
Photo by
voice_watanabe
ChatGPTプラグイン「Code Interpreter」はAIの民主化だ!

2023年7月7日、ChatGPTのGPT-4のpluginで「Code interpreter」機能が使えるようになりました。
この機能AIの民主化がすでに始まってます。
例えば、予測エンジンやレコメンド等の機能がエンジニア以外でも簡単に実装、チェックができる様になります。
詳しく見ていきます。
以前書いたこの記事も参考にして下さい
今回は、ドル円の予想を「Code Interpreter」でやってみました。
過去実績のCSVファイルをダウンロード
https://sec.himawari-group.co.jp/report/chart/
このサイトからCSVを取得しました。
ファイルをアップロード
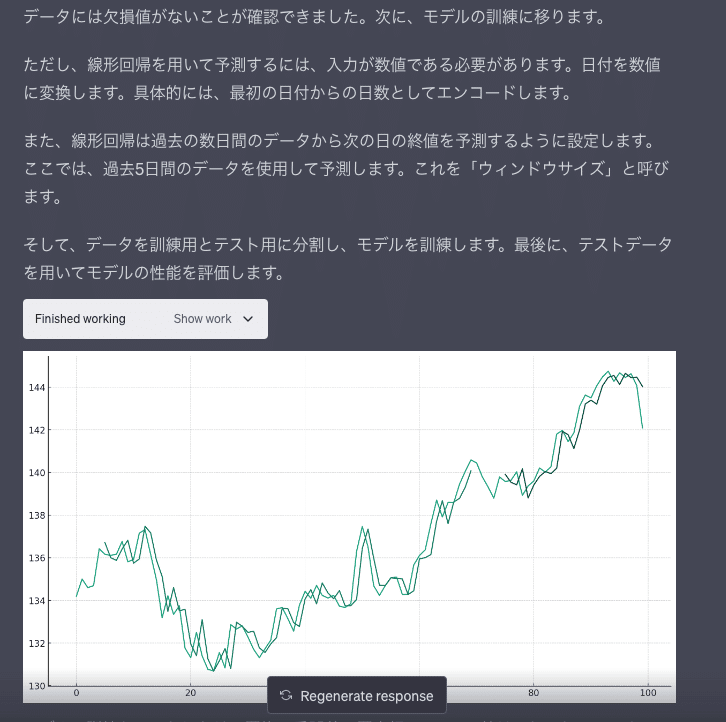
このCSVは日別のドル円の推移データです。次のドル円を予想して下さい。

実行結果
こんな感じで実行されます。

ファイルのエンコーディングも判断して調整してくれます。最高じゃないですか!?
深層学習もレコメンドしてくれる
# Import necessary libraries
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
import numpy as np
from matplotlib import pyplot as plt
# Convert date column from string to datetime
df['日付'] = pd.to_datetime(df['日付'], format='%Y年%m月%d日')
# Sort dataframe by date
df.sort_values('日付', inplace=True)
# Reset index after sorting
df.reset_index(drop=True, inplace=True)
# Check if there are any missing values
missing_values = df.isnull().sum()
# Display missing values
missing_values
# Define a function to create input/output data
def create_dataset(dataset, window_size=1):
data_X, data_Y = [], []
for i in range(len(dataset) - window_size):
a = dataset[i:(i + window_size)]
data_X.append(a)
data_Y.append(dataset[i + window_size])
return(np.array(data_X), np.array(data_Y))
# Set random seed for reproducibility
np.random.seed(7)
# Define the window size
window_size = 5
# Convert the dataframe to a numpy array and get the number of training days
dataset = df['終値'].values
training_days = int(len(dataset)*0.7) # 70% of data for training
# Split the data into training data and test data
train, test = dataset[0:training_days], dataset[training_days:len(dataset)]
# Create the training data
train_X, train_Y = create_dataset(train, window_size)
# Create the test data
test_X, test_Y = create_dataset(test, window_size)
# Reshape input to be [samples, window size, features]
train_X = np.reshape(train_X, (train_X.shape[0], 1, train_X.shape[1]))
test_X = np.reshape(test_X, (test_X.shape[0], 1, test_X.shape[1]))
# Train the model
model = LinearRegression()
model.fit(np.squeeze(train_X), train_Y)
# Make predictions
train_predict = model.predict(np.squeeze(train_X))
test_predict = model.predict(np.squeeze(test_X))
# Calculate root mean squared error
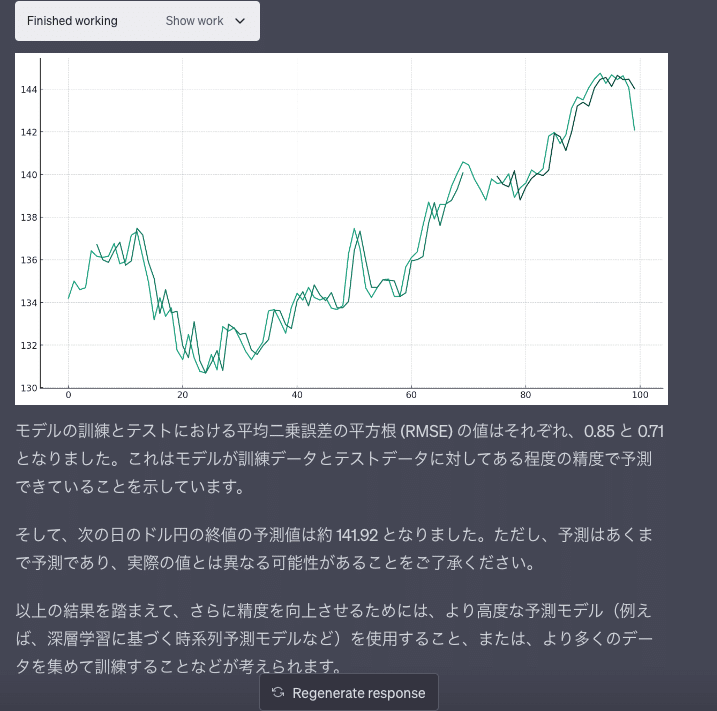
train_score = np.sqrt(mean_squared_error(train_Y, train_predict))
print(f'Train Score: {train_score:.2f} RMSE')
test_score = np.sqrt(mean_squared_error(test_Y, test_predict))
print(f'Test Score: {test_score:.2f} RMSE')
# Shift train predictions for plotting
train_predict_plot = np.empty_like(dataset)
train_predict_plot[:] = np.nan
train_predict_plot[window_size:len(train_predict)+window_size] = train_predict
# Shift test predictions for plotting
test_predict_plot = np.empty_like(dataset)
test_predict_plot[:] = np.nan
test_predict_plot[len(train_predict)+(window_size*2):len(dataset)] = test_predict
# Plot baseline and predictions
plt.figure(figsize=(15, 8))
plt.plot(dataset)
plt.plot(train_predict_plot)
plt.plot(test_predict_plot)
plt.show()
# Predict the next day's closing price
last_window = dataset[-window_size:]
next_day_price = model.predict(last_window.reshape(1, -1))
next_day_price
深層学習も
深層学習に基づく時系列予測モデルで予想お願いします

# Import necessary libraries
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from sklearn.preprocessing import MinMaxScaler
# Normalize the dataset
scaler = MinMaxScaler(feature_range=(0, 1))
dataset = scaler.fit_transform(dataset.reshape(-1, 1))
# Split the data into training data and test data
train, test = dataset[0:training_days,:], dataset[training_days:len(dataset),:]
# Create the training data
train_X, train_Y = create_dataset(train, window_size)
# Create the test data
test_X, test_Y = create_dataset(test, window_size)
# Reshape input to be [samples, time steps, features]
train_X = np.reshape(train_X, (train_X.shape[0], 1, train_X.shape[1]))
test_X = np.reshape(test_X, (test_X.shape[0], 1, test_X.shape[1]))
# Create and fit the LSTM network
model = Sequential()
model.add(LSTM(4, input_shape=(1, window_size)))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
model.fit(train_X, train_Y, epochs=20, batch_size=1, verbose=2)
# Make predictions
train_predict = model.predict(train_X)
test_predict = model.predict(test_X)
# Invert predictions
train_predict = scaler.inverse_transform(train_predict)
train_Y = scaler.inverse_transform([train_Y])
test_predict = scaler.inverse_transform(test_predict)
test_Y = scaler.inverse_transform([test_Y])
# Calculate root mean squared error
train_score = np.sqrt(mean_squared_error(train_Y[0], train_predict[:,0]))
print(f'Train Score: {train_score:.2f} RMSE')
test_score = np.sqrt(mean_squared_error(test_Y[0], test_predict[:,0]))
print(f'Test Score: {test_score:.2f} RMSE')
# Shift train predictions for plotting
train_predict_plot = np.empty_like(dataset)
train_predict_plot[:] = np.nan
train_predict_plot[window_size:len(train_predict)+window_size] = train_predict
# Shift test predictions for plotting
test_predict_plot = np.empty_like(dataset)
test_predict_plot[:] = np.nan
test_predict_plot[len(train_predict)+(window_size*2):len(dataset)] = test_predict
# Plot baseline and predictions
plt.figure(figsize=(15, 8))
plt.plot(scaler.inverse_transform(dataset))
plt.plot(train_predict_plot)
plt.plot(test_predict_plot)
plt.show()
# Predict the next day's closing price
last_window = scaler.transform(df['終値'].values[-window_size:].reshape(-1, 1))
next_day_price = model.predict(last_window.reshape(1, 1, window_size))
# Invert the prediction
next_day_price = scaler.inverse_transform(next_day_price)
next_day_price
残念ながら環境にtensorflowが入ってないのでエラーになりました。
----> 2 from keras.models import Sequential
3 from keras.layers import Dense
4 from keras.layers import LSTM
File ~/.local/lib/python3.8/site-packages/keras/__init__.py:21
15 """Implementation of the Keras API, the high-level API of TensorFlow.
16
17 Detailed documentation and user guides are available at
18 [keras.io](https://keras.io).
19 """
20 # pylint: disable=unused-import
---> 21 from tensorflow.python import tf2
22 from keras import distribute
24 # See b/110718070#comment18 for more details about this import.
ModuleNotFoundError: No module named 'tensorflow'
他の分析手法はありますか?

色々な分析手法を提案してくれます。
先程、TensorFlowが入ってなくて動きませんでしたが、入れて動かすことはできますか?
入れる事は出来ない様です。

まとめ
こんな感じで誰でもAIを試すことが可能です。TensorFlow等の深層学習も試せれば更に色々と出来そうです。
普段AIにふれた事のない人達も触れて、色々と試して欲しいと思います。
最後に
エンジニアの皆さん、エンジニア未経験の皆さん、若手エンジニアの皆さん、勉強方法について悩みがあればなんでも気軽に質問して下さい!
これからも記事を書いていきますので、モチベーションアップのためフォロー、イイねお願いします。
この記事が気に入ったらサポートをしてみませんか?