データ分析は「根気」と「誠実性」〜標本誤差と選択バイアス〜

こんにちは、モリです。
「5分でわかる重回帰分析」という自分の勉強を纏めただけのような記事が「重回帰分析」のGoogle検索で2位になっていたり、10,000pvに迫っていたりとたくさんの方に読んでいただけています。
これは素直に嬉しいです。有難うございます。
正直に言って、今自分が読んでもわかりやすいし面白いっすね。
、、、
というのは冗談ですが、今回も統計とかデータ分析とかそんな感じの領域 で少し面白い話ができそうなので記事にしてみようと思います。
タイトルに「データ分析」とありますが、今回はデータ分析というよりはデータの解釈や向き合い方、といった雰囲気なのであしからず。
今、コロナ禍でデータを目にする機会もぐっと増えていると思うので、今一度立ち止まって、「強気にデータを見る」自信をつけましょう。
早速ですが、こちらのグラフをご覧ください。
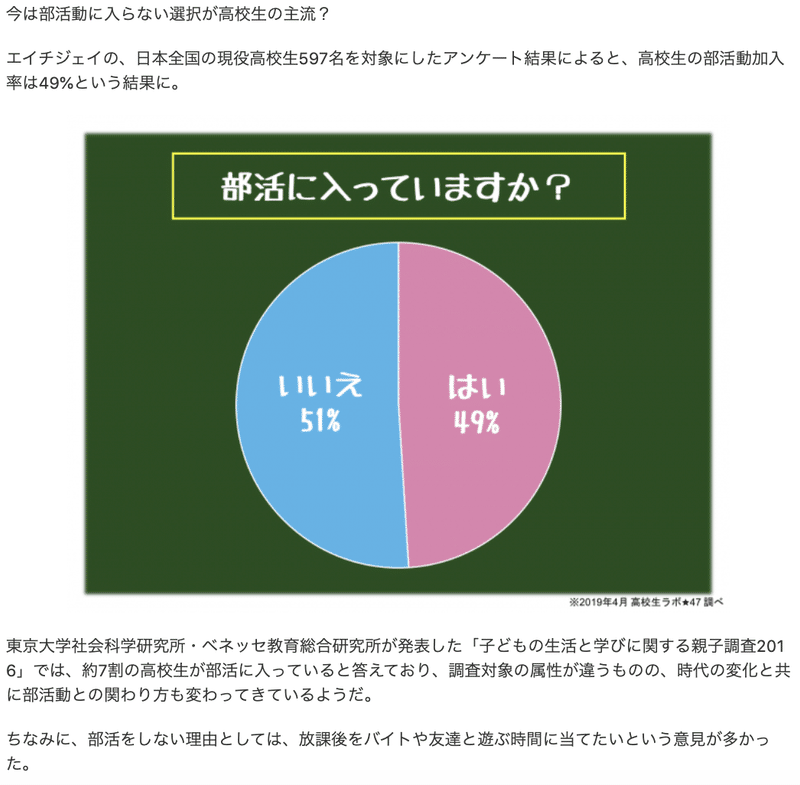
最近の高校生は部活をやってない子の方が多い、というデータですね。
実は、少し前にこのデータの解釈を巡ってネット上で議論になっていたことがあります。
これをみてあなたはどう捉えましたか?
「597人?母数すくなっ」
こう捉えたあなたは0点です。
「へぇ、今の子は部活やらないんだぁ」
とデータを鵜呑みにしたあなたの方がどちらかと言えば適切です。
どういうことか説明します。
0. 「母数」って使うのやめてよ!
まず、この場面で「母数」という言葉は使いません。
「母数」というのは「母集団のパラメータ」という意味でしかないです。
今回のような集団の大きさや分数の分母の方、みたいな意味で使われるのはまったくの誤用です。
高校生の方は大学に入ると教授に、大学生の方は会社に入ると上司に注意されることになるので今のうちに覚えておきましょう。
私は新卒1年目に得意先で注意されて切ない気持ちになりました。
なぜかこの誤用が一般にまかり通っていますが、
「母数」という言葉に正しい意味があり使用されている以上、誤用は誤用です。
この場合は
「サンプルサイズが小さい」
と言いましょう。
ちなみに「n数」という言葉も微妙です。単純にそんな言葉なくね?という感じです。
この場合は他に意味することもないので、サンプルサイズと同じ使い方をしていても個人的にはいいと思います。
サンプルサイズにnがあてられているときは
「サンプルサイズnが小さくね?」と言うと丁寧な感じがします。
いきなり脱線してしまいました。
それでは
正しい物言いで
「サンプルサイズが597は少ないでしょ」
と主張している場合はどうでしょうか。
1. 「標本誤差」の考え方
これは「高校生が300万人いるなかで600人しか調査してないの?対象が少なすぎでしょ、参考にもならん」という意見です。
気持ちはわかります。
30000人から6人抽出して、
4人が部活をしていなくて、2人が部活をしている、
と回答した時に「67%が部活してないってさ!」と主張されても
いやいや、、、一人変わるだけで17%動くやん、、、と思ってしまいます。
逆に300万人全員にアンケートを取ることができれば、その結果は100%高校生の実態を反映できていることになります。これを全数調査といいます。
国勢調査なんかはこの方法が取られています。
しかし、300万人に対してアンケート調査を行うのは現実的ではありません。
アンケート実施のコストも手間も、集計作業も莫大なものになってしまいます。
というわけで、一部の集団を抽出し、調査するわけです。これを標本調査といいます。
では、何人にアンケートをとれば安心できるのでしょうか。
10分の1の30万人ぐらいでしょうか?それとも3万人ぐらいで十分???
感覚的に考えてもイマイチはっきりしないですよね。
ここに関してきちんとはっきりさせるための考え方が存在します。
それが「標本誤差」になります。
標本誤差というのは、今回の場合
母集団の全て=300万人集めて調査した時の結果と
597人の標本を調査した結果の差
です。
つまり、もし300万人に対してアンケートを行って
「部活に入っているか→はい」が70%であれば、
597人での結果が49%なので標本誤差は21%ということになります。
しかしながら、標本誤差を実値として算出するのは困難です。
それはそうですよね。
だって、実値で算出するには300万人に対して全数調査を行う必要があります。
それができないから標本調査を行っているわけです。
と、いうことで、理論式を使ってある程度の標本誤差を推定するやり方が一般的です。
どうやって推定するのかは下記で説明しますが、アウトプットとしては
「今回の標本誤差の結果は、全数調査による真の結果に対して、
95%の確率で○○%の差である」
といった形になります。
それでは実際に標本誤差を算出してみましょう。
標本誤差は次の式で表されます。
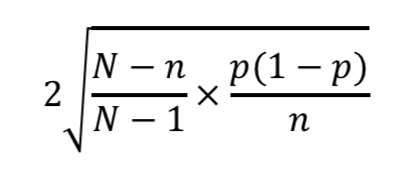
・母集団:全国の高校生
・母集団の大きさN:300万
・サンプル数:1
・サンプルサイズn:597
・部活動加入率p:0.5 (50%)
今回はpを0.5にしました。わかりやすいので。
ここで、
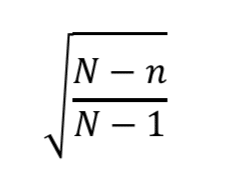
この部分に注目すると、
となりますので、1として扱うことができます。
つまり、母集団の大きさNに比べてサンプルサイズnがかなり小さいときは無視することができるというわけです。
1として扱うと元の式は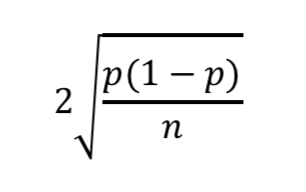
こうなります。めっちゃ簡略化されましたね。
母集団がめっちゃ大きいことがわかっているときはハナっからこっちの式で考えます。
これなら頭の中でもなんとなく標本誤差を出せるレベルです。
それでは標本誤差を算出しましょう。
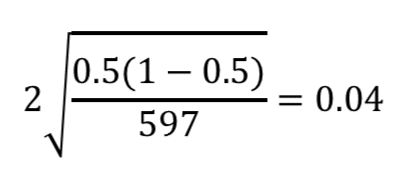
ということで標本誤差は0.04、つまり4%になりました。
つまり「高校生の部活動加入率は95%の確率で48-52%である」ということになります。
約50%、という結果が概ね正しいことがわかりました。
「サンプルサイズが597は少ないでしょ」
という意見は残念ながら的外れだったわけです。
ちなみに、100人だったら標本誤差は20%なので、
「40-60%である確率が95%」
みたいな結果になります。
これでもそこまで悪くはないですね。
ただ、これでこのデータに対する解釈はまだ終わりではありません。
597人を抽出することは調査上、妥当な方法であることがわかりました。
しかし、その597人の選び方をしっかりと見定めなくてはいけません。
2. 標本選択バイアス
今回、この調査が正しいと言い切ることができるのは、
597人が無作為に抽出されている
場合のみです。
無作為、というのはランダムに、適当に、という意味ではありません。
全体の集団をなるべく再現できるように特性の散らばった597人を選ぶ、ということです。
例えば、この調査を高校3年生597人に行った場合どうでしょうか。
もし、調査期間が秋-冬とかであれば部活を引退している子がほとんどでしょう。
この597人の調査結果をもとに
「今の高校生は95%が部活動をやっていない!」
と主張されても明らかにおかしいですね。
これが標本選択バイアスです。
今回も標本にバイアスがないか調べなくてはいけません。
![]()
ソースはここみたいなので、見に行きましょう。
見つけました。
んー、、、なんかインフルエンサーとかモデルの卵みたいな方を集めて調査結果出したり、記事出したりしてる団体なのかな、、、。
個人のプロフィール見れますね。SNSも覗ける。フォロワー数千人、みたいな子もいますね。
(完全にネットストーカーですが、データを正しく解釈するにはとにかく多角的に情報を集めないといけません。)
47都道府県から集まっているので地域は分散できていそうです。
今は男子の方しか見れないけど、人数的にもサイトの構成的にも、半分は女子がいるっぽいですね。
やはり、問題になるのは芸能系を志す子達を抽出してそうなところです。
こういう属性の子達ってあんまり部活やってなさそうじゃないですか?
ここでもう一つ当グループが出してくれている結果を見てみましょう。

1位から軽音部、ダンス部、演劇部と並んでいます。
(円グラフで出すとか、せめてパーセンテージ添えるとかしてほしいけどここは目を瞑ります)
文部科学省のデータでは2018年の男子の最も部活加入人数が多かったのはサッカーだったはずです。
(こちらも本当は正しく精査してどのぐらい妥当性があるデータなのか検討が必要ですが、割愛します。文部科学省なので、ある程度は信頼していいはずです)
男子が半数いるので、サッカーが上位に上がってこないのはおかしいです。
そして、軽音部、ダンス部、演劇部、と、いかにも芸能系の子達が好みそうな部活が上位に上がっていることより、かなりバイアスのかかった標本であると判断することにしました。
つまり私の判断としては
特定の597人の調査結果ではあるが、全国の高校生の状況を反映しているとは捉えられない。
ということです。
これで、私の考える今回のデータの解釈は以上にします。
3.最後に
今回はケーススタディのような形で進めましたが、
別にこのデータを批判しようとか、そういう意図は全くありません。
ただ、データを解釈する、というのはこういうことである、という私の哲学みたいな部分を知って欲しかったんです。
現在の情勢を見ていると、データが飛び交い、誰でもない人が好き勝手な解釈で空中戦を展開して、何が正しくて何が間違っているのかもわからなくなっていることかと思います。
データを扱うということはその解釈も分析も、整理の仕方も、
誠実性、根気、粘着質、知識、スキル
、
などなどが必要です。
簡単、適当な解釈で、誰かを批判したりするようなことはあってはいけません。
自分の都合のいいように解釈するなんてもってのほかです。
公平性のない誠実性にかける行為です。
撃っていいのは撃たれる覚悟がある奴だけだ、です。
こういう論拠で、こういう解釈で、自分のスタンスはここにあって、批判することで実現したいのはこういうことです。
ここまで自信が持てるようになった時に、初めて議論の壇上に登る方が、あらゆる面で生産的かと思います。
データに振り回さることなく、誠実に、強気でデータと向き合うには
かなりの根気が必要ですが、
「自分はこう思うんだ!」
と自信をもって生きましょう!
それでは、また。
この記事が気に入ったらサポートをしてみませんか?