
在宅ワークの多い兼業主婦が、時系列解析でCovid-19の次の波を予測してみた

はじめに
はじめまして。
新たなチャレンジをしてみたくなり、Pythonでデータ分析を始めました。
2022年1月末ごろからAidemyで勉強を始めて早3か月・・・
まだまだ突っ込みどころも満載ですが、超初心者のはじめの一歩を温かく
見守ってください。
自己紹介
港町に住むアラフィフ兼業主婦
子育てプロジェクトも、そろそろ終わりが見えてきたところ・・
子どもは、大学生と高校生 男子2人
消費財のマーケティングのお仕事を経て、大学の実務家教員へ
「研究者」になるべく勉強中
専門分野は「キャリア」「インターナル・マーケティング」
経営学修士・人材育成・経営コンサルティングのお仕事も
データ分析の目的
感染者が増加しそうな時期を予測し、それに備えて事前に
業務スケジュールを立てておきたいと思いました。
この2年くらい、我々の生活に大きな影響を及ぼしたコロナ・ウィルス。
大学の授業はオンライン配信となり、その準備に四苦八苦しました。
学生へのアナウンスも直前になりがちで、いろいろな確認作業や
授業準備に追われる毎日。学生にも、かなりの負担をかけてしまいました。
今回の分析は、感染者増加の時期を予測することによって、
1)またオンライン授業になってしまった時の混乱を最小限に抑える
2)学生に感染者増加の前から、更なる注意喚起を促す
ことが目的です。
もちろん、またオンライン授業にならないことを心底祈っていますが・・・
分析実行環境
Google Colaboratory
データ分析のステップ
以下のステップでデータ分析を試みました。
1.問題の定義
2. データの取得
3. データのクレンジング
4. パターンの分析
5. モデル化、予測
6. データの視覚化
7. 結果・まとめ
1.問題の定義
在住してる都市のコロナ感染者が、どのタイミングでどのくらい増えるか?
(全く専門外かつ超初心者の私が自治体の公開してくれているデータを使って、分析してみると・・・どのくらいの精度を出せるのか?という実験です。実際とは違うことを前提にご覧ください。
ご容赦くださいませ_(._.)_)
2.データの取得
自治体のオープンデータを検索し、取得しました。
「感染者数(日別)」が記載されているcsvファイルをダウンロード
https://www.city.kobe.lg.jp/documents/32576/kansensya.csv
使用データの期間:2020年2月14日~2022年4月19日まで
3.データのクレンジング
(分析データの下処理)
1) データ分析にあたって、必要なモジュールをインポート
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
import itertools
import numpy as np
import datetime
import warnings2)分析データをグーグルドライブに保存し、
Google Colabolatoryに読み込み
from google.colab import drive
drive.mount('/content/drive')
#データの読み込み
df= pd.read_csv('drive/My Drive/DATA/kansensya.csv' , encoding="shift-jis")
pandasのライブラリを使用して、csvファイルの読み込みました。
データを読み込む際、最初にグーグルドライブにデータ保存をし、マウントをしないと読み込みが出来ませんでした(1・2行目)
また、encodingを”shift-jis”と指定しないと、1行目が日本語表記のために、エラー表示になってしまいました。
encoding=”utf-8”の場合もあるようです。
元のcsvデータは下記のようなもの
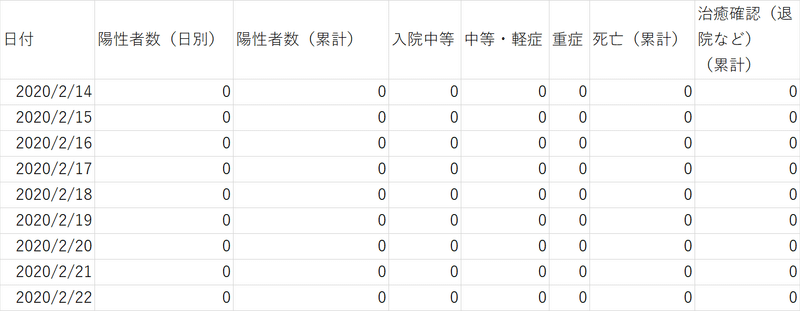
3)データ分析できる形にしていく
#必要ない列を削除
del df["日付"]
# 日付のindexを付ける
index = pd.date_range("2020-2-14", "2022-4-19" ,freq = "D")
df.index = index
#陽性者数の列の名前を変えて抽出
df = df.rename(columns={'陽性者数(日別)': 'number_of_infected_people_per_day'})
df = df.iloc[:,0]
print(df)日別の陽性者数のみをデータ分析の対象として、データ分析しやすいように列の名前を変え、抽出しています。
結果、dfはこんな感じになりました。
欠損データがなかったので、下処理はこれでおしまいです。
2020-02-14 0
2020-02-15 0
2020-02-16 0
2020-02-17 0
2020-02-18 0
...
2022-04-15 579
2022-04-16 357
2022-04-17 141
2022-04-18 587
2022-04-19 17
Freq: D, Name: number_of_infected_people_per_day, Length: 796, dtype: int64
いざ、分析フェーズ!
その前に、今のデータがどんな感じなのか
感染者数の推移を可視化してみました。
グラフにするとイメージがつかみやすいです。
結果は、もう少し丁寧なグラフにしたいと思います。
plt.figure(figsize=(16,9))
plt.plot(df)
plt.show()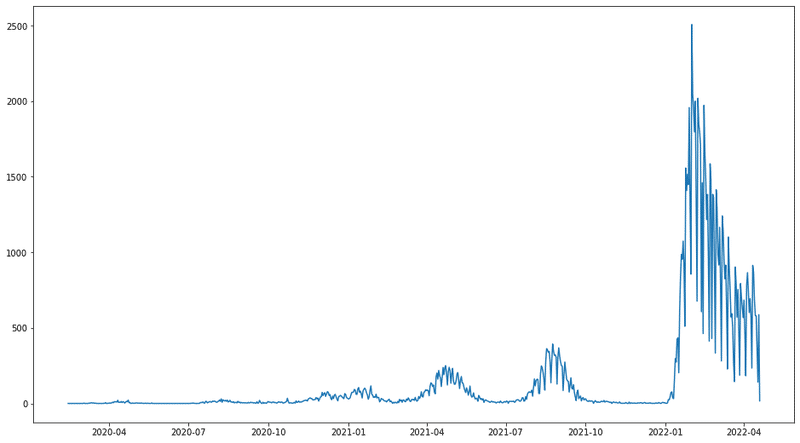
4. パターンの分析
orderの最適化関数
PythonにはSARIMAモデルのパラメーター、(p, d, q) (sp, sd, sq, s)を自動で最も適切にしてくれる機能はありません。
そのため 情報量規準 (今回の場合は BIC)によってどの値が最も適切なのか調べるプログラムを書かなければなりません。
以下のコードで時系列データ:DATA, パラメータs(周期):sを入力すると、最も良いパラメーターとそのBIC計算してくれます。
#orderの最適化関数
def selectparameter(DATA, s):
p = d = q = range (0,2)
pdq=list(itertools.product(p,d,q))
seasonal_pdq =[(x[0], x[1], x[2], s) for x in list(itertools.product(p,d,q))]
parameters =[]
BICs = np.array([])
for param in pdq:
for param_seasonal in seasonal_pdq:
try:
mod = sm.tsa.statespace.SARIMAX(DATA, order=param, seasonal_order=param_seasonal)
results = mod.fit()
parameters.append([param, param_seasonal, results.bic])
BICs = np.append(BICs, results.bic)
except:
continue
return parameters[np.argmin(BICs)]
周期のパラメーターを検証するために自己相関・偏自己相関を出しました。
# 自己相関・偏自己相関の可視化
fig=plt.figure(figsize=(16, 8))
# 自己相関係数のグラフを出力します
ax1 = fig.add_subplot(211)
fig = sm.graphics.tsa.plot_acf(df, lags=150, ax=ax1)
# 偏自己相関係数のグラフを出力します
ax2 = fig.add_subplot(212)
fig = sm.graphics.tsa.plot_pacf(df, lags=150, ax=ax2)
plt.show()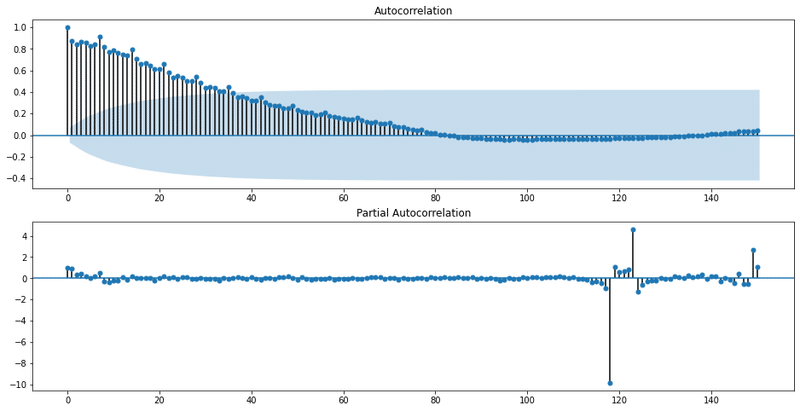
5. モデル化、予測
今回のデータは時系列データなので、
SARIMAモデルを用いて時系列解析をしていきます。
SARIMAモデルは、ARIMAモデルをさらに季節周期を持つ時系列データにも拡張できるようにしたモデルです。
周期を60日と仮定しモデル構築をしました。
best_params = selectparameter(df, 60)
SARIMA_df = sm.tsa.statespace.SARIMAX(df, order=best_params[0],
seasonal_order=best_params[1],
enforce_stationarity=False, enforce_invertibility=False).fit()
print(SARIMA_df.summary())モデルのサマリを出してみました。
AIC, BICが大きく、あまりいいモデルとは言えないかもしれません。
Statespace Model Results
=============================================================================================
Dep. Variable: number_of_infected_people_per_day No. Observations: 796
Model: SARIMAX(0, 1, 1)x(1, 1, 1, 60) Log Likelihood -4378.665
Date: Thu, 21 Apr 2022 AIC 8765.330
Time: 15:27:17 BIC 8783.377
Sample: 02-14-2020 HQIC 8772.319
- 04-19-2022
Covariance Type: opg
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
ma.L1 -0.6972 0.011 -61.924 0.000 -0.719 -0.675
ar.S.L60 -0.8867 0.120 -7.401 0.000 -1.121 -0.652
ma.S.L60 -0.1281 0.108 -1.190 0.234 -0.339 0.083
sigma2 2.619e+04 444.518 58.918 0.000 2.53e+04 2.71e+04
===================================================================================
Ljung-Box (Q): 1162.75 Jarque-Bera (JB): 10175.15
Prob(Q): 0.00 Prob(JB): 0.00
Heteroskedasticity (H): 643.10 Skew: -0.47
Prob(H) (two-sided): 0.00 Kurtosis: 22.03
===================================================================================が・・とりあえず、このまま予測します。
予測値が0以下になる場合には、0と返してくれるように指定
#予測
pred = SARIMA_df.predict("2022-01-01" ,"2022-12-31")
pred[pred < 0] = 06. データの視覚化
matplotlib.pyplotライブラリを使用して、データの可視化を行います。
実数を青で、予測値を赤で示します。
#データを折れ線グラフにする
plt.figure(figsize=(16,9))
plt.title("Number_of_infected_people_per_day_in_KOBE")
plt.xlabel("date")
plt.ylabel("Number_of_infected_people_per_day")
sxmin='2020-02-14'
sxmax='2022-12-31'
xmin = datetime.datetime.strptime(sxmin, '%Y-%m-%d')
xmax = datetime.datetime.strptime(sxmax, '%Y-%m-%d')
plt.xlim([xmin, xmax])
plt.ylim([0,3000])
plt.grid(True)
#実値は青線で、予測値は赤線で表示
plt.plot(df, color="b", label = "actual")
plt.plot(pred, color = "r", label ="predict")
plt.legend()
plt.show()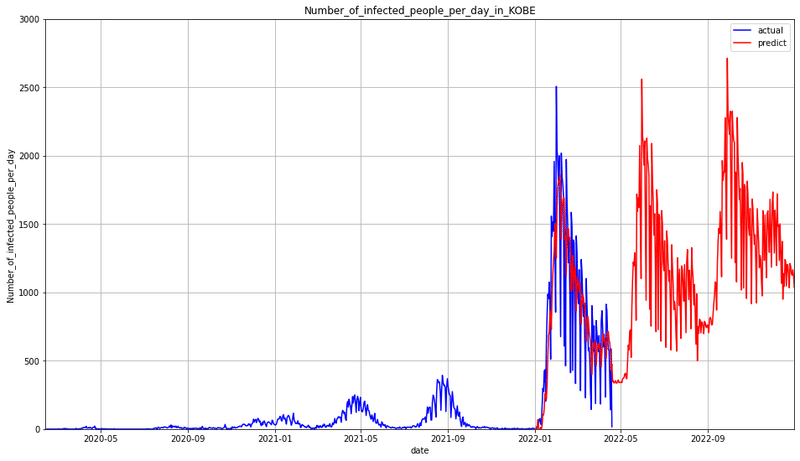
7. 結果・まとめ
この予測では、また6月ごろ、10月ごろにはピークが来る・・という結果になりました。備えなくては!
予測精度を上げていくには、気温、人の移動量、ワクチン接種状況など、もっと様々な考慮すべき情報を入れ込むべきでしょう。
また、売上などと違い、周期も極めてあいまいなデータですので、
そもそもこのモデルに当てはめること自体に限界があるのかもしれないとも思います。
以上は、自らの今後の課題としたいと思います。
さいごに
稚拙な分析にお付き合いいただきまして、ありがとうございました。
Pythonって?データ分析で何が分かるの?さえ知らなかった私に、
丁寧な指導をしてくださったAidemyのみなさんには、感謝しかないです。
データ分析という観点でいえば、世の中にあるオープンデータの多大なる可能性を想像し、ワクワクした3か月でした。人々の生活が豊かになるデータ活用法を今後は考えていきます。また、研究に活用すべく頑張ります。
この記事が気に入ったらサポートをしてみませんか?