用の心配だと思います。あらゆるパフォーマンスから見て、GPT-4はこのような画像を理解する能力を完全に備えているのです。
今これに驚くべきではありません。前に言ったように、私はChatGPTに野球のバットを人の耳に入れることができるか、なぜ孫悟空の如意棒を耳に入れることができるのかを尋ねました。答えは上手で、彼は常識を持っていました。
しかし、それをどのように理解したのでしょうか?このAIはどのようにして人間の常識を学んだのでしょうか?
GPT-4 は世界の投影
2023年3月、エンビディアのCEO、ジェンスン・フアンとOpenAIの主席科学者イリヤ・スツケバー(Ilya Sutskever)との対談が行われました。この対談で、スツケバーはGPTが何であるかについてさらに説明しました。

スツケバーいわく、GPTはただのニューラルネットワーク言語モデルであり、次の単語が何かを予測するためだけに訓練されたのです。しかし、十分に訓練された場合、様々な統計関連性をうまく把握することができます。そしてこれは、つまり神経ネットワークが本当に学習したのは、「世界の投影(a projection of the world)」なのです。
神経ネットワークが学習したのは、ますます多くの世界と人々、人間の境遇のすべての側面です。それには、彼らの希望、夢、動機、および人々の相互作用と私たちが置かれているさまざまな状況を含みます。神経ネットワークはこれらの情報について、圧縮、抽象化、そして実用的な表現を学びました。これが正確に次の単語の予測を通じて学んだ内容です。そして、次に来る単語の予測がより高精度であればあるほど、そのプロセスの忠実性と解像度も高くなる。
言い換えれば、GPTが学んでいるのは言語というよりも、言語の裏にある実世界です!
たとえを1つ挙げます。禅宗には「指月録」という本があります。それは昔の六祖慧能の一つの話から使われています。慧能は真理は月のようなもので、経典のようなテキストは月を指す手指のようなものです。あなたは手指をたどって月を見つけることができますが、求めるべきは手指ではなく月です。現在、GPTを訓練するために使われた言語コーパスは手指ですが、GPTは月を掴んでいます。
これがGPTが常識を持っている理由です。それは自分で無数の言語コーパスから掴み取ったものです。
文章だけを読んで月を掴み取ることができるのでしょうか?おそらくはそうです、あるいは少なくともある程度は可能です。そうでなければどうでしょう?私たち人間も読書を通じて同じように学んでいるのではないですか?
GPT-4 の進化
もっと悟りが必要かもしれませんし、ただもっと読む必要があるだけかもしれません。
多ければ多いほど、違います。量が質に変わり、「創発」につながります。
OpenAIの社長グレッグ・ブロックマン(Greg Brockman)が4月のTEDでの講演で述べたように、最初のキーブレイクスルーは2017年に起こりました。その時、OpenAIのエンジニアがアマゾンの商品レビューを使って簡単な言語モデルを訓練していて、そのモデルは明らかに構文を分析しているはずが、自動的に意味論の感覚を得て、レビューが好意的か否かを見分けたり設定したりできるようになりました。
そしてGPTはTransformerアーキテクチャを採用しました。
そして、2021年前後にGPTは「悟」と「創作」を達成し、自動的に「少サンプル学習」能力を持ち始め、推論能力を得て、思考連鎖を発達させました。
更に興味深い特徴があります。ChatGPTと対話して、英語で質問するか日本語で質問するか、チャット問題が直接日本の文化や歴史に関連していない限り、応答の品質はほぼ同じです。もちろん日本のことを尋ねる場合は、日本語で尋ねる方が良いですが、それはおそらく正確に表現されるからです。しかし、一般的な問題、たとえば科学問題に関しては、どの言語で尋ねてもGPTにとってはほとんど違いがありません。これはなぜでしょうか?
最初は、GPTはまず日本語を英語に翻訳し、それから英語で考え、そして日本語に翻訳して答えを返すと思っていました。しかしだんだんと、そうではないように感じてきました。GPTには特別な翻訳ステップがありません。入力されたプロンプトの言語に関係なく、同じ神経ネットワークの同じ場所から直接処理が行われ、言語は単なる表現界面にすぎません。
これは、私のほとんどの物理の専門知識が英語で学んだけれども、物理学の問題を尋ねられたときに、使用する言語に特に差はありません。物理を考える時、私は論文を誦むことはせず、直接考えるのです。
つまり、GPTという言語モデルは言語の背後にあるものをつかんでいるということです。
3月のポッドキャストインタビューで、スツケバーはその例を挙げました。多様な機能がなくても、GPTはテキストから学習するだけで色について十分な理解を持っています。それは、紫が青に近く、赤には遠いこと、橙色が紫よりも赤に近いことを知っています。
それは色々なテキストでそれらの色を読んでいたから記憶しているわけではなく、代わりに運ばれてきた世界を覚えています。それは静かに色の相関関係を把握していったのです。
GPTは単なる教科書を暗記しているわけではなく、指を通して月を感じているのです。
これは数ヶ月前には予想もしなかったことで、世界観のレベルでの変化です。
AIは文字通りだけでなく、世界の常識を理解しました。はい、言語は実際の世界を不完全に表現したものであり、多くの内容は表面的には言い表されていません。しかし、言語を通じてだけで、神経ネットワークは背後にあるものを捉えることができます。
説明ができ、推理ができ、画像のジョークを理解し、記事を書いたりプログラミングするします。これが理解と呼べないのであれば、何が理解と言えるでしょうか?
事態は「AIと人脳に本質的な違いがない、言語モデルは実際の世界そのものの投影である」という方向へ進んでいます。
GPTが文法分析から自発的に意味を生み出すことは、AGIへの最も重要な一歩です。これは21世紀に入ってからの人類にとって最も重要な発見かもしれません。もしAGIが生命を持つものと認められるならば、ノーベル生理学または医学賞を授与する価値があるのではないでしょうか。
精確で使いやすく、より良い価値観を持つ
総当たり攻撃が言語モデルをこれほど強力にしたとしても、次のステップは何でしょうか?それは、その構造をよりスマートにすることと、さらに重要なことですが、AIの「飼いならし」です。
ジェン・スン・フアンとの対談で、スツケバーはOpenAIが現在取り組んでいる事柄について話しました。GPTはもう世界をよく理解していて、多くのことを知っていますが、戦略的な表現を学ぶ必要があります。
知識豊かな賢人でも、聞かれたものに対して何でも答えてしまうわけにはいきません。OpenAIはGPTが何でも話すことを望んでいません。彼らはGPTが人々が受け入れやすい言葉で話すことを習得する必要があるのです。これは、例えば政治的な正しさや容易に理解し、人々により役立つような言葉であるということです。GPTはもう少し主観的になる必要があり、望ましい主流の価値観に沿った方法で月を描写するのが良いでしょう。
そしてこれは、準備された教材でのトレーニングだけでは解決できない問題です。それには「ファインチューニング(fine-tune)」や「強化学習」が必要です。スツケバーによると、OpenAIは2つの方法を使用していて、1つは人がフィードバックを与えること、もう1つは別のAIがそれを訓練することです。
彼が言及しているのは、現在活発に議論されているいわゆる「AIアライメント問題(AI alignment problem)」です。つまり、AIの目標と価値観が主流社会に合致するようにします。前に述べたように、いまや各企業が価値観に言及し、「alignment」は流行語となりました。
AI開発の風向きは変わっています。
2023年の4月初め、OpenAIのCEOサム・アルトマン(Sam Altman)がMITで報告したところによると、OpenAIはもうGPTにパラメーターを追加することに焦点を当てていません。これは、モデルのサイズを拡大するコスト効果がますます減少していると彼が見積もっているからです。
言い換えれば、「限界効用逓減」です。このGPT-4の規模に達した時点で、モデルのパラメーター数をさらに10倍に増やしても、訓練コストを含む様々な支出は10倍以上かかる可能性があるのに対し、モデルの性能は10倍向上するわけではありません。そして、GPUの台数、データセンターの規模、消費電力といった物理的な制限にもぶつかります。
したがって、アルトマンは、現在の研究の方向性はモデルのアーキテクチャを改善することであり、例えばトランスフォーマーにはまだ改善の余地がたくさんあると述べています。
アルトマンはまた、OpenAIがGPT-5を訓練しているわけではなく、現在主な仕事はGPT-4をより使いやすくすることにあると指摘しています。これは以前からのOpenAIの示唆にも合致しています。つまり、AIが少しゆっくり進化することで、人類が適応できるようにするのです。
したがって、大規模モデルの暴力破解段階はひとまず一区切りつけられるでしょう。現在のAIはすでに相当な程度の知性を持っており、近い将来の主要な課題はさらなる知能の向上ではなく、より精確で使い勝手が良く、より社会が受け入れやすくすることです。
これらは全て良いことのように聞こえます。しかし私の知る限り、何らかの数学的な理由から、OpenAIが完全にGPTを「コントロールする」ことは不可能と思われます。また次回お話ししましょう。
この記事が気に入ったらサポートをしてみませんか?