5分でわかる重回帰分析 基礎編

こんにちは、森です。
私は昨年までメーカーで営業しており、現在はベンチャー企業でマーケティングに関わる業務をしています。
前職でも現職でもデータ分析が必要になることが多く、その中でも今回紹介する重回帰分析をよく行っています。
現職では同僚も普通に行っていますが、前職ではそこまで込み入った分析をしている方に出会うことができず、独学で習得せざるを得ない状況で、なかなか時間がかかりました。
そこで、私が今、誰かに重回帰分析のやり方を教えるなら、という視点で簡単に説明してみたいと思います。
私はデータサイエンティストでもその道の専門家でもないので、理論的な部分でわかっていないこともありますが、
まずは「とりあえず使えるようになる」ところをゴールとして説明していきます。
まずは私が適当に作成した下の表をご覧ください。
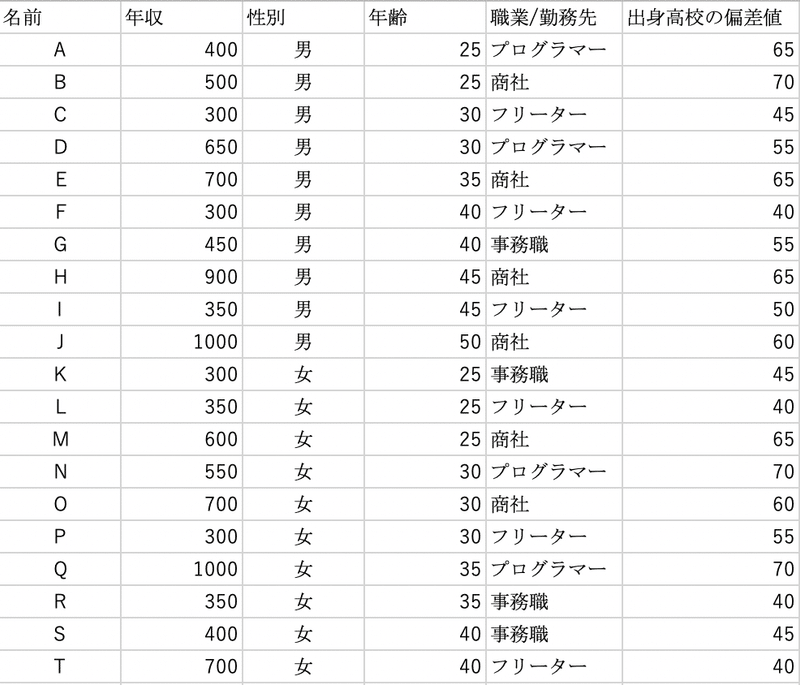
20人の名前、年収、性別、年齢、職業、出身高校の偏差値がまとめられています。(本当に適当なので、特別な意図はないです)
今回は重回帰分析を用いて、「年収予測モデル」を作成してみることにします。
つまり、「性別と年齢、職業、出身高校の偏差値がわかれば、年収が導き出せるモデルを作る」ということです。
最終的には「26歳、男、プログラマー、出身高校の偏差値65」の予測年収を導き出してみましょう。
簡単な理論の解説→Excel上での実際の操作→データの解釈方法
の順序で説明していきます。
0. 重回帰分析について
まず上記の表で、「年齢と年収に相関関係があるか」確認してみましょう。
Excel上で散布図の作成を行い、線形近似を行ったのが下記のグラフになります。
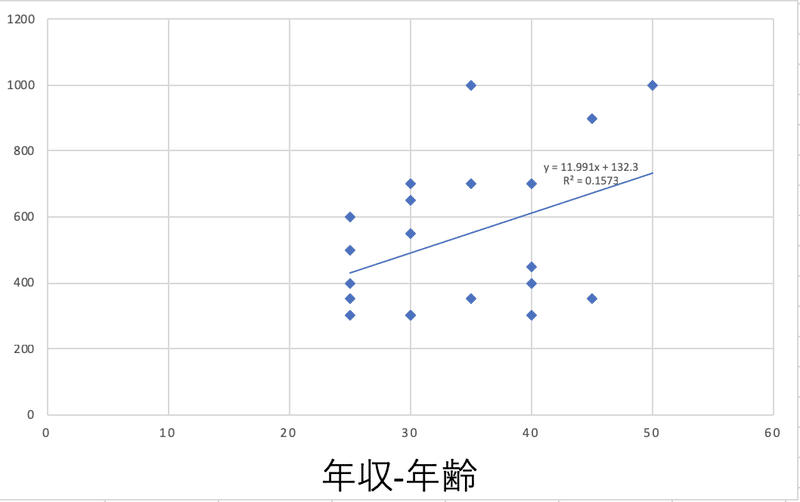
y=11.991x+132.3
という近似曲線が得られているので、xに年齢を代入して式を処理すると
yに年収が得られるモデルになります。
そしてこの時、
x:説明変数
y:目的変数
と呼びます。yを目的としたモデルを説明しているのがxという意味合いですね。
また、R^2=0.1573 となっていますが、このRは決定係数と呼ばれるもので、大雑把にいうと、この近似直線がどれだけ各プロットに近いか、を表しています。
R=1 の時、直線はぴったりプロット上を走っています。
つまり、1に近い方がモデルとして正確であることを表しています。
一般的にはR^2=0.7以上だとモデルとして信用できると判断されることが多いです。
なので、今回のR^2=0.1573 はモデルとしては正直イマイチですね。
パッとみても直線から離れたところにプロットが散らばっているのがわかります。
この例のような説明変数が1つのみで直線近似を使って行った分析を
「単回帰分析」
と言います。一般化すると
y=ax+b (y:目的変数、x:説明変数、a, b:定数)
です。
重回帰分析はこの単回帰分析で行ったことを複数の説明変数で行うことになります。
y=a*x1+b*x2+c*x3+d*x4+e
(x1:性別, x2:年齢, x3:職業/勤務先, x4:出身高校の偏差値, a,b,c,d=係数,e=定数)
このモデルを作りたいわけです。しかしながら、説明変数が複数あるので、上記の単回帰分析の例のように、近似曲線を引いて定数を求めることができません。
そこで行うのが重回帰分析になります。
もちろん、コツコツ計算してモデルを作成することも可能ですが、ここではExcelに計算してもらいます。
ちなみにここまで私が使ってきている「重回帰分析」という単語ですが、実は言葉の定義上、上記の年収予測モデルの場合、正確ではないと言われてしまうかもしれません。
多変量解析においては
・目的変数が量的変数、説明変数が量的変数→重回帰分析
・目的変数が量的変数、説明変数が質的変数→数量化Ⅰ類
・目的変数が質的変数、説明変数が量的変数→ロジスティック回帰分析
・目的変数が質的変数、説明変数が質的変数→数量化Ⅱ類
というように、考え方と分析方法がその目的と手段によって異なっています。
(量的変数は年収や年齢のように数値化できるもの、質的変数は性別や職種のように数値化できないもの)
しかしながら、説明変数に質的変数が混ざっていた場合でも質的変数を「ダミー変数」としてしまうことで重回帰分析と同様の解析を行うことが可能です。
今回のように年齢や職種などの質的変数が説明変数に混ざっている場合には数量化I類なのか重回帰分析なのか言葉の定義的にはよくわかりませんが、とりあえず重回帰分析を行えるので、そういうことで進めていきます。
ロジスティック回帰分析に関してはそもそも出来上がるモデルの形が重回帰分析とは異なりますので、応用編でご紹介します。(結構面倒ですが、成約率や合格率、などを求めるモデルに有用です。)
(応用編、公開いたしました)
説明が長くなりましたが、実際に重回帰分析、やっていきましょう!
1. Excelで重回帰分析を行う
まずは上記のリストを下表のように加工します。
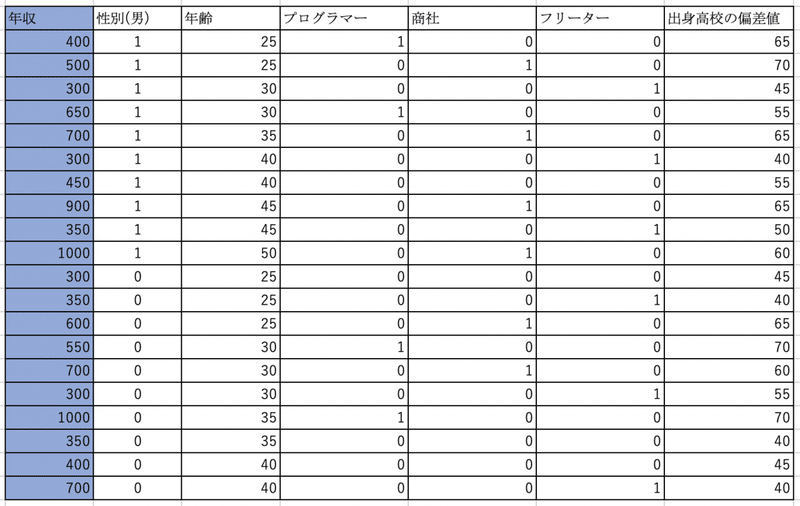
年収、年齢、出身高校の偏差値の項目は特に手を加えていません。
性別、職種について、先ほど出てきた「ダミー変数」を用いています。
性別を例に説明しますと、「男であれば1とする列」と「女であれば1とする列」をそれぞれ作成します。
イメージがつきづらければ、男度合いを0-1の変数、女度合いを0-1の変数と無理やり設定していると解釈してください。当然、男は男度合いが1で、女度合いは0になります。逆も同様です。
ですが、上記の表には男の列しかありませんよね。これには理由があります。
男列が1の場合、女列には必ず0が入ります。このように他の変数によって確実に決まる変数が入っている必要は全くありません。
この後行うExcelの操作でもバグの原因になります。
そのような理由から女の列は作成していません。
同様に職種についても「事務職」は「プログラマー」「商社」「フリーター」の3つを参照すれば決定しますので、作成していません。
操作上、「そのカテゴリーに属している種類-1の列を作成すればOK」と覚えていただければ問題ありません。
性別は2種類ですので1列、職種は4種類ですので3列です。
これで下準備は完了です。
重回帰分析を行ってみましょう。
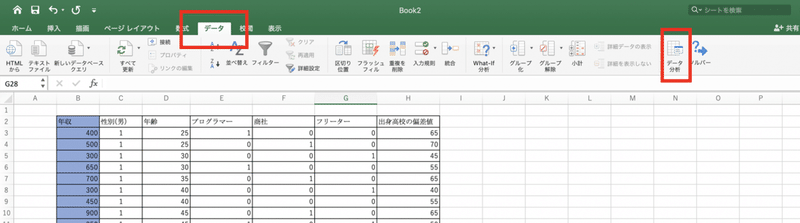
まず、「データ」タブ→「データ分析」と進みます。
もし「データ分析」がなさそうだったら、Excelアドインの設定からONにしてください。
「回帰分析」を選んで「OK」
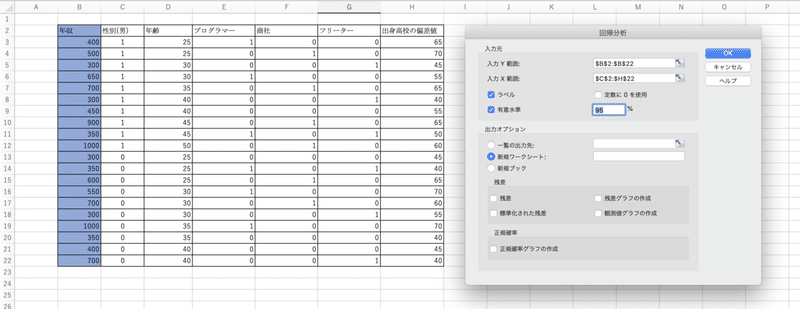
「入力Y範囲」:目的変数(今回だと年収の列)
「入力X範囲」:説明変数(年齢-出身高校の偏差値の列)
ラベルとか有意水準とかはお好みでいいと思います。定数に0を使用するかどうかは、目的とするモデルによりますが、今回は0にしません。
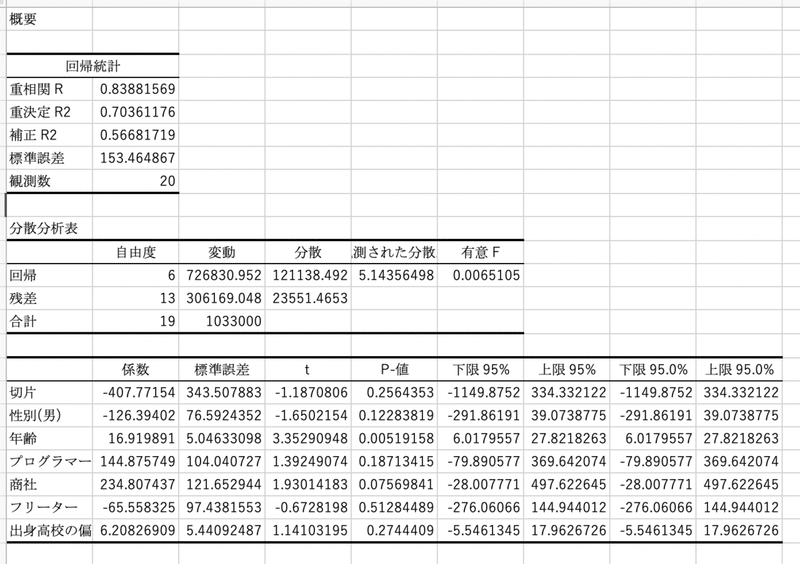
実行するとこのような結果が自動で吐き出されてきます。
とはいっても、これだけ見てもどういうことだかわからないと思いますので、説明します。
2. 重回帰分析結果の解釈
まず、肝心要のモデルに使う係数から見てみましょう。
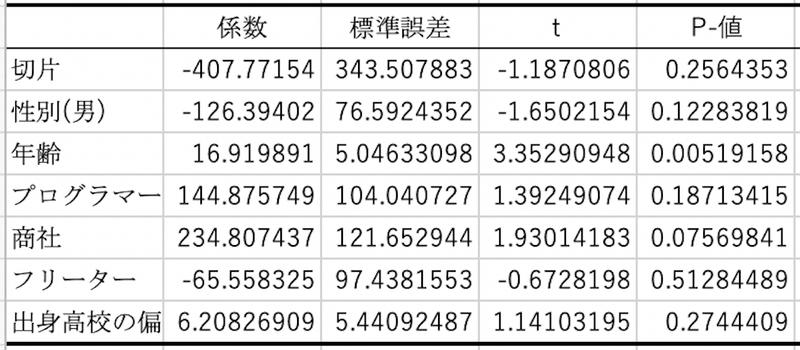
「係数」の項目がまさにそれぞれの項目の係数を表しています。切片は式の最後の定数項になります。求められた結果を用いてモデルを表現してみます。
y=-126x1+16.9x2+145x3+235x4-65.6x5+6.21x6-408
x1:男であれば1、女であれば0
x2:年齢
x3:プログラマーであれば1, それ以外の職業なら0
x4:商社であれば1,それ以外の職業なら0
x5:フリーターであれば1,それ以外の職業なら0
(事務職であればx3-x5には全て0が入る)
x6:出身高校の偏差値
上表の「t」は「その要素がこのモデルにどれだけ影響を及ぼしているか」
を表しています。絶対値が大きいほどモデルにとって重要な要素です。正の値であれば目的変数に正の影響を、負の値であれば負の影響を及ぼしています。
tが最も大きいのは「年齢」ですのでこのモデルにおいては年齢が一番効いている要素であることがわかります。
p-値は超ざっくりいうと「出てきた結果が偶然かどうか」を検討していて、小さいほど偶然性が低いと解釈することが可能で、慣習的に0.05を下回ると良しとされています。年齢、商社かどうか、はこの偶然性がかなり低い要素と言えます。
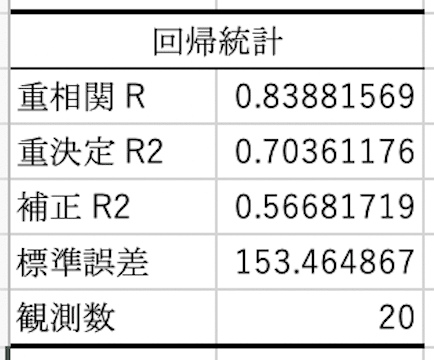
最後に、「重決定R2」について。これは単回帰分析で説明した決定係数Rの2乘値になります。0.7を超えてくるとモデルとして使える、とされていますので、今回作成されたモデルは結構いい線をいっていることになります。
それでは、目標としていた「26歳、男、プログラマー、出身高校の偏差値65」の年収を予測してみましょう。
代入するだけです。
454.05=-126*1+16.9*26+145*1+235*0-66*0+6.21*65-408
ということで約454.05万円であると算出することができます。
もちろんこの結果は私が適当に作ったリストから出来上がったモデルから算出されているので、だからどうだって話ですが、重回帰分析ができるようになるとデータ分析が格段に捗りますので、どうぞご活用ください。
モデルが綺麗に出来上がるとめっちゃ気持ちいいです。
次回は応用編として、ロジスティック回帰分析を用いて「初体験が18歳以下である確率」を判定するモデルを作成してみたいと思います。
(応用編、公開いたしました)
それでは、また。
この記事が気に入ったらサポートをしてみませんか?